






挑战火热数据库,7天一篇CHARLS!全新的挑战,全新的旅程!
前面多期关于MR、GBD、NHANES等挑战反响空前。最近一直在整理CHARLS相关的资料,我们即将开始挖掘新的数据库:中国人自己的database--CHARLS数据库
和之前的代谢MR、蛋白组学MR、NHANES一样,我们给提前做了一些数据清洗的准备工作,我们也开始一期新的挑战,期待师弟师妹们能挖掘出新的paper!
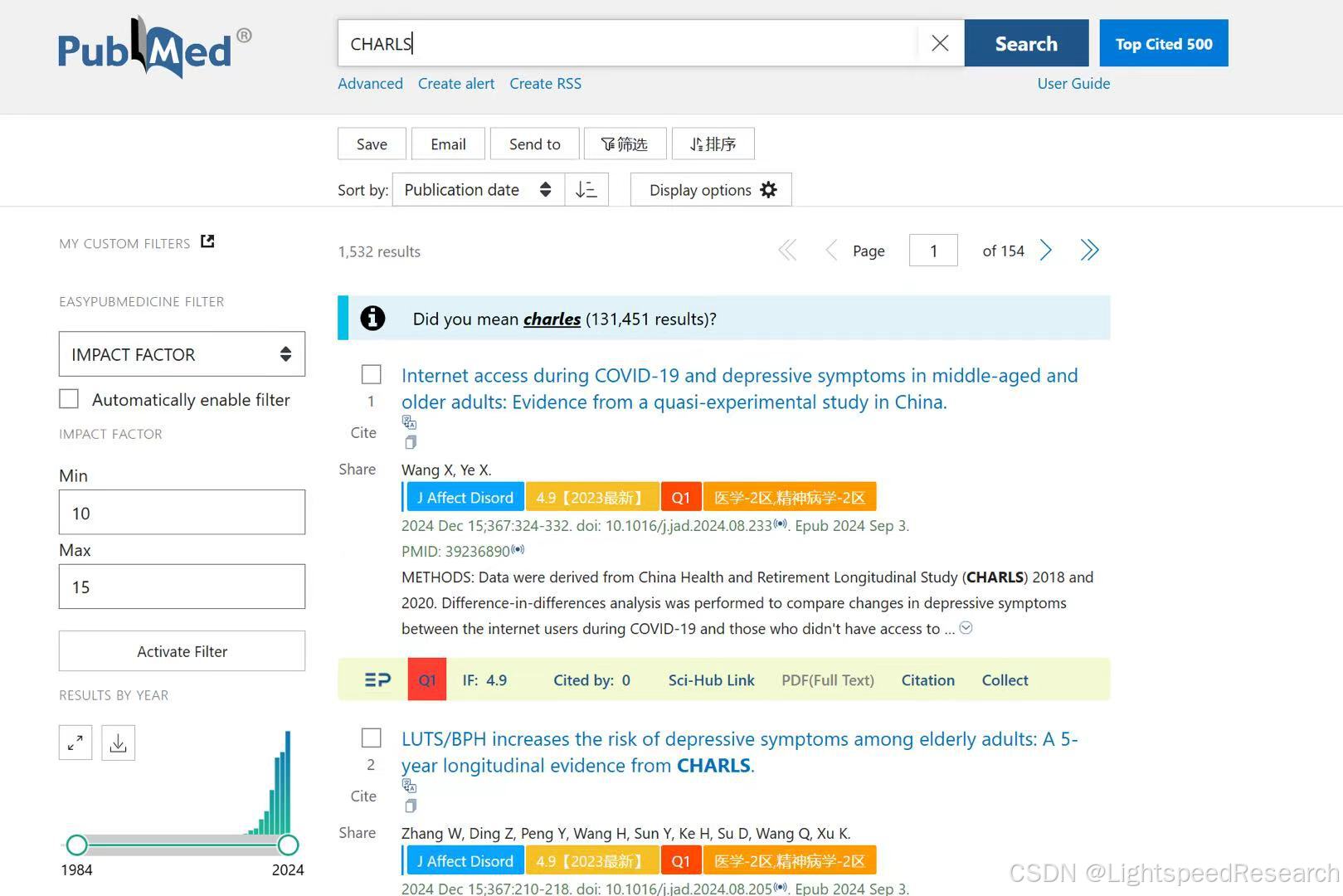
CHARLS数据库最近有多火呢?我们进行了最简单的检索,发现发文质量普遍较高,而且还没哟老外来抢挖我们的数据,这是因为就目前而言这个数据库的挖掘程度还不够,相比较于NHANES来说普及程度还比较“弱”,那对我们来说就是极好的机会。让我们一起高效完成一篇CHARLS数据库SCI!
