









目录
要知道两种sql的区别,先要知道什么是hive,什么是spark
一、什么是hive,什么是spark
(一)hive
百度百科上的定义:hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
1、hive在hadoop中的角色
| 定语 | 角色 | 作用 | 优点 |
|---|---|---|---|
| 基于Hadoop的数仓工具 | 查询引擎 | 可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转化为MapReduce任务进行运行 | 学习成本低,可以通过类sql语句执行统计,不必开发专门的MapReduce应用 |
| 建立于Hadoop上的数据仓库基础架构 | 数据仓库 | 它提供了一系列工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制,它定义了类SQL语言HQL,允许熟悉SQL的用户查询数据 | 简化了查询分析工作 |
| – | – | – | – |
2、hive和关系型数据库的区别
| hive | 关系型数据库 | |
|---|---|---|
| 存储系统 | HDFS | 服务器本地的文件系统 |
| 计算模型 | mapreduce | 关系型数据库自己设计的计算模型 |
| 设计初衷 | 海量数据做数据挖掘 | 实时查询 |
| 实时性 | 实时性差 | 就是为实时查询而生的 |
| 扩展性 | 和hadoop一样,计算能力和存储能力扩展方便 | 相对差很多 |
3、hive 架构及执行流程介绍
hive架构图
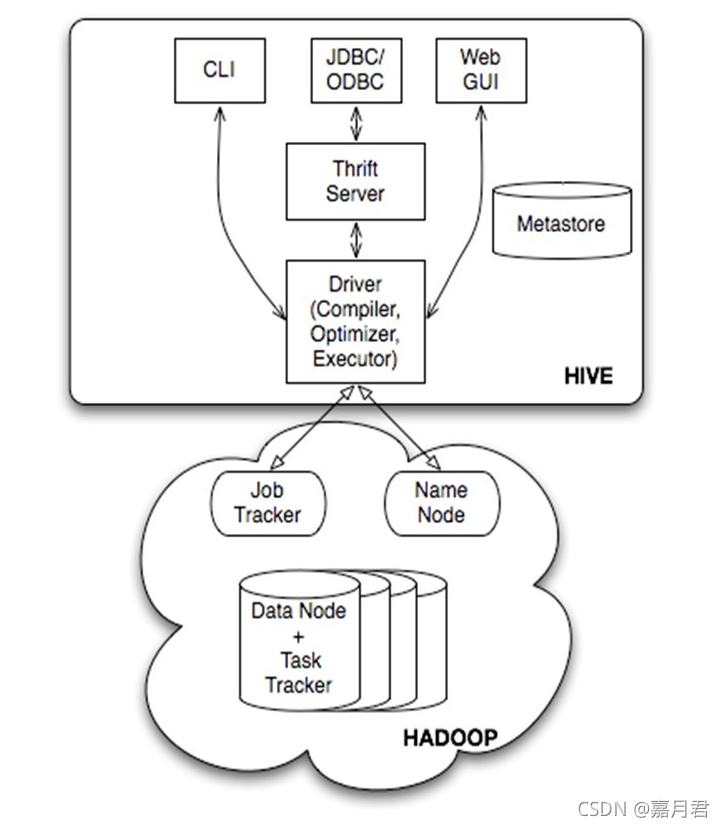
hive基于大数据底座hadoop
| 类型 | 组件 | 作用 | 备注 |
|---|---|---|---|
| 客户端 | CLI | 终端命令执行接口 | |
| 客户端 | Thrift客户端 | 包含JDBC/ODBC在内的诸多连接方式均建立在thrift客户端之上 | |
| 客户端 | WEB GUI | 提供了一种通过网页的方式访问hive的途径,接口对应hwi(hive web interface),需要提前启动hwi服务 | |
| 服务端 | Driver | 组件包含Complier、Optimizer、Executor,负责将hql进行编译,优化生成执行计划,而后调用mapreduce进行计算执行 | |
| 服务端 | MetaStore | 元数据服务组件,负责存储hive的元数据,因为元数据的重要性,hive支持把metastore服务独立出来,安装到远程的服务器集群中,从而解耦hive和metastore,保证hive运行的健壮性 | |
| 服务端 | Thrift | facebook开发的软件框架,用来进行可扩展且跨语言的服务开发,hive集成了该服务,能让不同的开发语言调用hive接口 |
hive sql执行流程图
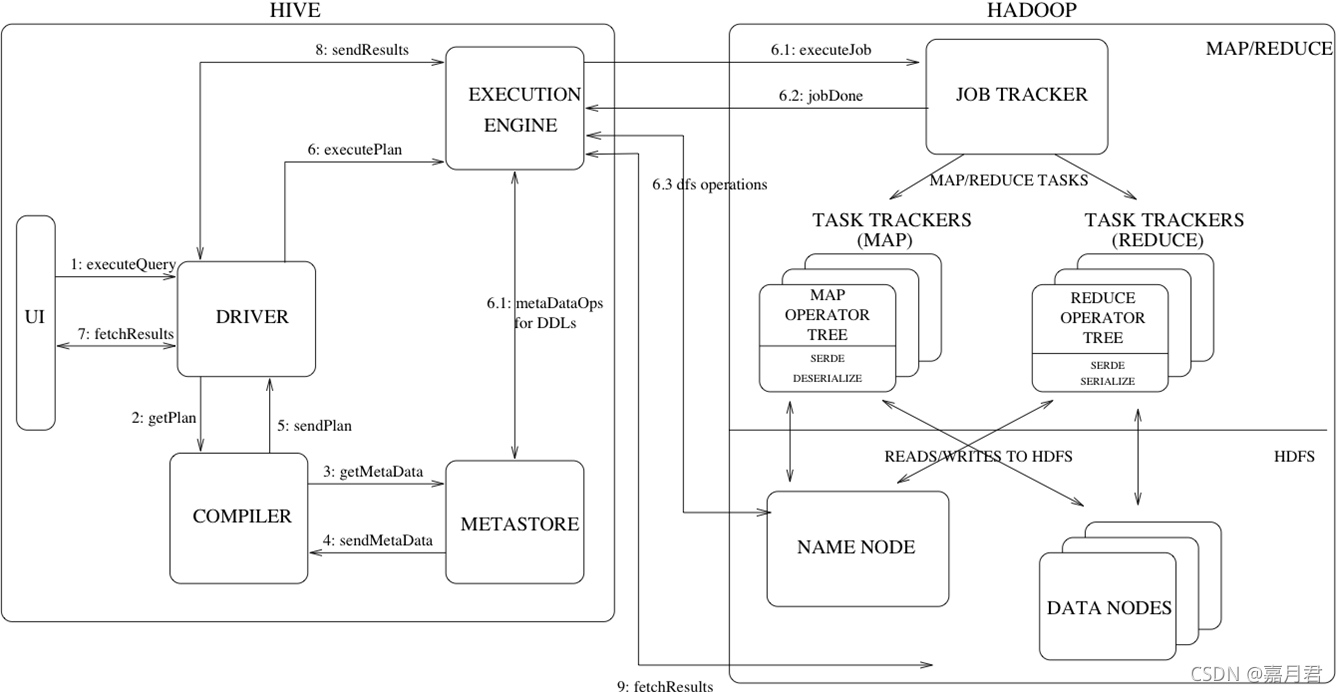
