







行业规矩,开始放出标题论文的原地址
https://openaccess.thecvf.com/content/CVPR2022/papers/Yang_Focal_and_Global_Knowledge_Distillation_for_Detectors_CVPR_2022_paper.pdf
首先如果没有知识蒸馏基础建议阅读2015年Hiton大佬首次提出的神经网络汇总“知识蒸馏”的正式理念,对“知识蒸馏”如何应用在神经网络中首次有个总结性、完整性的概念。
 论文的地址如下
论文的地址如下
https://arxiv.org/abs/1503.02531v1
内容简介就是首次提出了神经网络中的知识蒸馏。通过引入与教师网络(Teacher network:复杂、但预测精度优越)以诱导学生网络(Student network:精简、低复杂度,更适合推理部署)的训练,实现知识迁移(Knowledge transfer)。其次利用性能更好的大模型的监督信息,来训练这个小模型,以期达到更好的性能和精度。简单概括利用来自 教师网络模型经过全连接层softmax输出概率指导学生网络全连接softmax输出概率,从而达到损失值最小。
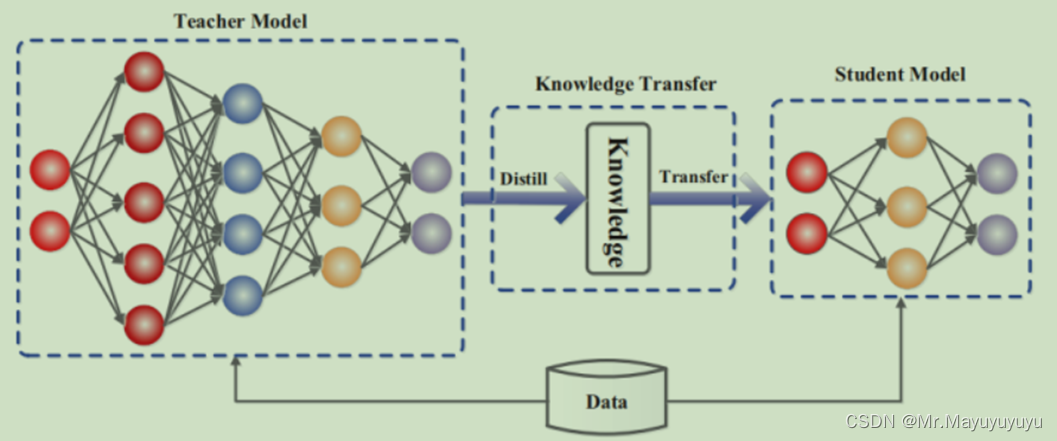
Focal and Global Knowledge Distillation for Detectors

1 研究目的
知识蒸馏目前能够应用于图像分类的方向,但是对于目标检测来说就要复杂的多,大多数的知识蒸馏的方法都失败了。而所研读的文章主要就是研究目标检测中的知识蒸馏的应用。
在目标检测中,教师与学生的特征在不同的区域有着很大的不同,特别是在前景与背景中。
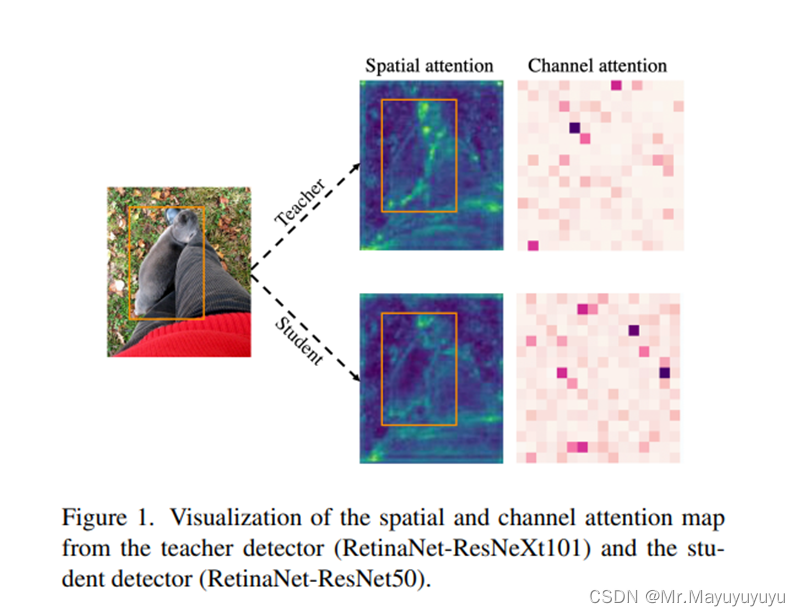
如果在模型对图片训练中直接对所检测的图片的特征进行平均的特征提取,那么特征图之间的不均匀差异就会对蒸馏产生负面影响。所以在此基础上,就提出了Focal and Global Distillation(FGD)。聚焦蒸馏分离了前景与背景,迫使学生网络关注教师网络的关键像素和通道。而全局蒸馏则重建了不同像素之间的关系,并将其从教师转移到学生网络上。由于此方法只需要计算特征图上的损失,FGD可以应用于各种检测模型。在不同的模型上的实验也能证明要比基准的模型高出2-3个点。
