






 本文详细介绍了SparkSQL在处理异常、性能优化以及自动分区合并(AQE)等方面的关键参数,包括parquet格式的兼容性问题、decimal类型的精度丢失、文件缺失或损坏的处理策略,以及shuffle和join操作的性能调整参数。同时,提到了broadcastjoin的阈值和自适应执行的启用,以及动态资源申请在解决计算资源不足时的作用。
本文详细介绍了SparkSQL在处理异常、性能优化以及自动分区合并(AQE)等方面的关键参数,包括parquet格式的兼容性问题、decimal类型的精度丢失、文件缺失或损坏的处理策略,以及shuffle和join操作的性能调整参数。同时,提到了broadcastjoin的阈值和自适应执行的启用,以及动态资源申请在解决计算资源不足时的作用。
异常调优
兼容性问题与规避方案
spark.sql.hive.convertMetastoreParquet
parquet是一种列式存储格式,可以用于spark-sql 和hive 的存储格式。在spark中,如果使用using parqeut的形式创建表,则创建的是spark 的DataSource表;而如果使用stored as parquet则创建的是hive表。
默认设置是true, 它代表使用spark-sql内置的parquet的reader和writer(即进行反序列化和序列化),它具有更好地性能,如果设置为false,则代表使用 Hive的序列化方式。
但是有时候当其设置为true时,会出现使用hive查询表有数据,而使用spark查询为空的情况.
但是,有些情况下在将spark.sql.hive.convertMetastoreParquet设为false,可能发生以下异常(spark-2.3.2)。  这是因为在其为false时候,是使用hive-metastore使用的元数据进行读取数据,而如果此表是使用spark sql DataSource创建的parquet表,其数据类型可能出现不一致的情况,例如通过metaStore读取到的是IntWritable类型,其创建了一个WritableIntObjectInspector用来解析数据,而实际上value是LongWritable类型,因此出现了类型转换异常。
这是因为在其为false时候,是使用hive-metastore使用的元数据进行读取数据,而如果此表是使用spark sql DataSource创建的parquet表,其数据类型可能出现不一致的情况,例如通过metaStore读取到的是IntWritable类型,其创建了一个WritableIntObjectInspector用来解析数据,而实际上value是LongWritable类型,因此出现了类型转换异常。
与该参数相关的一个参数是:
spark.sql.hive.convertMetastoreParquet.mergeSchema, 如果也是true,那么将会尝试合并各个parquet 文件的schema,以使得产生一个兼容所有parquet文件的schema.
精度丢失问题
spark.sql.decimalOperations.allowPrecisionLoss参数。
当该参数为true(默认),表示允许丢失精度,会根据Hive行为和SQL ANSI 2011规范来决定result的类型,即如果无法精确的表示,则舍入结果的小数部分。
当该参数为false时,代表不允许丢失精度,这样会将数据表示的更加精确。
spark.sql. decimalOperations.nullOnOverflow
对于Decimal类型,由于其整数部分位数是(precision-scale),因此该类型能表示的范围是有限的,一旦超出这个范围,就会发生Overflow。而在Spark中,如果Decimal计算发生了Overflow,就会默认返回Null值。
引入了参数spark.sql. decimalOperations.nullOnOverflow 用来控制在Decimal Operation 发生Overflow时候的处理方式。
遇到表路径下的文件缺失/corrupt 异常
spark.sql.files.ignoreMissingFiles && spark.sql.files.ignoreCorruptFiles
这两个参数是只有在进行spark DataSource 表查询的时候才有效,如果是对hive表进行操作是无效的。
在进行spark DataSource 表查询时候,可能会遇到非分区表中的文件缺失/corrupt 或者分区表分区路径下的文件缺失/corrupt 异常,这时候加这两个参数会忽略这两个异常,这两个参数默认都是false,建议在线上可以都设为true.
