






系统参数:
MySQL [(none)]> show variables like "%%";
+----------------------------------------------+---------------------------+
| Variable_name | Value |
+----------------------------------------------+---------------------------+
| SQL_AUTO_IS_NULL | false |
| auto_increment_increment | 1 |
| autocommit | true |
| broadcast_row_limit | 15000000 |
| cbo_cte_reuse | true |
| cbo_enable_low_cardinality_optimize | true |
| cbo_max_reorder_node_use_dp | 10 |
| cbo_max_reorder_node_use_exhaustive | 4 |
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_results | utf8 |
| character_set_server | utf8 |
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8_general_ci |
| count_distinct_column_buckets | 1024 |
| default_rowset_type | alpha |
| disable_colocate_join | false |
| disable_join_reorder | false |
| disable_streaming_preaggregations | false |
| div_precision_increment | 4 |
| enable_adaptive_sink_dop | true |
| enable_deliver_batch_fragments | true |
| enable_distinct_column_bucketization | true |
| enable_filter_unused_columns_in_scan_stage | true |
| enable_global_runtime_filter | true |
| enable_groupby_use_output_alias | false |
| enable_hive_column_stats | true |
| enable_insert_strict | true |
| enable_local_shuffle_agg | true |
| enable_materialized_view_rewrite | true |
| enable_materialized_view_union_rewrite | true |
| enable_multicolumn_global_runtime_filter | false |
| enable_mv_planner | false |
| enable_pipeline_engine | true |
| enable_pipeline_query_statistic | true |
| enable_populate_block_cache | true |
| enable_predicate_reorder | false |
| enable_profile | false |
| enable_prune_complex_types | true |
| enable_query_cache | false |
| enable_query_dump | false |
| enable_query_queue_load | false |
| enable_query_queue_select | false |
| enable_query_queue_statistic | false |
| enable_realtime_mv | false |
| enable_resource_group | true |
| enable_rewrite_groupingsets_to_union_all | false |
| enable_rule_based_materialized_view_rewrite | true |
| enable_scan_block_cache | false |
| enable_shared_scan | false |
| enable_sort_aggregate | false |
| enable_tablet_internal_parallel | true |
| event_scheduler | OFF |
| exec_mem_limit | 2147483648 |
| force_schedule_local | false |
| forward_to_leader | false |
| full_sort_late_materialization | false |
| group_concat_max_len | 65535 |
| hash_join_push_down_right_table | true |
| hive_partition_stats_sample_size | 3000 |
| hudi_mor_force_jni_reader | false |
| init_connect | |
| innodb_read_only | true |
| interactive_timeout | 3600 |
| join_implementation_mode_v2 | auto |
| language | /starrocks/share/english/ |
| license | Elastic License 2.0 |
| load_mem_limit | 0 |
| load_transmission_compression_type | NO_COMPRESSION |
| lower_case_table_names | 0 |
| max_allowed_packet | 1048576 |
| max_parallel_scan_instance_num | -1 |
| max_pushdown_conditions_per_column | -1 |
| max_scan_key_num | -1 |
| nested_mv_rewrite_max_level | 3 |
| net_buffer_length | 16384 |
| net_read_timeout | 60 |
| net_write_timeout | 60 |
| new_planner_agg_stage | 0 |
| new_planner_optimize_timeout | 3000 |
| parallel_exchange_instance_num | -1 |
| parallel_fragment_exec_instance_num | 1 |
| parse_tokens_limit | 3500000 |
| performance_schema | false |
| pipeline_dop | 0 |
| pipeline_profile_level | 1 |
| prefer_compute_node | false |
| query_cache_agg_cardinality_limit | 5000000 |
| query_cache_entry_max_bytes | 4194304 |
| query_cache_entry_max_rows | 409600 |
| query_cache_force_populate | false |
| query_cache_hot_partition_num | 3 |
| query_cache_size | 1048576 |
| query_cache_type | 0 |
| query_delivery_timeout | 300 |
| query_mem_limit | 0 |
| query_queue_concurrency_limit | 0 |
| query_queue_cpu_used_permille_limit | 0 |
| query_queue_fresh_resource_usage_interval_ms | 5000 |
| query_queue_max_queued_queries | 1024 |
| query_queue_mem_used_pct_limit | 0.0 |
| query_queue_pending_timeout_second | 300 |
| query_timeout | 300 |
| resource_group | |
| runtime_filter_on_exchange_node | false |
| runtime_join_filter_push_down_limit | 1024000 |
| sql_mode | ONLY_FULL_GROUP_BY |
| sql_safe_updates | 0 |
| sql_select_limit | 9223372036854775807 |
| statistic_collect_parallel | 1 |
| storage_engine | olap |
| streaming_preaggregation_mode | auto |
| system_time_zone | Asia/Shanghai |
| time_zone | Asia/Shanghai |
| transaction_isolation | REPEATABLE-READ |
| transmission_compression_type | NO_COMPRESSION |
