







Day 1!
今天我要发起一个崭新的挑战,就是在7天内完成一篇利用NHANES数据库的SCI论文!今天的主要任务是进行初步检索并确定目标期刊。
NHANES数据库,全称National Health and Nutrition Examination Survey,是一项基于人群的横断面调查,旨在收集有关美国家庭人口健康和营养的信息。每年,该项目会对一个全国代表性的样本进行调查,涵盖约5000人。NHANES的访谈部分包括人口统计学、社会经济学、饮食和健康相关问题,而体检部分则包括生理测量和实验室检查等内容。数据量庞大,涉及的相关指标极多,适合各个科室的朋友来挖掘写作,因此近年来备受关注,我也想试试水,哈哈。
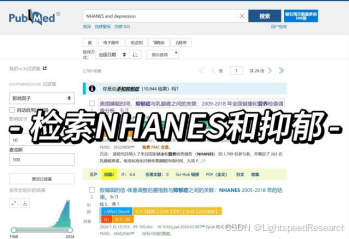
我首先简单使用关键词“NHANES”进行了初步检索,发现目前已有大量相关文章,其中不乏高质量的作品。仔细观察后发现,大部分高分文章集中在5分到10分之间,并且多数发表在一区和二区期刊上,这个情况还是挺不错的。由于最近我对抑郁症比较感兴趣,于是我尝试了搜索“NHANES and depression”,发现相关文章的数量和质量都令人满意,因此我决定就从这个方向入手。
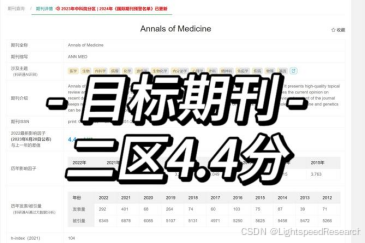
第一篇文章是复旦大学最新的抑郁研究成果,后续的文章都出自我们之前调研过的《情感障碍杂志》,但考虑到新的目标,我决定换个目标期刊——我的目标文章是一篇发表在《医学年鉴》上的作品(DOI: 10.1080/07853890.2024.2314235)。
之后我对《医学年鉴》进行了更深入的了解,发现它并非水刊,发文量和被引数都相当可观,于是就决定了这个目标。
接着我检索了之前就有些关注的血液指标,发现它与抑郁症之间的关系还没有被充分研究过,这可是一个不错的研究方向,嘿嘿。
好了,让我们一起来探索NHANES数据库吧!期待未来的7天,一起迎接这个挑战!

Day 2!
我的新挑战继续进行~
第2天的主要任务是了解数据库。
NHANES数据库一听名字就知道和我们的MIMIC、eICU一样是一个公开数据库,但与众不同的是,NHANES的数据获取相对来说更加简便,也就是说可以非常方便地下载到原始数据,对我们这些“临床牛马”来说是非常有利的。之前尝试过搞MIMIC,但由于数据量庞大,本地安装数据库花费了很长时间,NHANES就没有这个烦恼,可以轻松上手。
利用公开数据库发表文章,最重要的就是要了解数据库的数据组成,知道它包含哪些数据,这样才能确定可以利用哪些数据进行构思。NHANES是关于健康和营养调查的横断面调查。从官方网站上我们可以看到,数据库内容非常丰富。
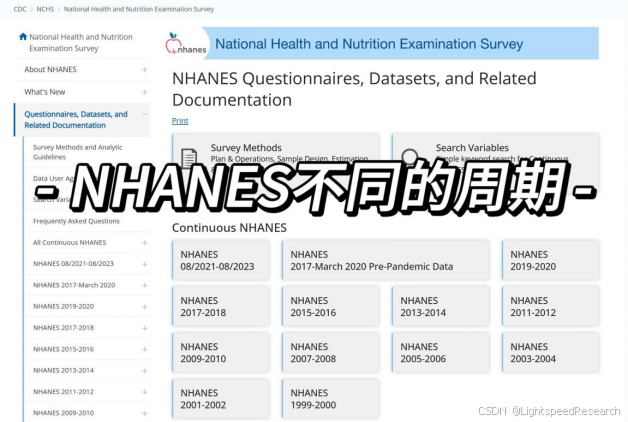
NHANES数据库包含了不同年份的数据,比如“2013-2014”,我们称之为一个周期,因为NHANES每两年上传一次相关数据。每个周期里包含了大量的数据,但我们主要利用的是Data、Documentation、Codebooks,其中包括人口统计学、饮食数据、体格检查、实验室数据、问卷调查和Limited Access Data,而我们最常用的是前五个。Limited Access Data需要申请批准后才能使用。
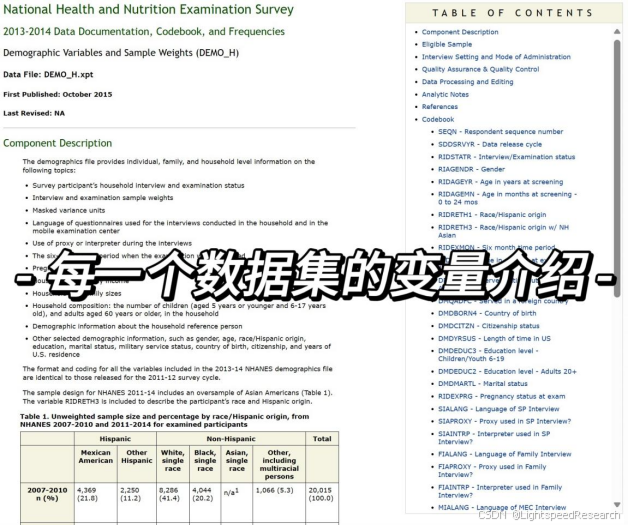
点击进入后,我们可以看到Doc File和Data File,通过Doc File我们可以了解这个数据集的基本情况,点击Data File就能下载数据,然后利用R或者SPSS等软件打开这个XPT格式的数据集文件。
因为后面会用到NHANES里的数据,所以我花了一些时间将所有周期的数据全部下载下来,这个工作量还是相当可观的。
好了,今天的分享就到这里啦!期待明天的继续探索!