消融实验如果是对一张训练图片整体进行知识蒸馏就会导致蒸馏效果下降,如果将前景与背景分开进行蒸馏就会得到更好的表现。
所以针对以上问题本文就提出了Focal and Global Distillation(FGD)
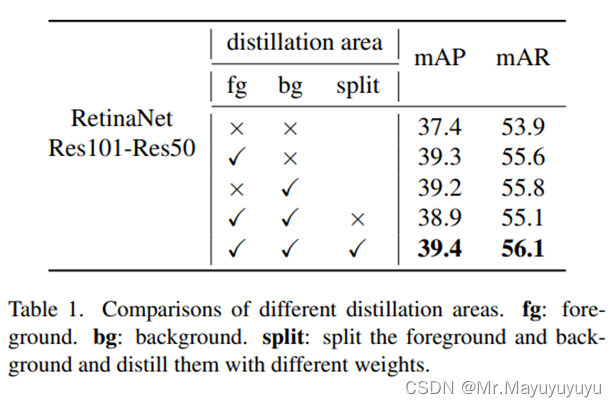
2 技术创新
1.教师网络和学生网络所关注的像素和通道是完全不同的。如果不加区分地提炼出这些像素和通道,导致效果不佳。
2.聚焦和全局知识提炼,这使学生网络不仅能够关注每个关键像素和通道,而且还能学习像素之间的关系。
3.通过在COCO数据集上的大量实验验证了方法在各种模型上的有效性,包括单阶段、双阶段、无锚点的方法,取得了最先进的性能。
3 主要方法
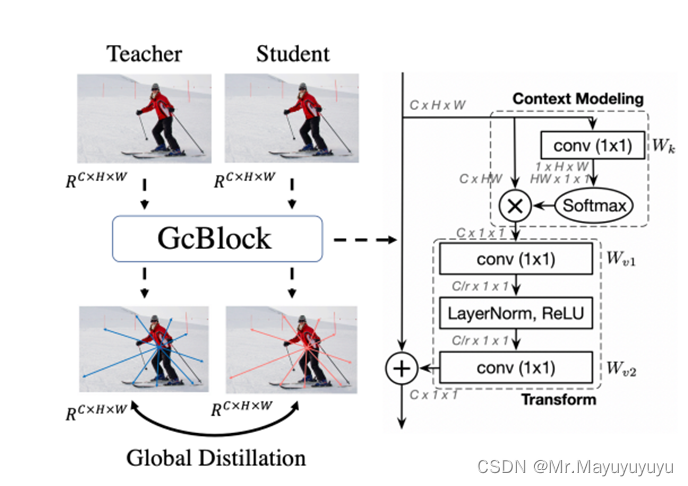
FGD的框架图如图1所示。
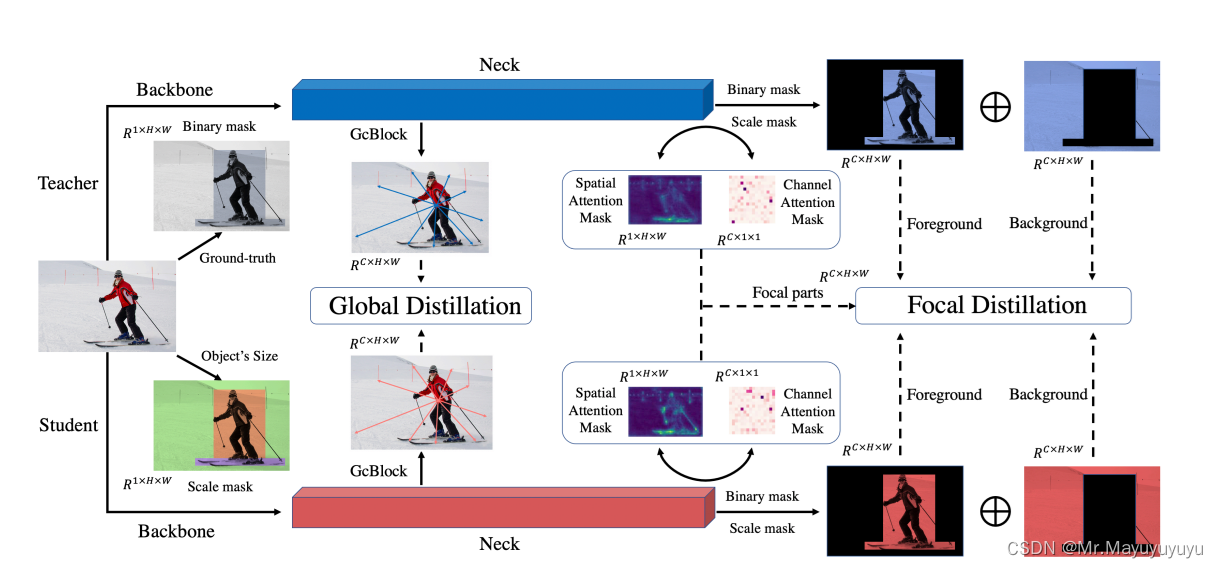
图1 Focal and Global Knowledge Distillation(FGD)架构图
大多数检测器都使用FPN来利用多尺度的语义信息。来自FPN不同层次的骨干语义信息的特征,被用来直接预测。将这些特征的知识从教师网络转移过来,大大改善了学生网络。但是这种方法对所有的部分都一视同仁,缺乏对不同像素之间的全局关系的提炼。缺乏对不同像素之间全局关系的表现。
3.1 聚焦蒸馏
主要解决的是前景与背景的不平衡,让学生网络主要关注关键像素和通道。与其他对知识1提炼方法效果对比图如图1所示。
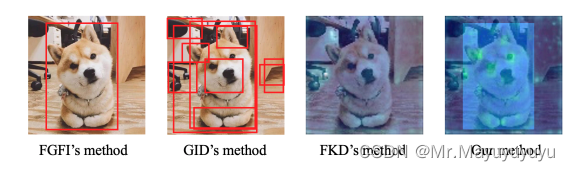
图1 效果对比图
首先设置一个二进制掩膜。掩膜在深度学习中可以用于:
提取感兴趣区:用预先制作的感兴趣区掩膜与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0;