Day1!
Day1任务:确定目标文献和目标期刊
大家可能对CHARLS还不是很熟悉,我们进行一个简单的介绍,CHARLS(中国健康与养老追踪调查),旨在收集一套代表中国45岁及以上中老年人家庭和个人的高质量微观数据,用以分析我国人口老龄化问题,推动老龄化问题的跨学科研究。
这是实际上和NHANES的调查比较类似,但是又有不同,最大的不同就是NHANES是横断面调查,CHARLS是有纵向随访数据,搞过临床研究的都知道。纵向随访数据多么的难得啊!!!这岁我们来说就是莫大的机会。这也就意味着,如果我通过NHANES写了一篇横断面。我相同的指标在CHARLS上进行一定的随访依旧能写一篇好文章
我去初略的检索了CHARLS,总共有1532 结果,而且基本集中在最近几年,也是因为这个数据库的火热才刚刚开始,我们一定要抓住这波机会、弯道超车。因为我是心内科的,所以我选择了
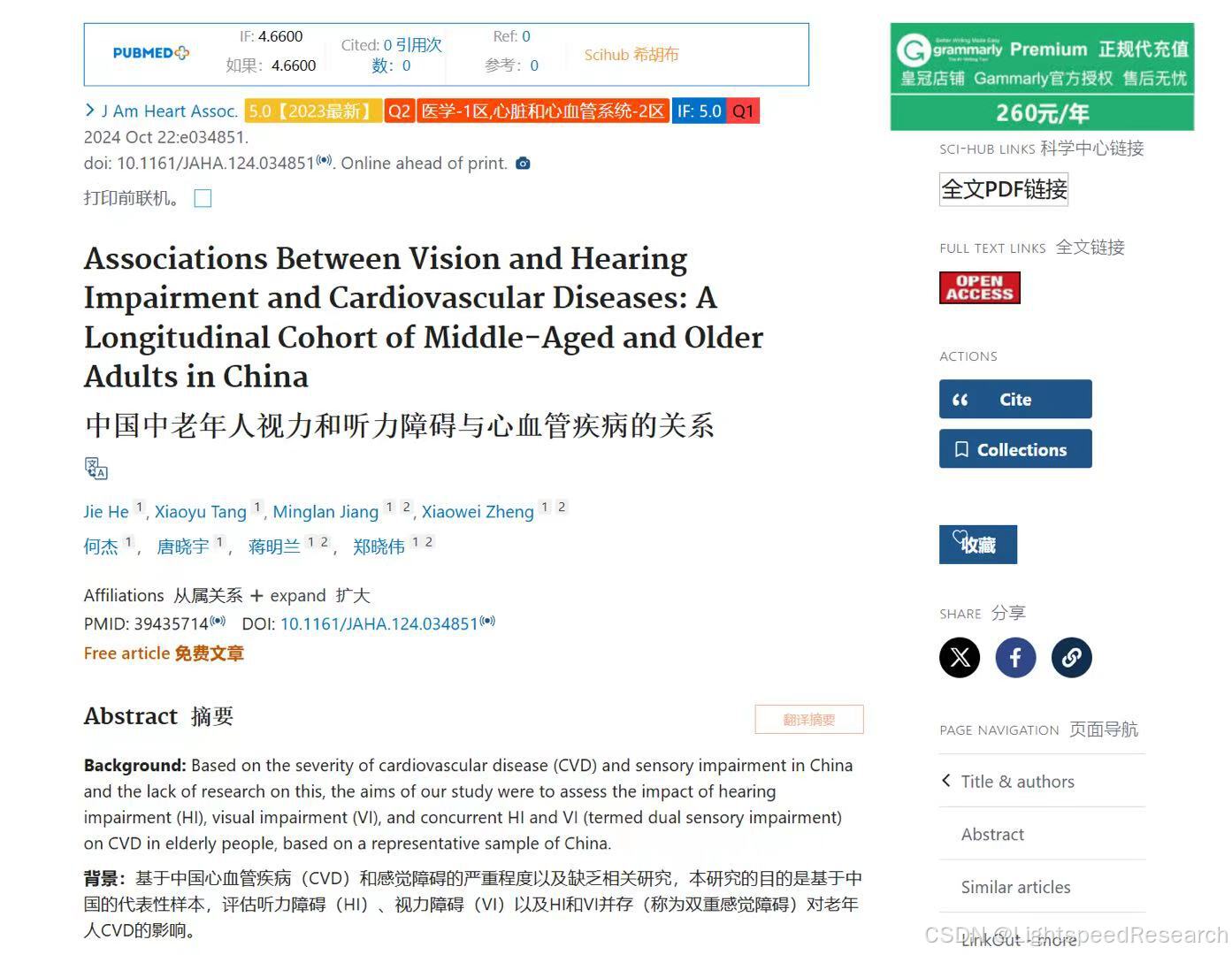
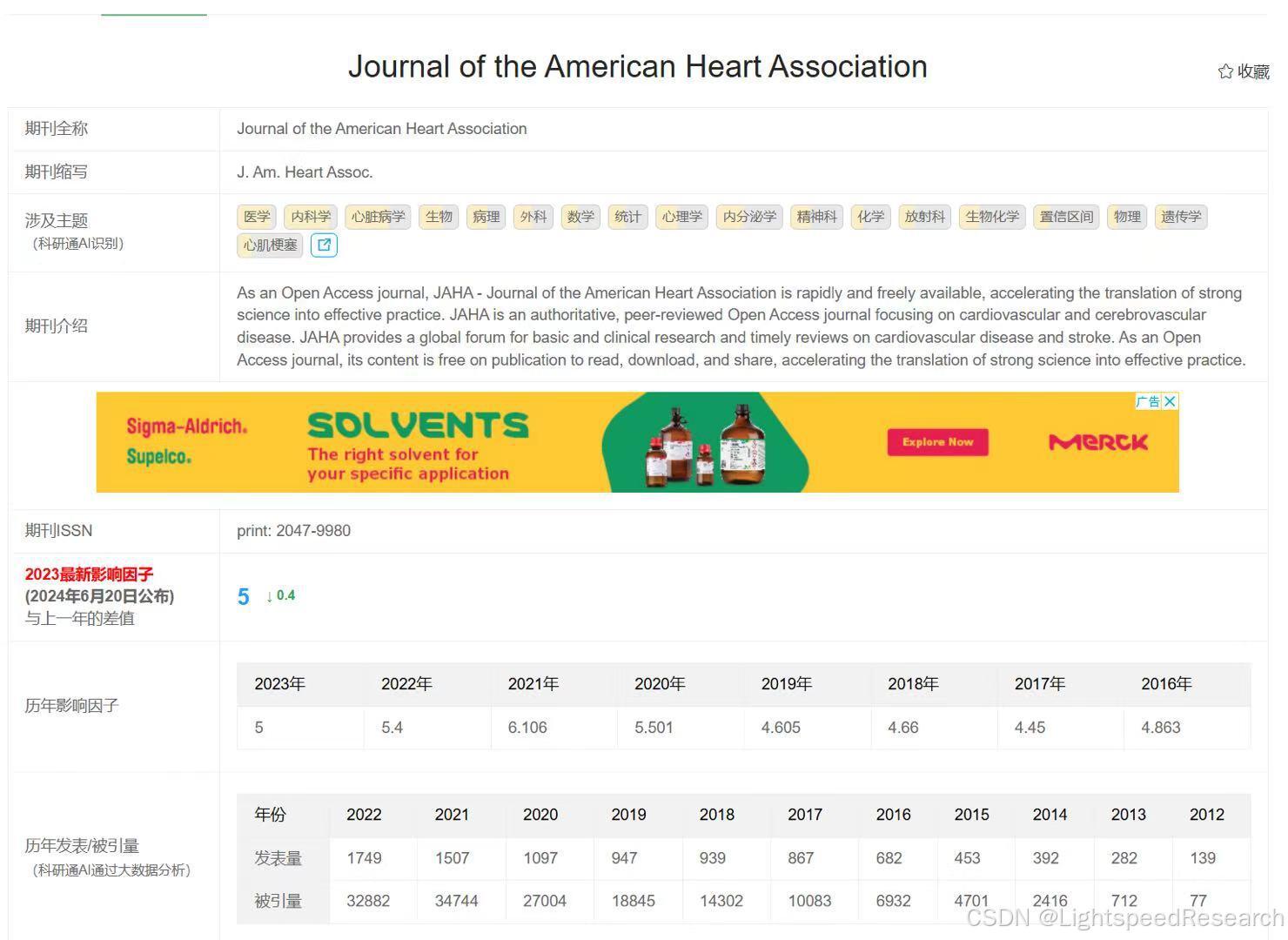
目标期刊:Journal of the American Heart Association
目标文献:中国中老年人视力和听力障碍与心血管疾病的关系
这就是我之前给到大家讲到的关于一些比较罕见的特殊暴露。努力挑战,一定能成功
全力以赴,冲锋冲锋!