Day 3-4!
进度汇报:数据下载+数据清洗。
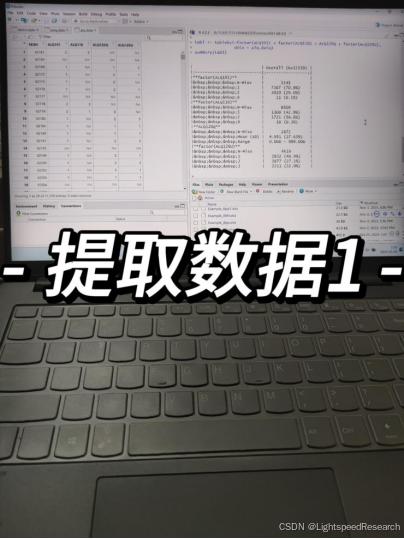
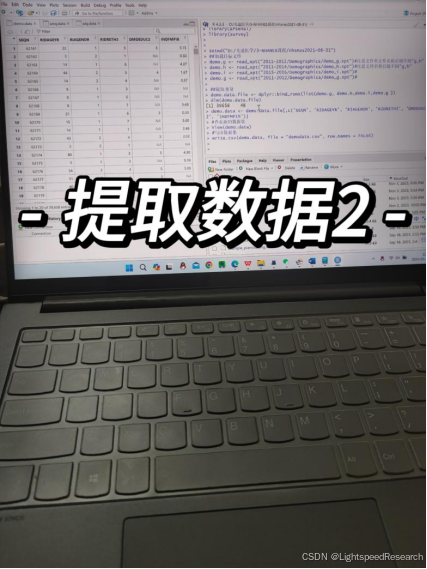
在Day 2,我已经将所有的数据都下载好了,现在就是数据清洗的时候了。对于任何一个公开数据库来说,数据清洗都是最为费时费力的一环,但也是非常关键的步骤。我打算使用R来处理相关的数据,这样获取的数据可以用来构建一个自己的数据库。只要换个指标、换个研究人群,就又能有一篇新的文章诞生。
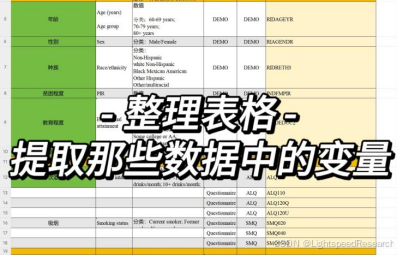
在开始提取变量之前,我们需要明确需要提取哪些数据。我特别关注的指标包括:年龄、性别、种族、教育程度、婚姻状况、贫困收入比率、体重指数(BMI)、肾小球滤过率(eGFR)、睡眠持续时间、饮酒、吸烟状况、心血管疾病、高血压、糖尿病、高脂血症和抗抑郁药使用等。确定需要提取的变量是关键的一步,而这些协变量的选择可以根据既往的文献中获得。数据提取是公开数据库中最耗时的环节之一,但有了代码的帮助,也能够顺利进行,毕竟一篇二区的文章也不是易如反掌的。
通过代码的提取,我终于在两天的时间内完成了数据清洗工作。有些变量看起来似乎只有是或否的情况,但实际上其定义却有很多细节。举个例子,对于高血压来说,定义不仅包括目前是否正在口服降压药或者血压是否超过了140/90mmHg,而且还需要考虑血压值的测量方式等。这就意味着需要提取更多的数据来综合组成这个协变量。这一工程的确是相当浩大的。
只要数据清洗完成,后续的工作就变得相对简单,没有什么复杂和困难的。而重点就在于选题(选择指标和idea)以及数据提取这两个方面。这也是我花了很多时间进行初步检索并确定目标期刊、选题的意义所在。在开始研究之前,一定要慎重考虑,千万不要一来就急于开跑。
一起加油吧!期待明天的进一步进展!


