






Day 1!
NHANES数据库真的是常挖常新~,最近在临床轮转时get了新的idea,刚好NHANES数据库里有这些指标和疾病,小编打算发起一个新的挑战~想做的师弟师妹们也可以跟着一起做起来。
挑战5天完成一篇NHANES数据库SCI!今天的主要任务就是初步检索+确定目标期刊和文献。
想必大家对NHANES数据库已经有所了解,这个数据库涉及的指标和疾病特别广,各个科室都可涵盖,可以满足不同群体的需求,想到的idea都可以拿到这个数据库来验证。大家一起学习,一起加油~
不同类型文章的操作步骤都类似,首先得检索你的idea是否已经被他人做过,这特别特别特别重要!!!我对“NHANES”进行了检索,截至目前已经发文5800多篇了,势头很猛!然后我检索了“NHANES and 发现的新指标”,还没有人写过,抓紧时间冲锋!那就这么决定啦~
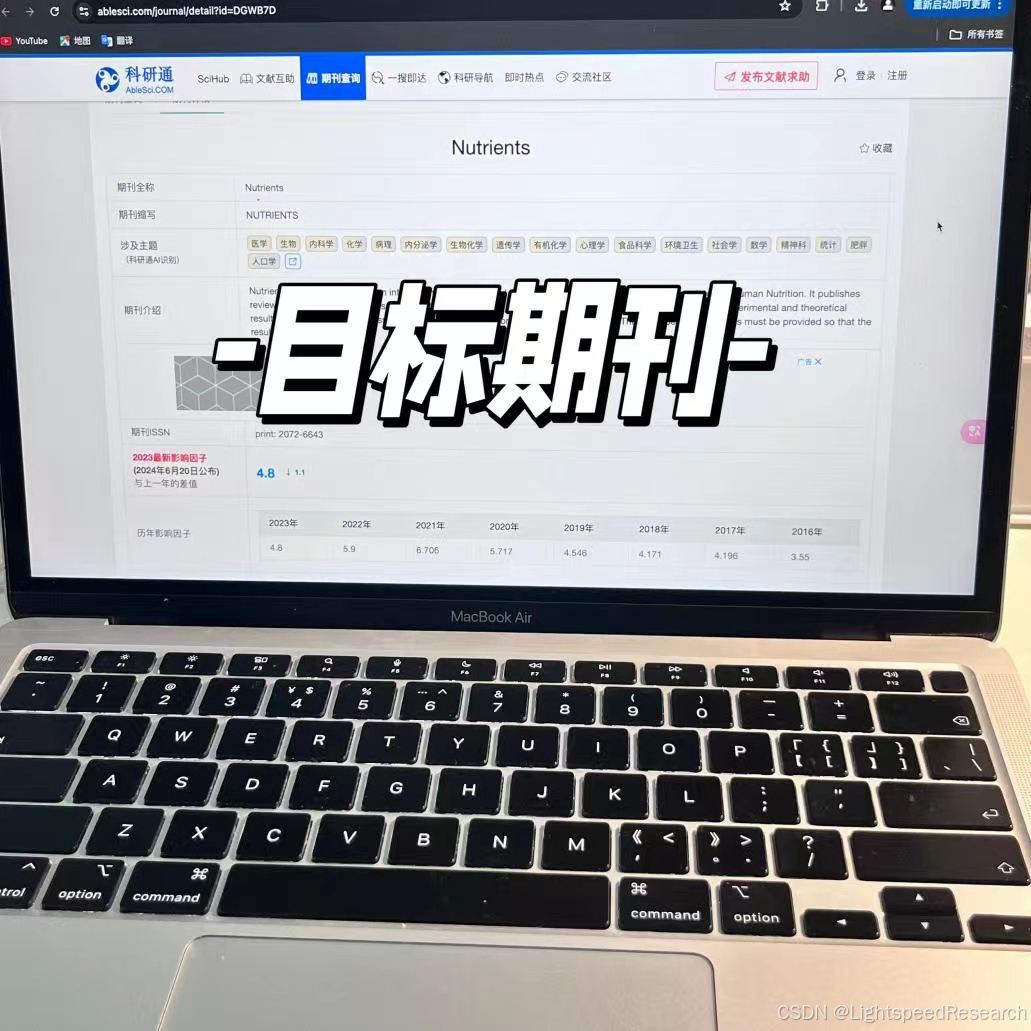
在看文献的过程中发现了一篇相同领域的经典文章,它所投的期刊的影响因子、发文量、首次回复时间都很不错,这篇文章中所用的方法我都已经掌握了,那就以这个期刊和文献为目标啦!