Day2-3
Day 2-3任务:可行性分析
数据库的挖掘,不管是哪一个数据库。最难的不是后面的数据分析,后面的数据分析过程都是一模一样的。相信师弟师妹们经过前面那么多的挑战都有了自己体会。而且我们给大家的观点是:任何方法学的内容你一定可以掌握。但是:为什么选这个选题?
大家一定要重视平时的文献阅读、记录自己的科研idea,对自己的这个想法进行可行性分析。无非就是:可操作性如何?涉及到的方法学有那些?其实就是我去复现一篇一模一样的文章。我能不能都画出所有的Figure、做出所有的Table,这篇文献中都使用了哪些分析方法,我能不能1:1实现?方法学的内容基本可以完全复刻NHANES。无非是数据来源不一样+纵向随访,我们有能力解决任何代码问题
通过目标文献的阅读,我们发现文章主题:
--基线资料表
--Kaplan-Meier曲线
--感觉障碍与新发CVD之间的关系
--亚组分析
搞清楚了我们需要什么、需要什么样的数据分析技能,很简单就能得到Figure和Table,随后利用独创的框架写作法进行写作就显得十分的容易和得心应手
挑战继续!

Day4-5
Day 4-5任务:完成核心表格和图片
这两天主要任务是数据清洗(已经清洗好了)+数据分析(作图+做表)
数据库最难的、最费时间的就是数据清洗了。我们之前花了大量的时间进行数据清洗,现在来说也是非常方便的了,所以就是:数据库是个宝只,要数据清晰,怎么挖都是paper