屏蔽作用:用掩膜对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计;
结构特征提取:用相似性变量或图像匹配方法检测和提取图像中与掩膜相似的结构特征;
特殊形状图像的制作
对于图片中前景与背景的区别使用公式1表示。公式主要对背景与前景进行判定,是前景置为1否则置0。

对于不同的目标前后背景的损失平衡,使用函数使用公式2表示。主要是为了平等对待不同的目标并平衡前景和背景的损失。尺度掩膜S表示为:
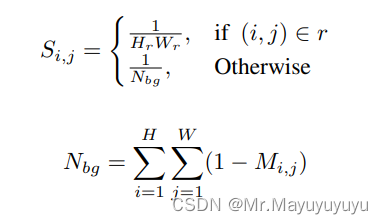
论文还是使用一个简单的方法来获得空间注意力掩码并提高蒸馏的性能。在本文中,应用类似的方法来选择焦点像素和通道,然后得到相应的注意力掩码并且计算了不同像素和不同通道上的绝对均值。
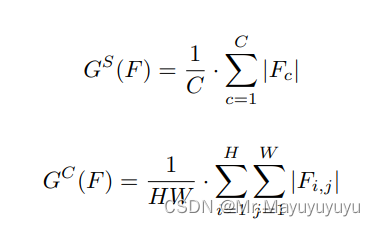
GS和GC是空间和通道的注意力表示。那么,注意力掩膜可以表述为:
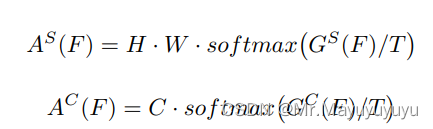
综上所述的三个核心部分

公式中,其中T就是Hiton在知识蒸馏中所指的超参数温度T,用于提高学生网络能够学习到更多的特征知识,即为了提高学生网络的鲁棒性。
AS和AC表示教师网络的空间和通道注意力掩码。在训练过程中,就是用教师网络来指导训练学生网络。使用二进制掩码M,尺度掩码S,注意力掩码AS和AC,特征损失定义为:
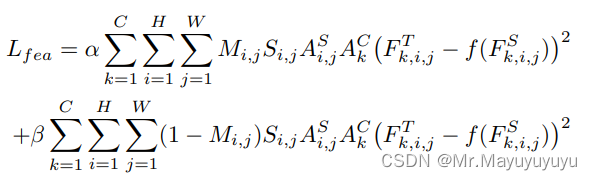
FT,FS分别表示教师网络和学生网络的特征图,α和β是超参数,用于平衡前景与背景的损失。此外使用注意力损失Lat来强迫学生网络模仿教师网络的空间注意力和通道注意力。教师网络的空间和通道注意力公式如下:
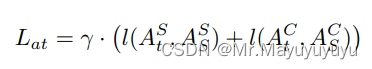
其中t和s表示教师和学生。l表示L1损失,γ是一个超参数,用于平衡损失。焦点损失Lfocal是特征损失Lat和注意力损失Lat的总和。注意力损失Lat:
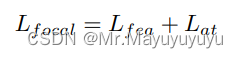
3.2 全局蒸馏
