







十大算法介绍
C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, CART
这十大算法包含了分类、聚类、统计学习、关联分析、联系发现(Link Mining)这几个数据挖掘行业内的重头戏
附录一个连接包含了很多算法的论文 点击这里
这十大算法…估计大部分人都听过,作为菜鸟在数据挖掘领域胡乱蹦跶了好久,看过了好多视频,看过了好多博客,但是最后才发现过不了几天还是会忘记。现在想来,大概是没有真的理解内在的含义以及从来没有把他们应用在实际中吧,所以,想要写一个自己的笔记,用于备忘,这样以后就算模糊了,也能用最短的时间找回来。另外关于本博客中引用了他人博客内容的地方,我全都列在参考中。最后,首推清华大学袁博老师的数据挖掘课程,讲的非常浅显易懂,太厉害了!本文的行文思路也是按照他的授课内容来的。
一、监督式学习和分类
1.1分类

在这张图中,我们可以看到各种各样的鱼类,我们识别这些鱼类的过程就是分类。
抽象的说:分类问题就是,给定了一个数据集,我们利用某种方法推导出了一个函数(function),接着,我们给这个函数输入(input),函数返回给我们结果(output)。
Input: a vector of features
Output: a Boolean value (binary classification) or integer (multiclass)
另外,所谓分类,其实是一种supervised learning
1.2监督式学习(supervised learning)
那么何为supervised learning?
举个栗子:一伙人参观动物园,老师带队,看到一个体表布满花纹、额头上有个近似“王”字图案的动物。老师说:“这是老虎”,于是大家都记住了老虎长什么样。
上述过程就是一个监督式学习的过程,input = (动物,体表布满花纹,额头上有个近似“王”字图案),output = (老虎)
所以,所谓的supervised其实就是要有老师给你打标签。
二、贝叶斯公式和几个例子
2.1贝叶斯定理
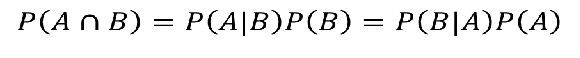
这个公式,相信大家都不陌生,表示的是事件A和事件B同时发生的概率用这个公式,我们就能推导出贝叶斯公式,形式如下:
贝叶斯公式其实描述的是一种后验概率。
P(A)是A的先验概率或边缘概率。之所以称为”先验”是因為它不考虑任何B方面的因素。
P(A|B)是已知B发生后A的条件概率(直白来讲,就是先有B而后=>才有A),也由于得自B的取值而被称作A的后验概率。
P(B|A)是已知A发生后B的条件概率(直白来讲,就是先有A而后=>才有B),也由于得自A的取值而被称作B的后验概率。
P(B)是B的先验概率或边缘概率,也作标准化常量(normalized constant)。
2.2一个栗子
就用我们学了N多年的射击栗子来试试贝叶斯公式吧!

A,B二人同时朝着同一个目标射击,其中A射中目标的概率 P(A)=0.6 ,B射中目标的概率 P(B)=0.5 现在已知目标被击中,问目标被A击中的概率是多少?
解:设事件C表示目标被击中,所以有 P(A|C)=P(C|A)P(A)P(C)
P(C)=P(A¯)P(B)+P(A)P(B¯)+P(A)P(B)=0.4×0.5+0.6×0.5+0.6×0.5=0.8
P(C|A)P(A)=1×0.6=0.6
所以 P(A|C)=34
三、朴素贝叶斯分类器(Naive Bayes Classifier)
3.1朴素贝叶斯分类器介绍
用贝叶斯做分类器最大的一个特点就是——它强调的是概率,其实就是要计算一个后验概率。
比如:当我们有一组观察特征 a1,a2,...an 的时候,要我们去判断这个人是男是女,其中 ω1=男,ω2=女 ,这时候我们就是把这些特征带进去,接着计算他们的后验概率, 选择后验概率较大的作为输出结果。
那么这个后验概率该怎么计算呢?
MAP: Maximum A Posterior
我们用贝叶斯公式展开!
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5714
5714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