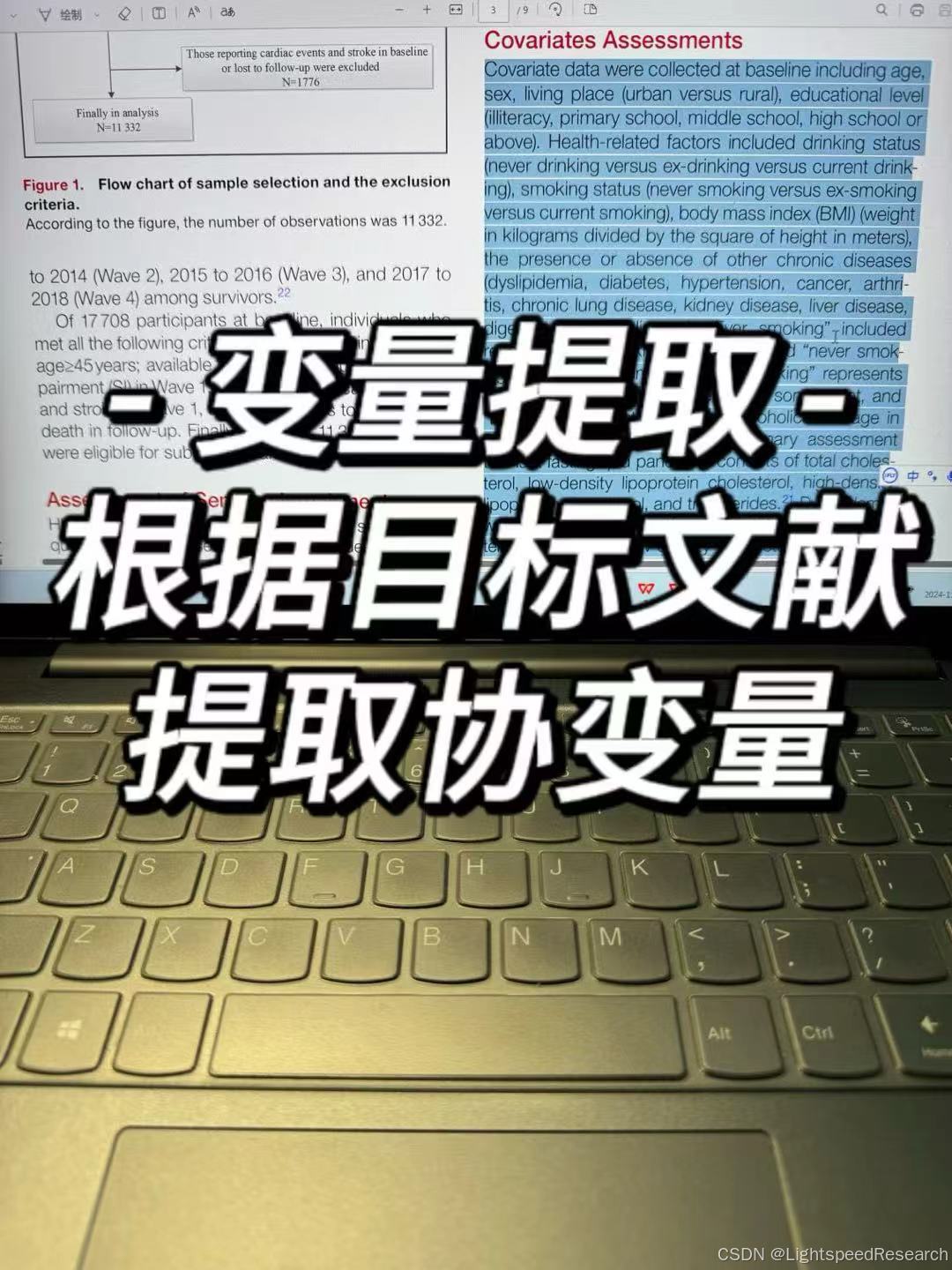
那问题来了,怎么确定我的文章中需要什么数据?这就回到Day 1的时候目标文献的确定。因为我们关注的都是CVD这个人群,所以很多的协变量基本不会发生太大的变化 ,只是自变量的X这个指标会不一样,阅读高质量文献的重要性这个时候及凸显出来了。
协变量从既往的文献中获得:文章中都详细的说明了每一种变量的定义,这也是我们在写文章的时候需要放的内容,对于变量的定义来说有一些是要按照常规,一些也可以自己定义。不管是那种方式,都一定要十分的清晰。单独的变量还是数据组成的复合变量
然后就是使用数据的提取和合并,这需要一些时间整理成可以直接分析的数据
今天的所有表格和图片通过基础代码包很快就完成了,明天就要开启写作内容啦!




Day 5!
Day 5:完成文章中的Table和Figure
数据已经整理好了,那后面就是数据分析。做出Table和Figure,其实有了前面NHANES数据库处理的基础后。这种类型的文章内容基本是类似的。
Figure 1:研究人群
Table 1:基线资料表
Table 2:回归分析
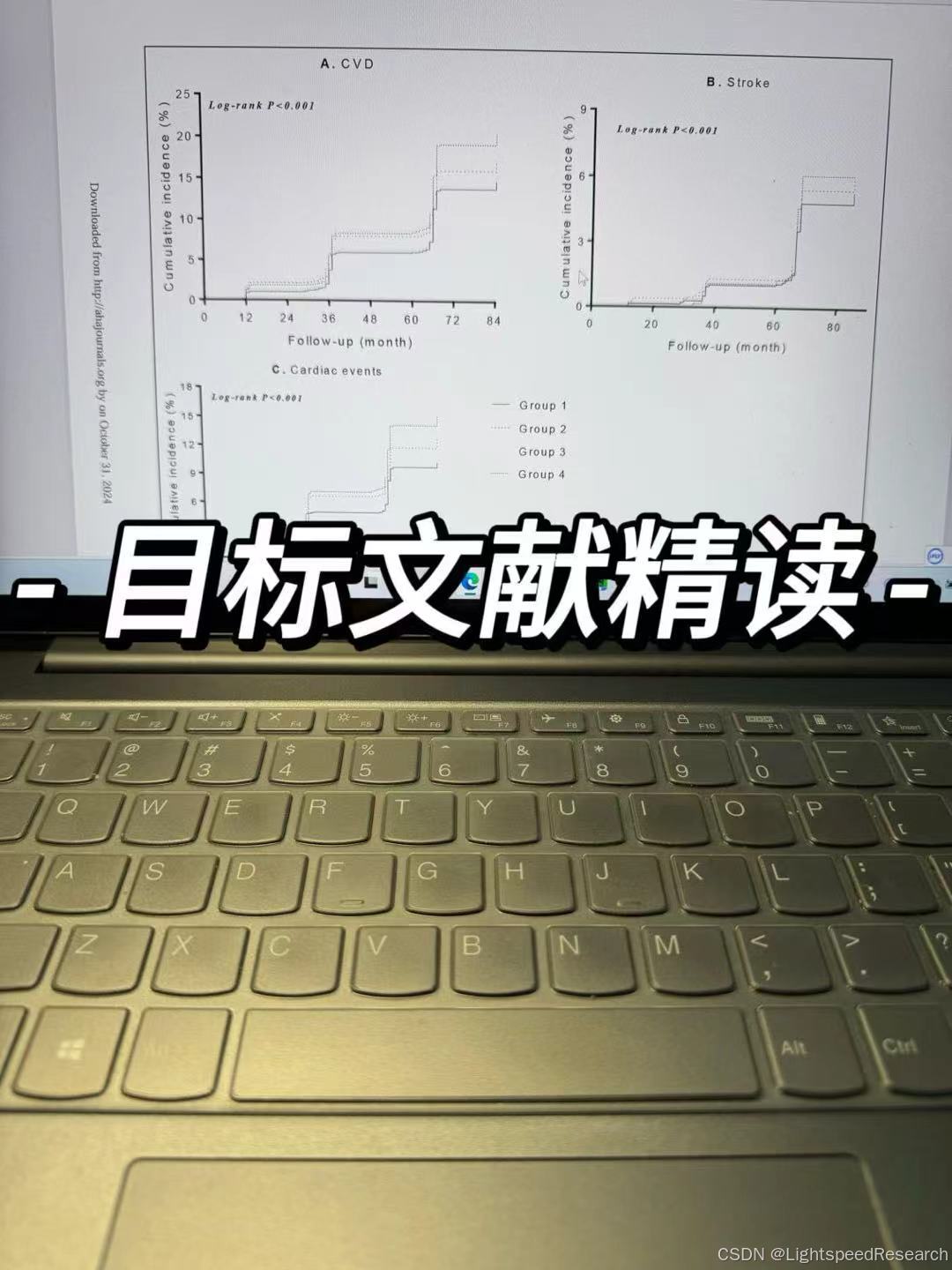
Figure 2:RCS
Table 3:亚组分析
如果有问题的话,可以找一篇NHANES或者CHARLS的文献仔细品读。整篇文章的核心就是回归分析(到底有没有关系?)和RCS曲线(如果有关系,是什么样的剂量效应关系?)。