利用焦点提炼法来分离图像,迫使学生将注意力集中在关键部分。然而,这种提炼方法切断了前景和背景之间的关系。前景和背景之间的关系。有了全局蒸馏,旨在从特征图中提取不同像素之间的全局关系。它旨在从特征图中提取不同像素之间的全局关系,并将其从老师那里提炼出来并将其从教师网络蒸馏至学生网络。
全局蒸馏的损失计算:
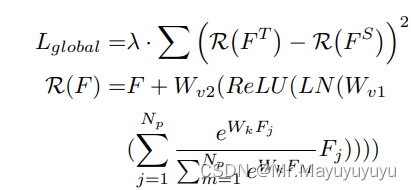
Wk、Wv1和Wv2表示卷积层,LN表示层的归一化,Np是特征中的像素数。λ是一个超参数,用于平衡损失。
那么总体的损失计算:
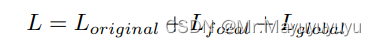
使用Gc Block来进行全局蒸馏。
Gc Block使用的是NL Block与SE Block的结合。
NL Block捕获远距离依赖性有益于各种识别任务,而传统的卷积神经网络中,卷积层在局部区域建立像素关系,远距离依赖只能通过堆叠卷积层来进行建模。但是该方法的计算量大且效率低下。该方法可以捕获远程依赖关系,并通过注意力机制进行建模。
SE Block基本构成是由Squeeze操作和Excitation操作构成。Squeeze操作将一个channel上整个空间特征编码为一个全局特征,采用global average pooling来实现。Excitation操作可以看成学习到了各个channel的权重系数,从而使得模型对各个channel的特征更有辨别能力,这也算一种attention机制。
聚焦蒸馏与全局蒸馏可以通过模仿更强的基于骨干的教师检测器的特征图,获得了更好的特征,
3.3 试验效果
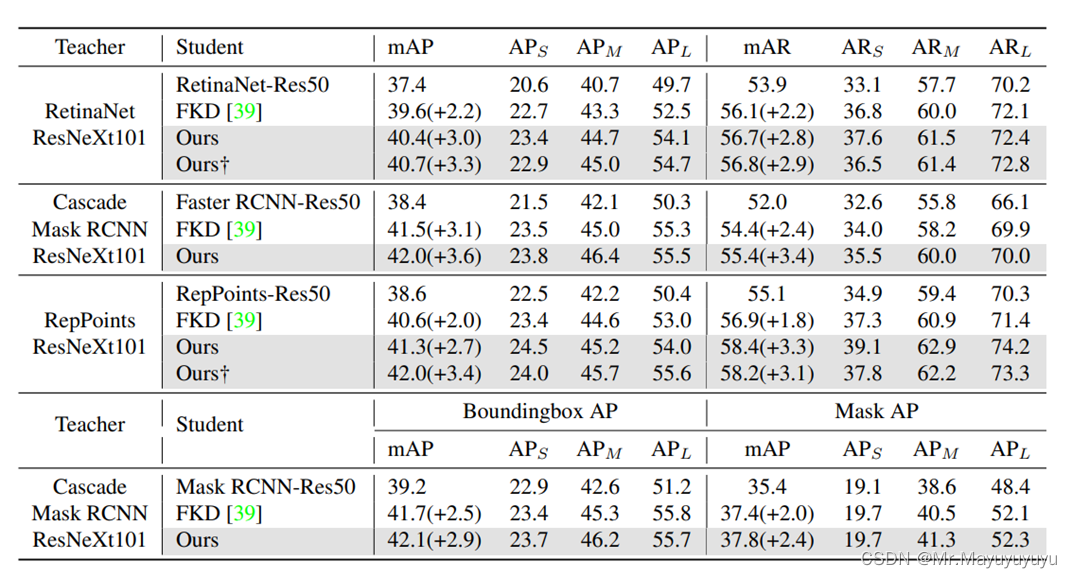
4 应用场景
本文加深了对知识蒸馏的研究,从而使知识蒸馏在对图片进行处理时,通过通道注意力与空间注意力提高度图片特征的提取,从而使教师网络、学生网络对目标的识别得到加强,对原有的模型进行优化,从而使其能够在在移动端、笔记本电脑、无人驾驶汽车、嵌入式终端设备如安防监控等算力相对较小的设备进行部署。















 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