其源码逻辑如下,简单描述就是如果遇到FileNotFoundException, 如果设置了ignoreMissingFiles=true则忽略异常,否则抛出异常;如果不是FileNotFoundException 而是IOException(FileNotFoundException的父类)或者RuntimeException,则认为文件损坏,如果设置了ignoreCorruptFiles=true则忽略异常。 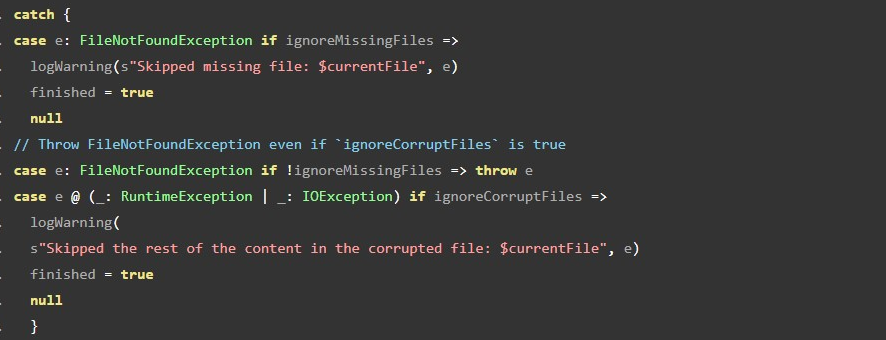 分区路径下面的文件不存在或者损坏的处理
分区路径下面的文件不存在或者损坏的处理
上面的两个参数在分区表情况下是针对分区路径存在的情况下,分区路径下面的文件不存在或者损坏的处理。而有另一种情况就是这个分区路径都不存在了。这时候异常信息如下: 
spark.sql.hive.verifyPartitionPath
参数默认是false,当设置为true的时候会在获得分区路径时对分区路径是否存在做一个校验,过滤掉不存在的分区路径,这样就会避免上面的错误。
spark.files.ignoreCorruptFiles && spark.files.ignoreMissingFiles
这两个参数和上面的spark.sql.files.ignoreCorruptFiles很像,但是区别是很大的。在spark进行DataSource表查询时候spark.sq.files.*才会生效,而spark如果查询的是一张hive表,其会走HadoopRDD这条执行路线。
所以就会出现,即使你设置了spark.sql.files.ignoreMissingFiles的情况下,仍然报FileNotFoundException的情况,异常栈如下, 可以看到这里面走到了HadoopRDD,而且后面是org.apache.hadoop.hive.ql.io.parquet.read.ParquetRecordReaderWrappe可见是查询一张hive表。 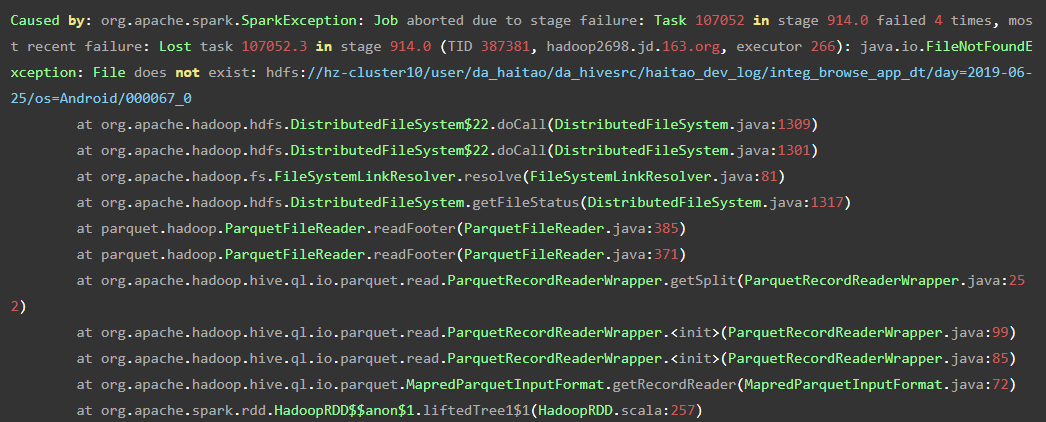 此时可以将spark.files.ignoreCorruptFiles && spark.files.ignoreMissingFiles设为true,其代码逻辑和上面的spark.sql.file.*逻辑没明显区别,此处不再赘述.