我们按照目标范文中的内容一步一步的做就好啦,通过这么久的实践来说只要数据清洗好了个把小时就能得到所有的图片,大家也会发现数据库的结构和数据的清洗是最费时间的
但是,哪又有那么容易中一篇文章呢?安下心来,静下来一定能出成果,我们已经整理好了所有的CHSRLS数据。今日份挑战成功!
Day 6-7!
Day 6-7任务:光速写作
昨日经过一晚上的战斗,已经完成了文章中的所有Table和Figure,同时我也把文章中的Methods和Results部分写完了。因为包括协变量的定义的内容我在前面变量提取的时候就已经写好了,所以就省事儿很多,后面就是写作。写作其实是最简单的部分
因为“没有任何一篇文章会因为写作问题而拒绝你”,我们早期话费了大量的精力创建了“框架写作法”,快速写出一篇高质量的文章并不复杂
以结果为导向,如何高效快速的写出SCI论文是关键中的关键。1天基本就完成主题引言、讨论部分的初稿,然后再1天完成模板化板块写作、翻译、润色、投稿前准备,然后把图片和表格放在以合适的方式放在合适的位置,然后模仿我的目标文献就好啦!
挑战7天完成一篇CHARLS,挑战成功!期待继续关注!
前面有师弟师妹们再私戳!
我们对于公开数据库(MR、NHANES、GBD、CHARLS等等)有一套光速科研体系
一起加油~~!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