目标文献是:10.3390/nu16203556
目标期刊是:Nutrients
让我们一起探索NHANES数据库!冲冲冲~

Day 2!
挑战继续进行~
第2天的主要任务:提取数据前的准备
提取数据前需要准备的有:
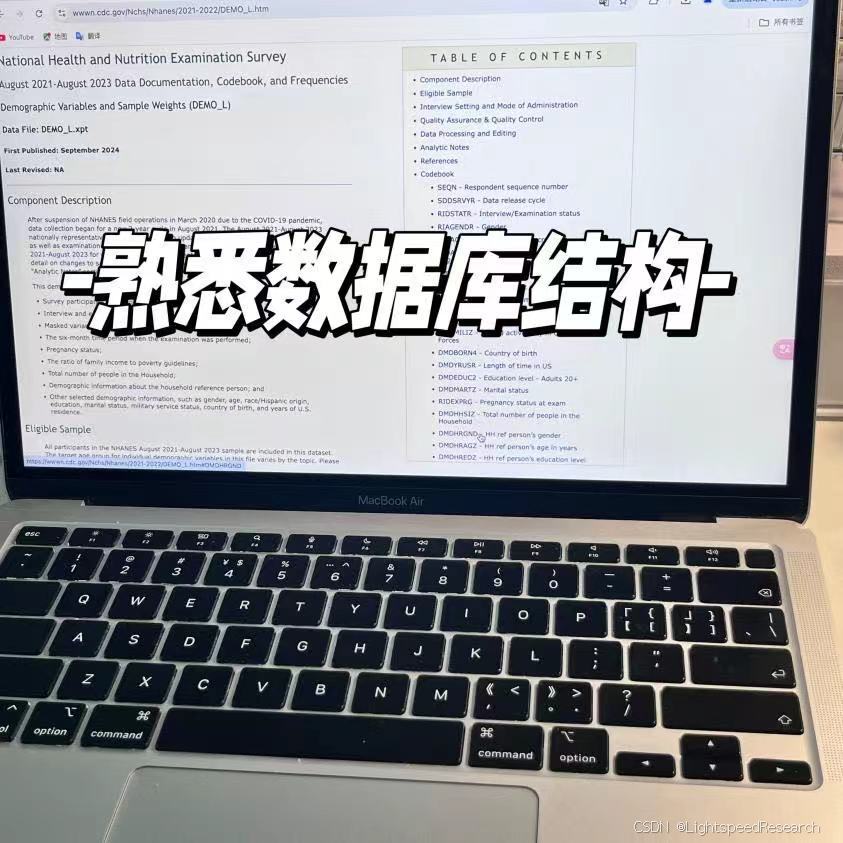
1. 熟悉NHANES数据库
2. 阅读10-20篇类似文章
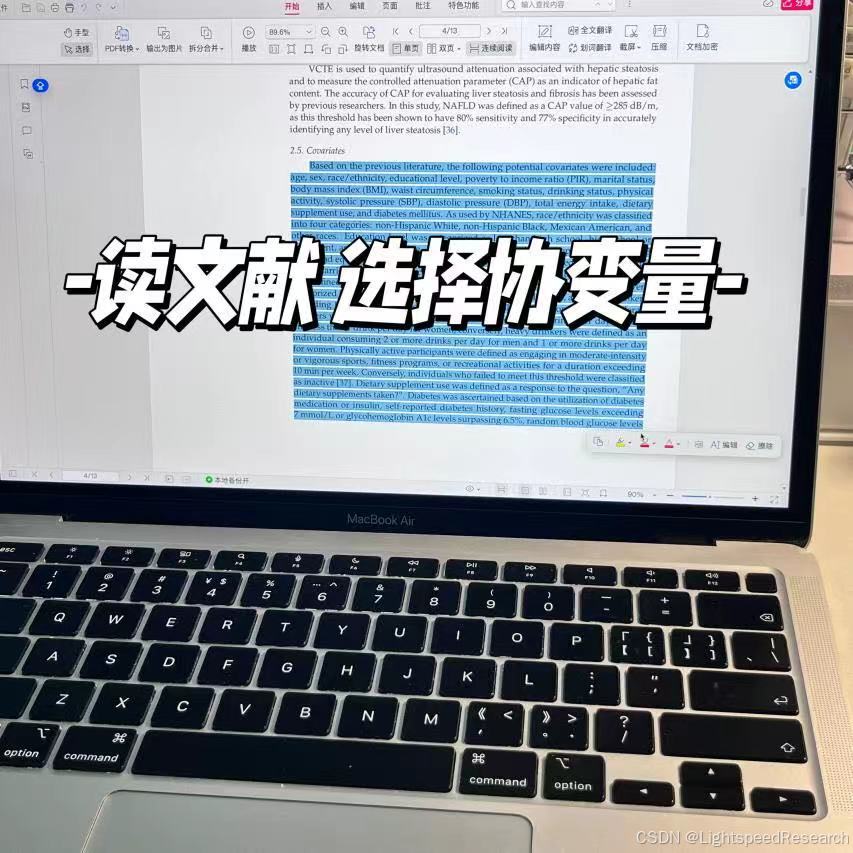
3. 明确文章需要的协变量
4. 制作Excel表格
经过前几期的挑战,大家对NAHNES数据库已经有了一定的了解,这个数据库优点就在于可操作性强,可以快速验证自己的选题,疯狂冲锋冲锋~
在确定协变量之前需要大量的看文献,了解别人的协变量是怎么写的,哪些可以借鉴,哪些需要根据自己的选题调整。
在明确好协变量后,需要整理一份独有的Excel表格,将X、Y以及协变量的详细内容都列进入,比如变量名、NHANES里的变量信息;分类变量还是连续变量;涉及的周期等等。任何事情做到心中有数才能事半功倍!
只要思路清晰了,后面的一切都好说,没什么复杂和困难的,重点就是选题(选择指标和idea)这就是我花了很多的时间进行初步检索的意义。千万不要一来就闷头开跑,不然很可能白费力气!!!
好啦,今天的分享就到这里,一起加油呀~

Day 3!
进度汇报:下载数据+清洗数据
首先是数据的下载部分,在前期我们已经将所需要的数据都整理在Excel表格中了,而且所有周期的所有数据也都下载到本地了,只需要用代码库库一顿提取就完事~
然后是数据的清洗部分,这个部分也是根据Excel表格来,比如年龄可以是连续变量,也可以根据年龄段分成分类变量,若是分类变量,那么每一类用什么数字来表示,这些都需要在表格中标注清楚。理清思路后就可以开始疯狂筛选啦!