此时可以将spark.files.ignoreCorruptFiles && spark.files.ignoreMissingFiles设为true,其代码逻辑和上面的spark.sql.file.*逻辑没明显区别,此处不再赘述.
spark shuffle几个常用相关参数 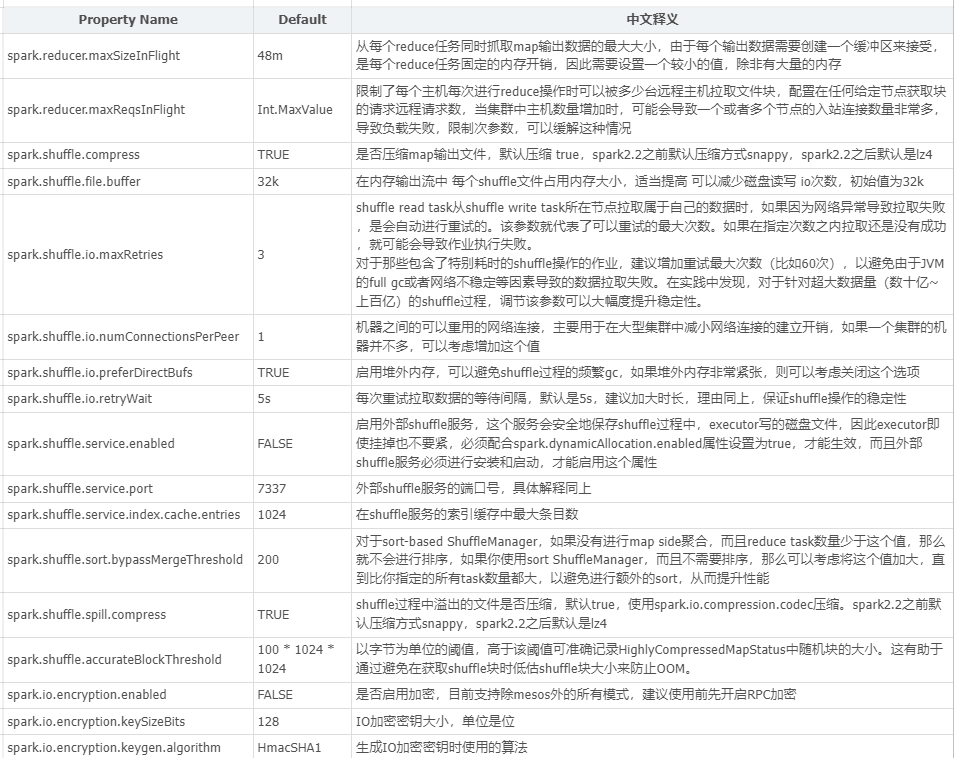
spark.shuffle.file.buffer
default: 32k
shuffle write端写磁盘文件时缓冲区大小,适量增大可以减少磁盘I/O次数,进而提升性能。
spark.reducer.maxSizeInFlight
default: 48M
shuffle read端拉取对应分区数据缓冲区大小,适量增大可以减少网络传输次数,进而提升性能。
spark.shuffle.io.maxRetries
default: 3
shuffle read端拉取对应数据时,因为网络异常拉取失败重新尝试的最大次数。针对超大数据量的应用,可以增大重试次数,大幅度提升稳定性。
spark.maxRemoteBlockSizeFetchToMem
代表着可以从远端拉取数据放入内存的最大size.这个参数作用是在reduce task读取map task block时放入内存中的最大值;默认是没有限制全放内存
spark.shuffle.sort.bypassMergeThreshold
map端不进行排序的分区阈值
spark.shuffle.io.retryWait
重试2次的最大等待时间
spark.shuffle.spill.compress=true
默认使用spark.io.compression.codec
注:根据不同的spark版本有不同的个别shuffle配置如spark.maxRemoteBlockSizeFetchToMem等,根据不同的spark版本,查询对应的功能,如果详细查看逻辑,查看源码
sparksql CBO相关几个参数 
性能调优
除了遇到异常需要被动调整参数之外,我们还可以主动调整参数从而对性能进行调优。
spark.hadoopRDD.ignoreEmptySplits
默认是false,如果是true,则会忽略那些空的splits,减小task的数量。
spark.hadoop.mapreduce.input.fileinputformat.split.minsize
是用于聚合input的小文件,用于控制每个mapTask的输入文件,防止小文件过多时候,产生太多的task.