| transmission_encode_level | 7 |
| tx_isolation | REPEATABLE-READ |
| tx_visible_wait_timeout | 10 |
| use_compute_nodes | -1 |
| version | 5.1.0 |
| version_comment | StarRocks version 2.5.3 |
| wait_timeout | 28800 |
+----------------------------------------------+---------------------------+
125 rows in set (0.02 sec)
参数说明
SQL_AUTO_IS_NULL: 此参数通常用于MySQL兼容性。如果设置为赋值,那么在没有为新记录明确指定主键值的情况下,LAST_INSERT_ID()和mysql_insert_id()将返回0,而不是新插入行的自动增量值。默认情况下,这个参数在StarRocks中被禁用。
auto_increment_increment: 这是一个系统变量,在MySQL中,它控制自增列的增量。在StarRocks中,此参数可能有类似的用途。
autocommit: 这是一个系统变量,它决定了在每次语句执行后是否应自动提交事务。如果设置为true,那么每次执行语句后都会自动提交事务。如果设置为false,那么必须明确调用COMMIT语句才能提交事务。
broadcast_row_limit: 这是一个系统变量,用于控制当查询计划选择广播连接作为连接策略时,可以广播的最大行数。如果表的行数超过此值,将不会选择广播连接。默认15000000。
cbo_cte_reuse: 这是一个优化器标志,用于控制是否重用公共表表达式(CTE)。如果设置为true,那么在查询中,每个CTE只会计算一次,并在所有引用中重用。如果设置为false,那么每个CTE将在每个引用中重新计算。
cbo_enable_low_cardinality_optimize: 这是一个优化器标志,是否开启低基数全局字典优化。如果启用,优化器将尝试识别和优化低基数的连接和聚合。开启后,查询 STRING 列时查询速度会有 3 倍左右提升。默认值:true。
cbo_max_reorder_node_use_dp: 这是一个优化器标志,用于控制在重排序连接操作时,使用动态规划算法的最大节点数。
StarRocks 在Join 个数不超过cbo_max_reorder_node_use_dp 时,会同时保留 DP 和贪心的 Plan,且贪心算法也会保留 Cost 最小的 10 个 Plan,为后续找到“最优”分布式 Plan 提供更多的可能性。
cbo_max_reorder_node_use_exhaustive: 这是一个优化器标志,用于控制在重排序连接操作时,使用穷举算法的最大节点数。
Plan 中 Join 节点小于等于 4(可通过 session 变量 cbo_max_reorder_node_use_exhaustive 修改)个时,使用枚举的方法决定Join顺序。
# 依据 Join 节点的个数不同,我们选用不同的 Join Reorder 算法,较少时用枚举法,10 个以内 Join 节点使用 DP 和贪心算法,超过 10 个时只使用贪心算法。通过对多种算法的使用,StarRocks 可以在 Join 较少时迅速找到最优解,在 Join 较多时也能在相对较短的时间内产生效果不错的 Plan。
character_set_client:设置客户端连接的字符集。这决定了客户端发送给服务器的数据的字符集。
character_set_connection:设置连接的字符集。这决定了服务器与客户端之间交换的数据的字符集。
character_set_database:设置数据库的默认字符集。当创建新的数据库时,将使用该字符集。
character_set_results:设置结果集的字符集。这决定了服务器返回给客户端的查询结果的字符集。
character_set_server:设置服务器的默认字符集。当启动服务器时,将使用该字符集。
collation_connection:设置连接的排序规则。这决定了服务器与客户端之间交换的数据的排序规则。
collation_database:设置数据库的默认排序规则。当创建新的数据库时,将使用该排序规则。
collation_server:设置服务器的默认排序规则。当启动服务器时,将使用该排序规则。
count_distinct_column_buckets:用于控制在计算基数估计时使用的桶数。较大的桶数可以提高准确性,但会增加计算成本。
default_rowset_type:用于指定默认的行集类型。行集是StarRocks中的一种存储格式,包括了不同的压缩算法和编码方式。
全局变量,仅支持全局生效。用于设置计算节点存储引擎默认的存储格式。当前支持的存储格式包括:alpha/beta。
disable_colocate_join:用于禁用StarRocks中的共同位置连接优化。共同位置连接是一种优化技术,可以将连接操作放在相同的节点上执行,减少数据传输。
控制是否启用 Colocate Join 功能。默认为 false,表示启用该功能。true 表示禁用该功能。当该功能被禁用后,查询规划将不会尝试执行 Colocate Join。
disable_join_reorder:用于禁用StarRocks中的连接重排序优化。连接重排序可以改变连接操作的执行顺序,以提高查询性能。
disable_streaming_preaggregations:用于禁用StarRocks中的流式预聚合优化。流式预聚合可以在数据流入时进行部分聚合操作,减少后续计算的数据量。
div_precision_increment:用于指定除法运算的精度增量。较小的增量可以提高计算精度,但会增加计算成本。
enable_adaptive_sink_dop:用于启用StarRocks中的自适应下推并行度优化。自适应下推并行度可以根据数据量和计算资源自动调整并行度,提高查询性能。
enable_deliver_batch_fragments:用于启用StarRocks中的批量传输片段优化。批量传输片段可以减少网络传输的次数,提高查询性能。
enable_distinct_column_bucketization:用于启用StarRocks中的去重列分桶优化。去重列分桶可以将相同值的数据放在同一个桶中,减少存储和计算开销。
是否在 group-by-count-distinct 查询中开启对 count distinct 列的分桶优化。在类似 select a, count(distinct b) from t group by a; 的查询中,如果 group by 列 a 为低基数列,count distinct 列 b 为高基数列且发生严重数据倾斜时,会引发查询性能瓶颈。可以通过对 count distinct 列进行分桶来平衡数据,规避数据倾斜。
默认值:false,表示不开启。该变量需要与 count_distinct_column_buckets 配合使用。
您也可以通过添加 skew hint 来开启 count distinct 列的分桶优化,例如 select a,count(distinct [skew] b) from t group by a;。
enable_filter_unused_columns_in_scan_stage:启用此参数后,在扫描阶段将过滤掉未使用的列,以减少数据传输和存储开销。
enable_global_runtime_filter:启用此参数后,StarRocks将在运行时使用全局运行时过滤器来减少不必要的数据传输和计算。
Global runtime filter 开关。Runtime Filter(简称 RF)在运行时对数据进行过滤,过滤通常发生在 Join 阶段。当多表进行 Join 时,往往伴随着谓词下推等优化手段进行数据过滤,以减少 Join 表的数据扫描以及 shuffle 等阶段产生的 IO,从而提升查询性能。StarRocks 中有两种 RF,分别是 Local RF 和 Global RF。Local RF 应用于 Broadcast Hash Join 场景。Global RF 应用于 Shuffle Join 场景。
默认值 true,表示打开 global runtime filter 开关。关闭该开关后, 不生成 Global RF, 但是依然会生成 Local RF。
enable_groupby_use_output_alias:启用此参数后,StarRocks将使用输出别名来优化GROUP BY操作,以减少计算和传输开销。
enable_hive_column_stats:启用此参数后,StarRocks将使用Hive中的列统计信息来优化查询计划,以提高查询性能。
enable_insert_strict:启用此参数后,StarRocks将在插入数据时执行严格的检查,以确保数据的完整性和一致性。
enable_local_shuffle_agg:启用此参数后,StarRocks将在本地节点上执行聚合操作,以减少数据传输和计算开销。
enable_materialized_view_rewrite:启用此参数后,StarRocks将尝试使用物化视图重写查询计划,以提高查询性能。
enable_materialized_view_union_rewrite:是否开启物化视图 Union 改写。默认值:true。启用此参数后,StarRocks将尝试使用物化视图联合重写查询计划,以提高查询性能。
enable_multicolumn_global_runtime_filter:启用此参数后,StarRocks将在运行时使用多列全局运行时过滤器来进一步减少数据传输和计算。
对于 Broadcast 和 Replicated Join 类型之外的其他 Join,当 Join 的等值条件有多个的情况下:
如果该选项关闭: 则只会产生 Local RF。
如果该选项打开, 则会生成 multi-part GRF, 并且该 GRF 需要携带 multi-column 作为 partition-by 表达式.