(二)spark
百度百科上的定义:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
1、spark组件介绍
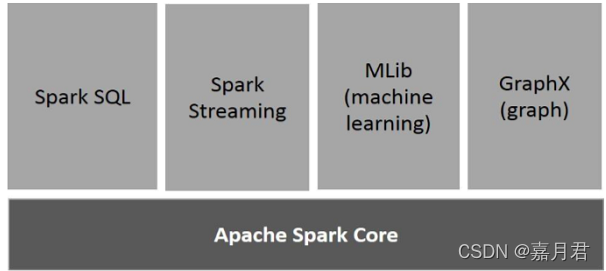
| 组件 | 定义 | 备注 |
|---|---|---|
| Apache Spark核心 | Spark Core是Spark平台的基础通用执行引擎,Spark所有其他功能都基于该核心执行。它提供了内存计算及外部存储系统中的参考数据集。 | |
| Spark SQL | 引入了一种名为SchemaRDD的新数据抽象,提供了对结构化和半结构化数据的支持。 | |
| Spark Streaming | Spark Streaming利用Spark Core的快速调度功能来执行流式分析。它以小批量采集数据,并对这些小批量数据执行RDD(弹性分布式数据集)转换。 | 官方文档中成为微批处理,最小时间间隔为0.5是s |
| MLlib(机器学习库) | MLlib是Spark上面的分布式机器学习框架,根据基准测试,由MLlib开发人员针对交替最小二乘(ALS)实现完成。 | |
| GraphX | GraphX是Spark顶部的分布式图形处理框架。它提供了一个用于表达图形计算的API,可以使用Pregel抽象API对用户定义的图形进行建模。它还为此抽象提供了优化的运行时。 |
2、spark 和 mapreduce对比
需要说明的是,spark的主要实现目的就是优化mapreduce 执行,目前来看它做到了,实现原理可以说都是基于google的那篇Google-MapReduce的论文。
| 对比方面\计算引擎 | spark | mapreduce | 备注 |
|---|---|---|---|
| 计算方式 | 内存计算 | IO读写 | 迭代计算过程中,MR需要不断IO,而spark引入了RDD+DAG,使计算过程基于内存完成,提升了处理性能 |
| 任务调度 | task为线程级别 | task为进程级别 | spark可以通过复用线程池中的线程减少启动、关闭task所需要的消耗 |
| 执行策略 | Spark在shuffle时只有部分场景才需要排序,支持基于Hash的分布式聚合,更加省时 | MapReduce在shuffle前需要花费大量时间进行排序 |
3、spark sql 执行
在spark之前databricks公司还推出过spark的上一代产品 shark ,实现了内存计算模型,相对于hive实现了上百倍的性能提升,但是由于其对于hive的过度依赖(主要是sql执行过程中的解析器,优化器等),最终被放弃。
spark 通过Catalyst模块实现了解析器、执行计划生成、优化器功能,完全脱离了对hive的依赖。
二、hive sql 和 spark sql 的对比
sql生成mapreduce程序必要的过程:解析(Parser)、优化(Optimizer)、执行(Execution)
| hive sql | spark sql | 备注 | |
|---|---|---|---|