spark.sql.autoBroadcastJoinThreshold && spark.sql.broadcastTimeout
用于控制在spark sql中使用BroadcastJoin时候表的大小阈值,适当增大可以让一些表走BroadcastJoin,提升性能,但是如果设置太大又会造成driver内存压力,而broadcastTimeout是用于控制Broadcast的Future的超时时间,默认是300s,可根据需求进行调整。
spark.sql.adaptive.enabled && spark.sql.adaptive.shuffle.targetPostShuffleInputSize
该参数是用于开启spark的自适应执行,这是spark比较老版本的自适应执行,后面的targetPostShuffleInputSize是用于控制之后的shuffle 阶段的平均输入数据大小,防止产生过多的task。
intel大数据团队开发的adaptive-execution相较于目前spark的ae更加实用,该特性也已经加入到社区3.0之后的roadMap中,令人期待。
spark.sql.parquet.mergeSchema
默认false。当设为true,parquet会聚合所有parquet文件的schema,否则是直接读取parquet summary文件,或者在没有parquet summary文件时候随机选择一个文件的schema作为最终的schema。
spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version
1或者2,默认是1. MapReduce-4815 详细介绍了 fileoutputcommitter 的原理,实践中设置了 version=2 的比默认 version=1 的减少了70%以上的 commit 时间,但是1更健壮,能处理一些情况下的异常。
spark.sql.files.maxPartitionBytes
默认128MB,单个分区读取的最大文件大小
spark AQE相关:
spark AQE 自动分区合并
1.spark.sql.adaptive.enabled:Spark3.0 AQE开关,默认是false,如果要使用AQE功能,得先设置为true。
2.spark.sql.adaptive.coalescePartitions.enabled:动态缩小分区参数,默认值是true,但是得先保证spark.sql.adaptive.enabled为true。
3.spark.sql.adaptive.coalescePartitions.initialPartitionNum:任务刚启动时的初始分区,此参数可以设置了大点,默认值与spark.sql.shuffle.partition一样为200。
4.spark.sql.adaptive.coalescePartitions.minPartitionNum:进行动态缩小分区,最小缩小至多少分区,最终分区数不会小于此参数。
5.spark.sql.adaptive.advisoryPartitionSizeInBytes:缩小分区或进行拆分分区操作后所期望的每个分区的大小(数据量)。
spark AQE 动态join