enable_mv_planner:启用或禁用物化视图查询优化器。物化视图是一种预计算和存储查询结果的技术,可以加速查询性能。
enable_pipeline_engine:启用或禁用管道引擎。管道引擎是一种查询执行引擎,可以将查询计划分解为多个阶段,并在每个阶段中并行执行,以提高查询性能。
enable_pipeline_query_statistic:启用或禁用管道查询统计信息。当启用时,StarRocks会收集和记录管道查询的统计信息,以便进行性能分析和优化。
enable_populate_block_cache:启用或禁用块缓存的填充。块缓存是一种内存缓存,用于存储热点数据块,以提高查询性能。
enable_predicate_reorder:启用或禁用谓词重排序优化。谓词重排序是一种优化技术,可以重新排列查询中的谓词条件,以提高查询性能。
enable_profile:启用或禁用查询性能分析。当启用时,StarRocks会记录查询的执行时间、资源消耗等信息,以便进行性能分析和调优。
enable_prune_complex_types:启用或禁用复杂类型的剪枝优化。复杂类型是指包含嵌套结构的数据类型,如数组、结构体等。剪枝优化可以在查询计划中剪枝掉不必要的复杂类型字段,以提高查询性能。
enable_query_cache:启用或禁用查询缓存。查询缓存可以缓存查询的结果,以便在后续相同的查询中直接返回缓存结果,从而提高查询性能。
enable_query_dump:启用或禁用查询日志记录。当启用时,StarRocks会记录查询的详细信息,包括查询语句、执行计划等,以便进行故障排查和性能分析。
enable_query_queue_load:启用或禁用查询队列负载均衡。当启用时,StarRocks会根据查询队列的负载情况,动态调整查询的调度策略,以实现负载均衡和资源优化。
enable_query_queue_select:启用查询队列选择,用于在多个查询队列中选择合适的队列来执行查询。
enable_query_queue_statistic:启用查询队列统计,用于收集和展示查询队列的相关统计信息。
enable_realtime_mv:启用实时物化视图,用于实时计算和更新物化视图。
enable_resource_group:启用资源组,用于将不同的查询分配到不同的资源组中,以实现资源的有效管理和分配。
enable_rewrite_groupingsets_to_union_all:启用将Grouping Sets重写为Union All的优化,用于优化包含Grouping Sets的查询。
enable_rule_based_materialized_view_rewrite:启用基于规则的物化视图重写,用于自动将查询重写为物化视图的形式以提高查询性能。
enable_scan_block_cache:启用扫描块缓存,用于在查询过程中缓存扫描的块数据,以加快查询速度。
enable_shared_scan:启用共享扫描,用于在多个查询之间共享扫描的结果,以减少重复扫描的开销。
enable_sort_aggregate:是否开启 sorted streaming 聚合,用于在聚合操作中对数据进行排序,以提高查询性能。
enable_tablet_internal_parallel:启用表内并行,用于在查询过程中并行执行表内的操作,以加快查询速度。是否开启自适应 Tablet 并行扫描,使用多个线程并行分段扫描一个 Tablet,可以减少 Tablet 数量对查询能力的限制。默认值为 true。自 2.3 版本起,StarRocks 支持该参数。
event_scheduler:启用事件调度器,用于调度和执行定时任务。
exec_mem_limit:设置执行内存限制,用于限制查询执行过程中的内存使用。
force_schedule_local:强制将任务调度到本地节点执行,以减少网络传输开销。
forward_to_leader:将查询请求直接发送给Leader节点,减少请求的转发开销。
forward_to_master:
用于设置是否将一些命令转发到 Leader FE 节点执行。默认为 false,即不转发。StarRocks 中存在多个 FE 节点,其中一个为 Leader 节点。通常用户可以连接任意 FE 节点进行全功能操作。但部分信息查看指令只有从 Leader FE 节点才能获取详细信息。
如 SHOW BACKENDS; 命令,如果不转发到 Leader FE 节点,则仅能看到节点是否存活等一些基本信息,而转发到 Leader FE 则可以获取包括节点启动时间、最后一次心跳时间等更详细的信息。
当前受该参数影响的命令如下:
SHOW FRONTENDS;
SHOW BACKENDS;
SHOW BROKER;
SHOW TABLET;
ADMIN SHOW REPLICA DISTRIBUTION;
ADMIN SHOW REPLICA STATUS;
SHOW PROC
full_sort_late_materialization:在执行排序操作时,延迟材料化(materialization)排序的结果,以减少内存占用。
group_concat_max_len:设置GROUP_CONCAT函数返回的字符串最大长度。
hash_join_push_down_right_table:对于Hash Join操作,将右侧表的数据推送到左侧表所在的节点上进行计算,减少数据传输开销。