| 解析/优化/执行 | hive自有程序 | spark自有程序,主要是catalyst | 虽然hive sql spark sql 语法上和执行上看起来差别不大,但是因为spark 的提效目的,其实优化器中做了许多优化 |
| 计算引擎 | hadoop集群中默认是mapreduce | 默认是spark | hive sql可以通过配置更改其计算引擎 |
catalyst的主要优化点
1、谓词下推
sql 语句
select a.*,b.* from
tb1 a join tb2 b
on a.id = b.id
where a.c1 > 20 and b.c2< 100
会被优化为
select a.*,b.* from
(select * from tb1 where c1>20) a
join
(select * from tb2 where c2<100) b
on a.id = b.id
减少后期执行过程中的join的shuffle数据量;
2、列裁剪
sql语句
select a.name,b.salary from
(select * from tb1 where c1>20) a
join
(select * from tb2 where c2<100) b
on a.id = b.id
会被优化为
select a.name,b.salary from
(select id,name from tb1 where c1>20) a
join
(select id,salary from tb2 where c2<100) b
on a.id = b.id
执行前将不需要的列裁剪掉,减少数据量获取;
3、常量累加
sql语句
select 1+1 as cnt from tb
会被优化为
select 2 as cnt from tb
三、其他补充
日常使用中发现的差异,窗口函数中hive sql 若没有可以不用填写partition by order by ,会默认不指定执行,但是spark sql 中不支持,必须填写完整才能执行,示例
/*获取数据行号*/
select row_number() over() rownum from tb1;
/*获取数据行号*/
select row_number() over(partition by 1 order by 1) rownum from tb1;
如上两种写法,在hive中都可以正常运行,并且正确得到表的行号,而spark只支持下面那种写法。
参考文档:
Apache Spark简介:https://www.codingdict.com/article/8118
Hive计算引擎:https://mp.weixin.qq.com/s/5-64YPCA8pMopjkW3cQdPg
详解Spark SQL:https://mp.weixin.qq.com/s/uMZIoomS0DocGGEvMt-Exw

















 3379
3379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