Day 5!
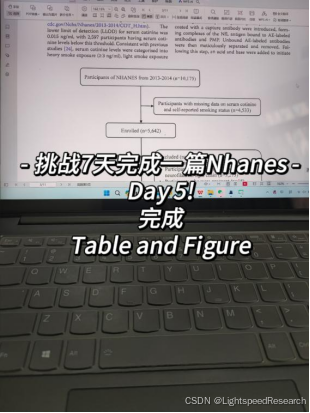
进度汇报:完成Table和Figure。
经过数据的整理,接下来的任务是制作Table和Figure。在开始具体操作之前,我再次翻阅了相关文献,以模仿文献的思路来进行操作。NHANES文章的常规流程通常包括以下几个步骤,当然,也会有一些文章采用了其他处理方法,比如机器学习,但本质上还是一样的思路,只不过在数据的选择和分析方法上会有一些差异。在刚开始的时候,我们可以先学会最简单的思路,之后再逐步学习和挑战其他方法。
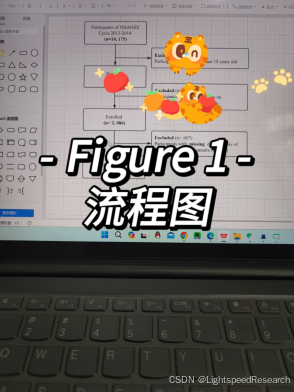
Figure 1:研究人群的数据来源过程。这个图表简要说明了我们筛选数据的流程,比如在2013-2014年,总共有10175例数据,根据我的纳入条件进行筛选和排除,最终纳入1900人。这是数据筛选和清洗流程的可视化呈现。
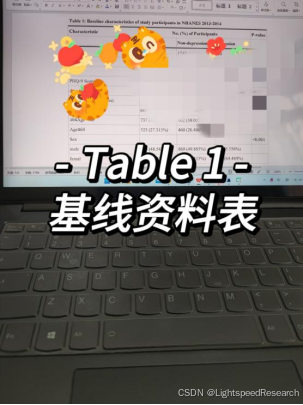
Table 1:基线资料表。这个表格用于比较不同人群之间的基线资料差异,例如抑郁组和非抑郁组,以描述人群的基本信息。在这个表格中,我们会列出不同变量的连续或分类数据,并进行t-检验或卡方检验等统计分析。
Table 2:回归分析表。通过构建不同的回归模型,评估暴露和结局之间的关系是否稳健。这包括了三个不同的模型,分别是 Crude Model、Model I 和 Model II。在这些模型中,我们会纳入不同的协变量,例如人口统计学信息和疾病情况,以评估其对结果的影响。
Figure 2:限制性立方样条(RCS)结果图。通过RCS曲线的呈现,展示了X和Y之间的剂量效应关系。这种图表非常直观地展示了线性和非线性关系,并且通过检验P for non-linear是否小于0.05来判断是否存在非线性关系。
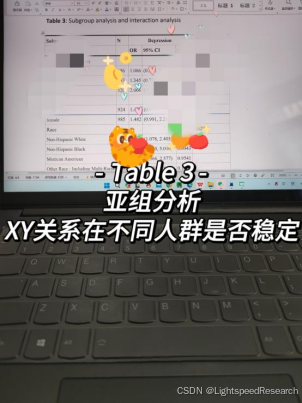
Table 3:亚组分析表。这个表格用于评估X与Y的关系是否在不同的亚组中存在差异。通过在不同的组别(如性别、年龄、特定疾病)中进行分析,我们可以观察到X与Y的关系是否依然稳健存在,以及在不同组别中是否存在差异。
这些Table和Figure是NHANES文章的主要结果展示方式。由于数据已经整理好,后续的分析工作实际上相对简单。选题和数据的整理才是最费时间的部分,也容易让人浮躁,但只要方向正确,就一定能够获得成果。
今天的挑战圆满成功,继续加油!




Day 6-7!
进度汇报:完成文章写作+投稿。
表格和图片制作完成啦,接下来就是写作部分啦!写作其实是最简单的一部分,采用《框架写作法》,我快速地进行了撰写。
虽然我不是"芒果",但我依然将电脑带到了科室进行夜班工作。在科室里,我投入到了写作的状态中,情绪十分投入,甚至都没注意到有人在喊我。有个大妈多次喊我,我都没反应过来,直到她说了些话才意识到。她夸赞了医生们的辛苦和水平,并提到了她孙女没能考上某某大学医学院的遗憾,但后来找了个学医的男朋友。这让我感受到了一种特别的情绪,哈哈哈!
根据之前挑战Meta和MR的经验,我知道一般来说一天就能写完初稿。而且我在挑战开始时就已经开始了方法部分的写作,所以现在只需要将图片和结果放进去,然后按照我目标文献的风格进行模仿即可。
完成中文稿后,我会进行翻译、润色,然后做好投稿前的准备工作。挑战成功!

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