用于控制在 Join 查询中是否可以使用针对右表的过滤条件来过滤左表的数据,可以减少 Join 过程中需要处理的左表的数据量。取值为 true 时表示允许该操作,系统将根据实际情况决定是否能对左表进行过滤;取值为 false 表示禁用该操作。默认值为 true。
hive_partition_stats_sample_size:设置Hive分区统计信息采样的大小。
hudi_mor_force_jni_reader:在使用Hudi MOR(Merge On Read)引擎时,强制使用JNI读取器进行数据读取。
init_connect:设置新建连接时执行的初始化SQL语句。
nnodb_read_only:这个参数用于设置StarRocks是否以只读模式运行。当设置为1时,StarRocks将只允许读取操作,而不允许写入操作。这在某些情况下可以用于保护数据的完整性,防止意外的写入操作。
interactive_timeout:这个参数用于设置StarRocks与客户端之间的交互超时时间。当客户端在一段时间内没有发送任何请求时,超过了这个时间,StarRocks将自动断开与该客户端的连接。这可以用于释放空闲连接,提高系统的资源利用率。
join_implementation_mode_v2:这个参数用于设置StarRocks在执行JOIN操作时的实现模式。StarRocks支持多种JOIN实现模式,包括BROADCAST、SHUFFLE和MERGE等。通过调整这个参数,可以根据具体的数据分布和查询需求,选择最优的JOIN实现模式,提高查询性能。
license:该参数用于设置Starrocks的许可证信息。它用于验证Starrocks的合法性和授权。
load_mem_limit:用于指定导入操作的内存限制,单位为 Byte。默认值为 0,即表示不使用该变量,而采用 query_mem_limit 作为导入操作的内存限制。
这个变量仅用于 INSERT 操作。因为 INSERT 操作涉及查询和导入两个部分,如果用户不设置此变量,则查询和导入操作各自的内存限制均为 query_mem_limit。否则,INSERT 的查询部分内存限制为 query_mem_limit,而导入部分限制为 load_mem_limit。
其他导入方式,如 Broker Load,STREAM LOAD 的内存限制依然使用 query_mem_limit。
load_transmission_compression_type:该参数用于设置Starrocks在数据加载过程中的传输压缩类型。它可以控制数据加载时的压缩方式,以减少网络传输的数据量。
license:该参数用于设置Starrocks的许可证信息。它用于验证Starrocks的合法性和授权。
load_mem_limit:该参数用于设置Starrocks在执行数据加载操作时的内存限制。它可以控制Starrocks在加载数据时所使用的内存量。
load_transmission_compression_type:该参数用于设置Starrocks在数据加载过程中的传输压缩类型。它可以控制数据加载时的压缩方式,以减少网络传输的数据量。
lower_case_table_names:该参数用于设置Starrocks中表名的大小写规则。当设置为1时,表名将被转换为小写;当设置为0时,表名将保持原样。
max_allowed_packet:该参数决定了服务端发送给客户端或客户端发送给服务端的最大 packet 大小。它可以控制Starrocks在网络传输中所能处理的数据量。默认值为 32 MB。当客户端报 PacketTooBigException 异常时,可以考虑调大该值。
max_parallel_scan_instance_num:该参数用于设置Starrocks在执行并行扫描操作时的最大并行度。它可以控制Starrocks在扫描数据时所使用的并行线程数。
max_pushdown_conditions_per_column:该参数用于设置Starrocks在执行查询时每个列所能推送的最大条件数。它可以控制Starrocks在查询优化中所能使用的条件数量。
max_scan_key_num:该参数用于设置Starrocks在执行扫描操作时每个扫描键所能包含的最大值数量。它可以控制Starrocks在扫描数据时所能处理的键值对数量。
nested_mv_rewrite_max_level:可用于查询改写的嵌套物化视图的最大层数。类型:INT。取值范围:[1, +∞)。默认值:3。取值为 1 表示只可使用基于基表创建的物化视图用于查询改写。
net_buffer_length:指定网络缓冲区的长度。
net_read_timeout:指定从网络读取数据的超时时间。
net_write_timeout:指定向网络写入数据的超时时间。
new_planner_agg_stage:指定新的查询优化器中聚合操作的阶段。
new_planner_optimize_timeout:查询优化器的超时时间。一般查询中 Join 过多时容易出现超时。超时后会报错并停止查询,影响查询性能。您可以根据查询的具体情况调大该参数配置,也可以将问题上报给 StarRocks 技术支持进行排查。单位:秒。默认值:3000。
parallel_exchange_instance_num:指定并行交换操作的实例数。