spark.sql.adaptive.enabled: 是否开启AQE优化
spark.sql.adaptive.join.enabled 是否开启AQE 动态join优化
spark.sql.adaptive.localShuffleReader.enabled:在不需要进行shuffle重分区时,尝试使用本地shuffle读取器。将sort-meger join 转换为广播join
spark.sql.autoBroadcastJoinThreshold 中间文件尺寸总和小于广播阈值
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin 空文件占比小于配置项
spark AQE 自动倾斜处理
1.spark.sql.adaptive.enabled :开启aqe功能,默认关闭
2.spark.sql.adaptive.skewJoin.enabled:开启aqe倾斜join,需要先将spark.sql.adaptive.enabled设置为true。
3.spark.sql.adaptive.skewJoin.skewedPartitionFactor :倾斜因子,如果分区的数据量大于 此因子乘以分区的中位数,并且也大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes,那么认为是数据倾斜的,默认值为5
4.spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes:每个分区的阀值,默认256mb,此参数应该大于spark.sql.adaptive.advisoryPartitionSizeInBytes
5.spark.sql.adaptive.advisoryPartitionSizeInBytes:缩小分区或进行拆分分区操作后所期望的每个分区的大小(数据量)。
spark AQE、动态申请资源: 当计算过程中资源不足会自动申请资源
spark.sql.adaptive.enabled: 是否开启AQE优化
spark.dynamicAllocation.enabled: 是否开启动态资源申请
spark.dynamicAllocation.shuffleTracking.enabled: 是否开启shuffle状态跟踪。为执行程序启用随机文件跟踪,从而无需外部随机服务即可动态分配。 此选项将尝试保持为活动作业存储随机数据的执行程序。
spark.dynamicAllocation.shuffleTracking.timeout 启用随机跟踪时,控制保存随机数据的执行程序的超时。 默认值意味着Spark将依靠垃圾回收中的shuffle来释放执行程序。 如果由于某种原因垃圾回收无法足够快地清理随机数据,则此选项可用于控制执行者何时超时,即使它们正在存储随机数据。
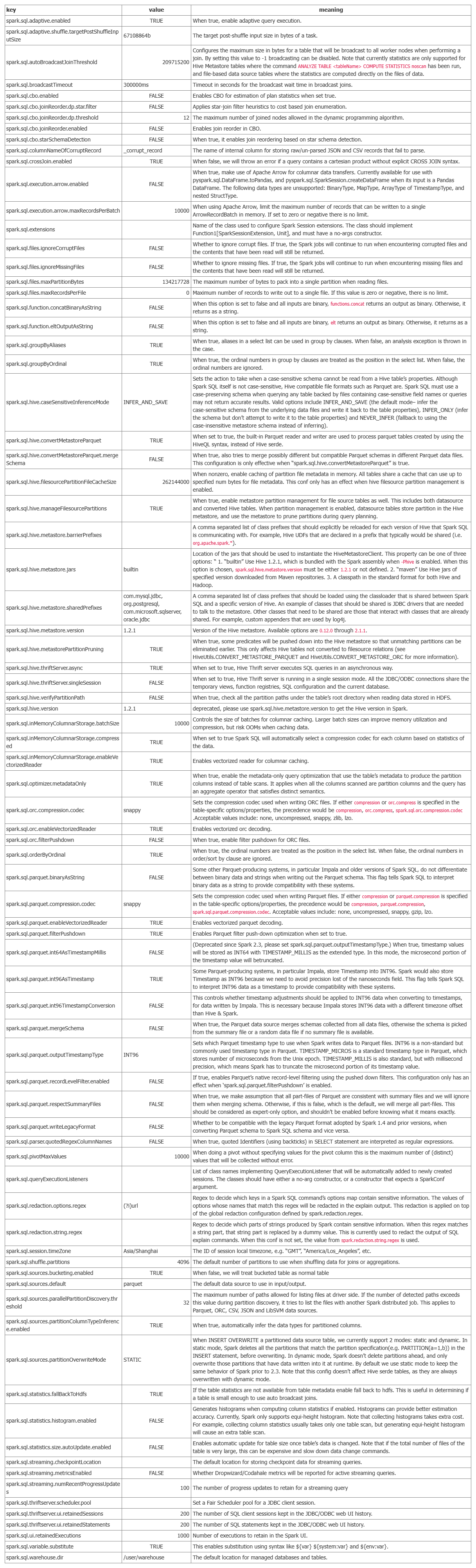
Spark Sql 参数表(spark-2.3.2)
本文由 mdnice 多平台发布

















 2182
2182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