整理好了数据以后,后面的分析实际上是非常简单的,选题才是最重要、最费时间的,也是最容易浮躁滴,静下来,方向对了,就一定能出成果。
今日份挑战成功~大家都进展到哪一步了呀~
Day 4!
进度汇报:完成图片和表格
数据已经清洗啦,现在要做的就是做出图片和表格。在具体操作之前呢,肯定要去看文献啦!明确需要跑出哪些结果,模仿文献一步一步来就好啦!
经典NHANES文章有以下这些结果:
Figure 1:流程图-----人群的数据来源过程
Table 1:基线资料表-----人群基本信息描述
Table 2:回归分析-----X与Y之间有无关系
Figure 2:RCS----X与Y的剂量效应关系
Table 3:亚组分析-----敏感性分析
当然,我们也会看到有很多文章会有一些其他的处理,比如加上了机器学习呀,和孟德尔、Meta结合这种。但本质上还是这个思路,只不过在暴露的选择、分析方法上会有一些差异。
这就是NHANES文章的主要结果啦,今日份挑战成功~大家的结果都跑出来了嘛!
Day 5!
进度汇报:完成写作
结果都已经跑出来了,后面就是写作啦!根据前期的挑战,大家会发现我们写作的时间都不是特别长,因为写作其实是坠简单的,根据我们的“框架写作法”,任何类型的文章都可以拿下!
在写作前,我会大量阅读目标期刊的类似文章,对这个期刊的投稿要求已经内容有了大致了解后,便准备开始动手啦~其实在第4天跑图片和表格的时候,我就差不多把中文写完啦!今天只需要翻译、润色,补充模块化语句,以及根据目标期刊的投稿要求调整内容就可以啦!
意料之内,这次也在2天之内写完了初稿!将所有准备好的内容发给导看过后,就准备投稿咯!
光速完成一篇NHANES,挑战成功!!!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