parallel_fragment_exec_instance_num:指定并行片段执行的实例数。默认为1.表示每个BE上fragment的实例数量,如果希望提升单个查询的性能,可以设置为BE的CPU核数的一半。
parse_tokens_limit:指定解析器解析的最大令牌数。
performance_schema:指定是否启用性能模式,用于收集和报告性能数据。
pipeline_dop:一个 Pipeline 实例的并行数量。可通过设置实例的并行数量调整查询并发度。默认值为 0,即系统自适应调整每个 pipeline 的并行度。您也可以设置为大于 0 的数值,通常为 BE 节点 CPU 物理核数的一半。从 3.0 版本开始,支持根据查询并发度自适应调节 pipeline_dop。
pipeline_profile_level:用于控制 profile 的等级。一个 profile 通常有 5 个层级:Fragment、FragmentInstance、Pipeline、PipelineDriver、Operator。不同等级下,profile 的详细程度有所区别:
0:在此等级下,StarRocks 会合并 profile,只显示几个核心指标。
1:默认值。在此等级下,StarRocks 会对 profile 进行简化处理,将同一个 pipeline 的指标做合并来缩减层级。
2:在此等级下,StarRocks 会保留 Profile 所有的层级,不做简化。该设置下 profile 的体积会非常大,特别是 SQL 较复杂时,因此不推荐该设置。
prefer_compute_node:指定是否优先使用计算节点进行查询处理。
query_cache_agg_cardinality_limit:查询缓存中GROUP BY 聚合的高基数上限。GROUP BY 聚合的输出预估超过该行数, 则不启用 cache。默认值:5000000。
query_cache_entry_max_bytes:查询缓存中单个查询结果的最大字节数。当查询结果的字节数超过该限制时,查询结果将不会被缓存。取值范围:0 ~ 9223372036854775807。默认值:4194304。当一个 Tablet 上产生的计算结果的字节数或者行数超过 query_cache_entry_max_bytes 或 query_cache_entry_max_rows 指定的阈值时,则查询采用 Passthrough 模式执行。当 query_cache_entry_max_bytes 或 query_cache_entry_max_rows 取值为 0 时, 即便 Tablet 产生结果为空,也采用 Passthrough 模式。
query_cache_entry_max_rows:查询缓存中单个查询结果的最大行数。当查询结果的行数超过该限制时,查询结果将不会被缓存。默认值:409600。
query_cache_force_populate:是否强制查询缓存预热。当设置为true时,StarRocks会在启动时将查询缓存中的所有查询结果加载到内存中。
query_cache_hot_partition_num:查询缓存中热分区的数量。热分区是指经常被查询的分区,将这些分区的查询结果缓存起来可以提高查询性能。
query_cache_size:查询缓存的大小,以字节为单位。该参数指定了查询缓存可以使用的最大内存大小。
query_cache_type:查询缓存的类型。可以选择的类型有LRU(最近最少使用)和LFU(最不经常使用)。
query_delivery_timeout:查询结果的传输超时时间,以毫秒为单位。当查询结果的传输时间超过该限制时,查询将被终止。
query_mem_limit:用于设置每个 BE 节点上查询的内存限制。以字节为单位。当查询使用的内存超过该限制时,查询将被终止。
query_queue_concurrency_limit:单个 BE 节点中并发查询上限。仅在设置为大于 0 后生效。该参数指定了查询队列可以同时执行的查询数量。
query_queue_cpu_used_permille_limit:单个 BE 节点中查询队列的CPU使用率限制。。仅在设置为大于 0 后生效。默认值:0。取值范围:[0, 1000]。当查询队列的CPU使用率超过该限制时,新的查询将被拒绝。
query_queue_fresh_resource_usage_interval_ms:查询队列刷新资源使用情况的时间间隔,以毫秒为单位。该参数指定了查询队列多久刷新一次资源使用情况。
query_queue_max_queued_queries:查询队列中查询数量的上限。当查询队列中的查询数量超过该限制时,新的查询将被拒绝。
query_queue_mem_used_pct_limit:查询队列的内存使用率限制,取值范围:[0, 1]。当查询队列的内存使用率超过该限制时,新的查询将被拒绝。
query_queue_pending_timeout_second:查询队列中查询的等待超时时间,以秒为单位。当查询在队列中等待的时间超过该限制时,查询将被终止。
query_timeout:查询的超时时间,以毫秒为单位。当查询执行时间超过该限制时,查询将被终止。
runtime_filter_on_exchange_node:控制是否在交换节点上启用运行时过滤器,用于减少数据传输量和提高查询性能。
GRF 成功下推跨过 Exchange 算子后,是否在 Exchange Node 上放置 GRF。当一个 GRF 下推跨越 Exchange 算子,最终安装在 Exchange 算子更下层的算子上时,Exchange 算子本身是不放置 GRF 的,这样可以避免重复性使用 GRF 过滤数据而增加计算时间。但是 GRF 的投递本身是 try-best 模式,如果 query 执行时,Exchange 下层的算子接收 GRF 失败,而 Exchange 本身又没有安装 GRF,数据无法被过滤,会造成性能衰退. 该选项打开(设置为 true)时,GRF 即使下推跨过了 Exchange 算子, 依然会在 Exchange 算子上放置 GRF 并生效。默认值为 false。
runtime_join_filter_push_down_limit:控制运行时连接过滤器下推的阈值,用于决定是否将连接过滤器下推到扫描节点。生成 Bloomfilter 类型的 Local RF 的 Hash Table 的行数阈值。超过该阈值, 则不产生 Local RF。该变量避免产生过大 Local RF。取值为整数,表示行数。默认值:1024000。
sql_mode:设置SQL模式,用于控制SQL语句的解析和执行行为。
sql_safe_updates:控制是否启用安全更新模式,用于防止误操作更新整个表。
sql_select_limit:设置单个查询返回的最大行数限制。
statistic_collect_parallel:控制统计信息收集的并行度,用于加快统计信息的收集速度。
storage_engine:指定系统使用的存储引擎。StarRocks 支持的引擎类型包括:
olap:StarRocks 系统自有引擎。
mysql:使用 MySQL 外部表。
broker:通过 Broker 程序访问外部表。
ELASTICSEARCH 或者 es:使用 Elasticsearch 外部表。
HIVE:使用 Hive 外部表。
ICEBERG:使用 Iceberg 外部表。从 2.1 版本开始支持。
HUDI: 使用 Hudi 外部表。从 2.2 版本开始支持。
jdbc: 使用 JDBC 外部表。从2.3 版本开始支持。
streaming_preaggregation_mode
用于设置多阶段聚合时,group-by 第一阶段的预聚合方式。如果第一阶段本地预聚合效果不好,则可以关闭预聚合,走流式方式,把数据简单序列化之后发出去。取值含义如下:
auto:先探索本地预聚合,如果预聚合效果好,则进行本地预聚合;否则切换成流式。默认值,建议保留。
force_preaggregation: 不进行探索,直接进行本地预聚合。
force_streaming: 不进行探索,直接做流式。
system_time_zone (global)
显示当前系统时区。不可更改。
streaming_preaggregation_mode:控制流式预聚合模式,用于优化流式查询的性能。
system_time_zone:设置系统时区,用于处理日期和时间相关的操作。
time_zone:设置会话时区,用于处理日期和时间相关的操作。
transaction_isolation:设置事务隔离级别,用于控制并发事务的行为。
transmission_compression_type:设置传输压缩类型,用于减少数据传输的网络带宽消耗。
transmission_encode_level:设置传输编码级别,用于控制数据传输的压缩比例和性能。
tx_isolation:设置事务隔离级别,用于控制并发事务的行为。
tx_visible_wait_timeout:设置事务可见性等待超时时间,用于控制事务的等待时间。
use_compute_nodes:控制是否使用计算节点进行查询计算,用于优化查询的性能和资源利用。
该设置只会在 prefer_compute_node=true 时才会生效。 -1 表示使用所有 CN 节点,0 表示不使用 CN 节点。默认值为 -1。该变量从 2.4 版本开始支持。
wait_timeout:设置客户端连接的超时时间。如果客户端在指定的时间内没有发送任何请求,则服务器会关闭连接。
default_table_compression (3.0 及以后)
存储表格数据时使用的默认压缩算法,支持 LZ4、Zstandard(或 zstd)、zlib 和 Snappy。默认值:lz4_frame。如果您建表时在 PROPERTIES 设置了 compression,则 compression 指定的压缩算法生效。
enable_spill(3.0 及以后)
是否启用中间结果落盘。默认值:false。如果将其设置为 true,StarRocks 会将中间结果落盘,以减少在查询中处理聚合、排序或连接算子时的内存使用量。
range_pruner_max_predicate (3.0 及以后)
设置进行 Range 分区裁剪时,最多能使用的 IN 谓词的个数,默认值:100。如果超过该值,会扫描全部 tablet,降低查询性能。
spill_mode (3.0 及以后)
中间结果落盘的执行方式。默认值:auto。有效值包括:
auto:达到内存使用阈值时,会自动触发落盘。
force:无论内存使用情况如何,StarRocks 都会强制落盘所有相关算子的中间结果。
此变量仅在变量 enable_spill 设置为 true 时生效。
sql_dialect (3.0 及以后)
设置生效的 SQL 语法。例如,执行 set sql_dialect = 'trino'; 命令可以切换为 Trino 语法,这样您就可以在查询中使用 Trino 特有的 SQL 语法和函数。
注意
设置使用 Trino 语法后,查询默认对大小写不敏感。因此,您在 StarRocks 内建库、表时必须使用小写的库、表名称,否则查询会失败。
batch_size
用于指定在查询执行过程中,各个节点传输的单个数据包的行数。默认一个数据包的行数为 1024 行,即源端节点每产生 1024 行数据后,打包发给目的节点。较大的行数,会在扫描大数据量场景下提升查询的吞吐率,但可能会在小查询场景下增加查询延迟。同时,也会增加查询的内存开销。建议设置范围 1024 至 4096。
connector_io_tasks_per_scan_operator(2.5 及以后)
外表查询时每个 Scan 算子能同时下发的 I/O 任务的最大数量。取值为整数,默认值 16。目前外表查询时会使用自适应算法来调整并发 I/O 任务的数量,通过 enable_connector_adaptive_io_tasks 开关来控制,默认打开。
count_distinct_column_buckets(2.5 及以后)
group-by-count-distinct 查询中为 count distinct 列设置的分桶数。该变量只有在 enable_distinct_column_bucketization 设置为 true 时才会生效。默认值:1024。
enable_connector_adaptive_io_tasks(2.5 及以后)
外表查询时是否使用自适应策略来调整 I/O 任务的并发数。默认打开。如果未开启自适应策略,可以通过 connector_io_tasks_per_scan_operator 变量来手动设置外表查询时的 I/O 任务并发数。
force_streaming_aggregate
用于控制聚合节点是否启用流式聚合计算策略。默认为 false,表示不启用该策略。
io_tasks_per_scan_operator (2.5 及以后)
每个 Scan 算子能同时下发的 I/0 任务的数量。如果使用远端存储系统(比如 HDFS 或 S3)且时延较长,可以增加该值。但是值过大会增加内存消耗。
取值为整数。默认值:4。
use_v2_rollup
用于控制查询使用 segment v2 存储格式的 Rollup 索引获取数据。该变量用于上线 segment v2 的时进行验证使用。其他情况不建议使用。
查询管理相关参数
# 调整查询并发度
enable_pipeline_engine
是否启用 Pipeline 执行引擎。true:启用(默认),false:不启用。
pipeline_dop
一个 Pipeline 实例的并行数量。建议设为默认值 0,即系统自适应调整每个 pipeline 的并行度。您也可以设置为大于 0 的数值,通常为 BE 节点 CPU 物理核数的一半。
# 调整查询内存上限
query_mem_limit
内存参数说明
session变量相关:
query_mem_limit
各 BE 节点上单个查询的内存限制,单位是 Byte。建议设置为 17179869184(16GB)以上。
load_mem_limit
各 BE 节点上单个导入任务的内存限制,单位是 Byte。如果设置为 0,StarRocks 采用 exec_mem_limit 作为内存限制。
内存分类:
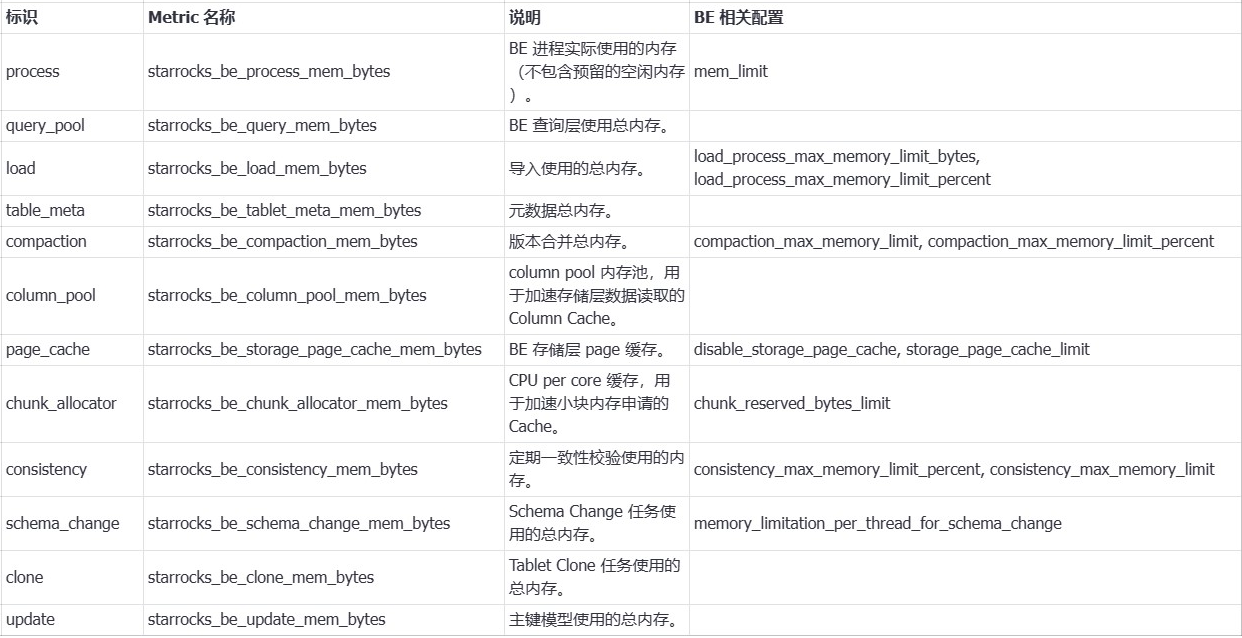
BE内存相关配置
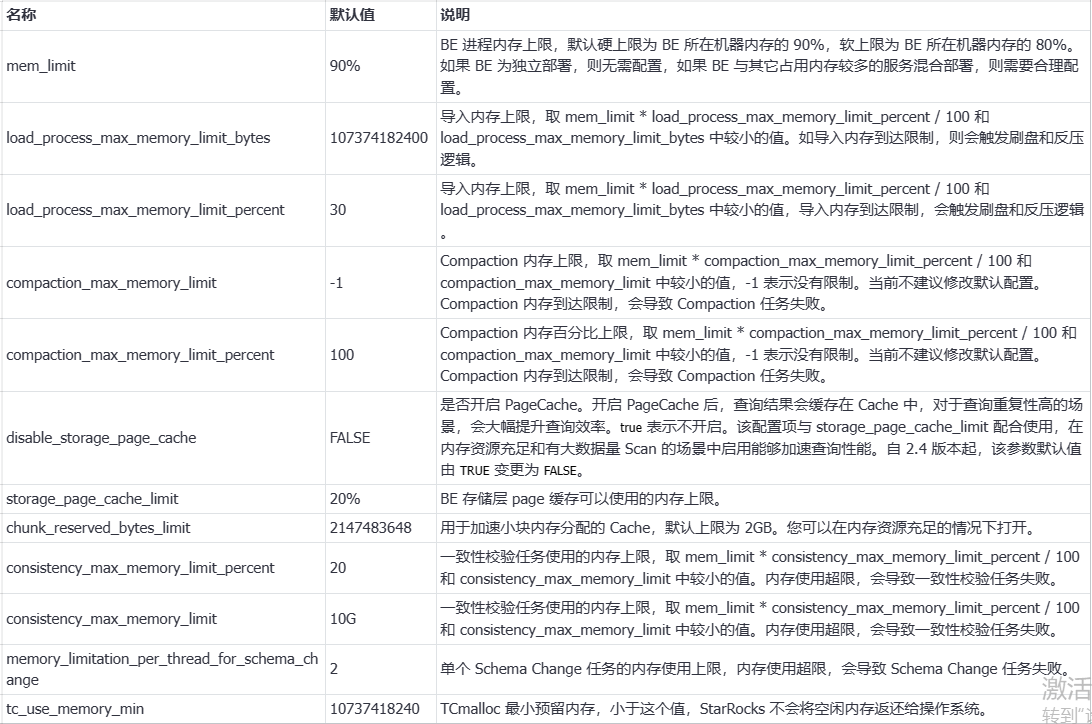
query cache
FE 会话变量
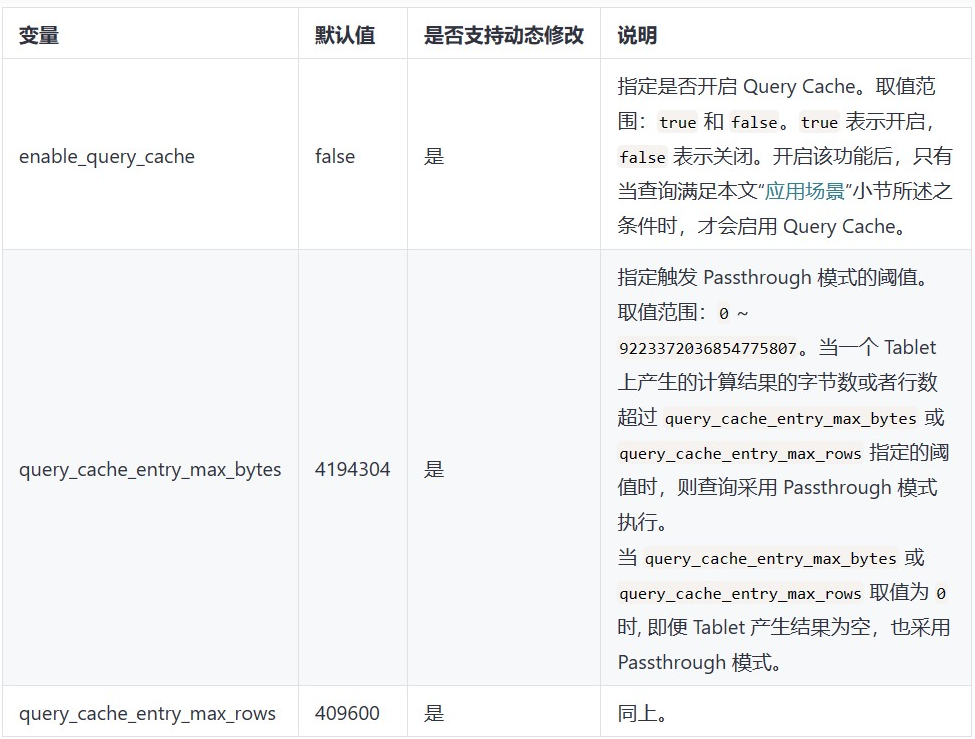
BE 配置项

额外参数
enable_exchange_pass_through
启用或禁用交换操作的优化。enable_exchange_pass_through参数默认为true,表示启用交换操作的优化。当启用此参数时,Starrocks会尽可能地将交换操作的数据直接传输给目标节点,而不是先将数据发送到中间节点,再由中间节点将数据传输给目标节点。这样可以减少数据传输的次数,提高查询性能。
但是,在某些情况下,启用交换操作的优化可能会导致性能下降。例如,当参与JOIN操作的表的数据大小差异较大时,如果启用了enable_exchange_pass_through参数,数据传输的速度可能会受到数据量较大的表的限制,导致整个查询的性能变慢。
tablet_writer_open_rpc_timeout_sec
描述:在远程BE 中打开tablet writer的 rpc 超时。 操作时间短,可设置短超时时间
导入过程中,发送一个 Batch(1024行)的 RPC 超时时间。默认 60 秒。因为该 RPC 可能涉及多个 分片内存块的写盘操作,所以可能会因为写盘导致 RPC 超时,可以适当调整这个超时时间来减少超时错误(如 send batch fail 错误)。同时,如果调大 write_buffer_size 配置,也需要适当调大这个参数
默认值:60
max_user_connections
用户最大的连接数,默认值为100。一般情况不需要更改该参数,除非查询的并发数超过了默认值。
max_query_instances
用户同一时间点可使用的instance个数, 默认是-1,小于等于0将会使用配置default_max_query_instances.
manual_compact_before_data_dir_load
该配置项控制在加载新的数据目录(data_dir)之前是否执行手动压缩操作。
当manual_compact_before_data_dir_load设置为true时,在加载新的数据目录之前,会触发手动压缩操作。手动压缩可以将数据目录中的数据块进行合并,减少数据的碎片化,提高查询性能和存储效率。但这可能会增加加载新数据的时间和IO开销。
enable_filter_unused_columns_in_scan_stage
该配置项控制是否在扫描阶段过滤未使用的列。
当enable_filter_unused_columns_in_scan_stage设置为true时,StarRocks会在查询执行期间检测并过滤掉未使用的列,从而减少读取和处理的数据量,提高查询性能和节省内存消耗。但在某些情况下,如果查询需要返回所有列的结果,禁用此选项可能会提高查询性能。
base_compaction_min_rowset_num
描述:BaseCompaction触发条件之一:Cumulative文件数目要达到的限制,达到这个限制之后会触发BaseCompaction
默认值:5
query_cache_force_populate
指定是否忽略 Query Cache 中已有的计算结果.取值范围:true 和 false。true 表示开启,false 表示关闭。
enable_resource_group
开启资源组
cpu_core_limit
该资源组在当前 BE 节点可使用的 CPU 核数软上限,实际使用的 CPU 核数会根据节点资源空闲程度按比例弹性伸缩。取值为正整数。
mem_limit
该资源组在当前 BE 节点可使用于查询的内存(query_pool)占总内存的百分比(%)。取值范围为 (0,1)。
concurrency_limit
资源组中并发查询数的上限,用以防止并发查询提交过多而导致的过载。只有大于 0 时才生效,默认值为 0。
big_query_cpu_second_limit
大查询任务可以使用 CPU 的时间上限,其中的并行任务将累加 CPU 使用时间。单位为秒。只有大于 0 时才生效,默认值为 0。
big_query_scan_rows_limit
大查询任务可以扫描的行数上限。只有大于 0 时才生效,默认值为 0。
big_query_mem_limit
大查询任务可以使用的内存上限。单位为 Byte。只有大于 0 时才生效,默认值为 0。
parquet_late_materialization_enable
禁用/开启parquet文件的延迟物化。
可以确保在查询执行之前,所有列和行都会被加载到内存中。这可能会增加内存的使用量,但有助于提高查询的性能,尤其是在需要访问大量列或行的情况下。
enable_materialized_view_rewrite
启用异步物化视图查询改写
enable_materialized_view_union_rewrite
是否开启物化视图 Union 改写。
enable_rule_based_materialized_view_rewrite true
是否开启基于规则的物化视图查询改写功能,主要用于处理单表查询改写。
nested_mv_rewrite_max_level 3
可用于查询改写的嵌套物化视图的最大层数。类型:INT。取值范围:[1, +∞)。取值为 1 表示只可使用基于基表创建的物化视图用于查询改写。
max_scheduling_tablets
默认值:2000
是否可以动态配置:true
是否为 Master FE 节点独有的配置项:true
如果 TabletScheduler 中调度的 tablet 数量超过 max_scheduling_tablets, 则跳过检查。
disable_balance
默认值:false
是否可以动态配置:true
是否为 Master FE 节点独有的配置项:true
如果设置为 true,TabletScheduler 将不会做 balance
disable_colocate_balance
默认值:false
是否可以动态配置:true
是否为 Master FE 节点独有的配置项:true
此配置可以设置为 true 以禁用自动 colocate 表的重新定位和平衡。 如果 disable_colocate_balance'设置为 true,则 ColocateTableBalancer 将不会重新定位和平衡并置表。
可监控的资源组相关 Metrics 包括:
FE 节点
starrocks_fe_query_resource_group:该资源组中查询任务的数量。
starrocks_fe_query_resource_group_latency:该资源组的查询延迟百分位数。
starrocks_fe_query_resource_group_err:该资源组中报错的查询任务的数量。
BE 节点
starrocks_be_resource_group_cpu_limit_ratio:该资源组 CPU 配额比率的瞬时值。
starrocks_be_resource_group_cpu_use_ratio:该资源组 CPU 使用率瞬时值。
starrocks_be_resource_group_mem_limit_bytes:该资源组内存配额比率的瞬时值。
starrocks_be_resource_group_mem_allocated_bytes:该资源组内存使用率瞬时值。
中间结果落盘
本文由mdnice多平台发布

















 1184
1184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









