







R L 2 RL^2 RL2:这篇文章的一作是Yan Duan,发表于2017年,它和JX Wang于2016年发表的Learning to reinforcement learn一起被广泛认为是Meta-RL的开端。
那么他们是如何迁移过来使得Meta-RL和Meta-Learning挂钩呢?
答:
回忆一下,Meta-Learning的两个优势在于快速适应(Fast Adaptation)以及通用性,除此之外还有一个2级结构——Meta-Learner和Learner:Learner用于学习一个具体的算法,比如分类回归、标准RL算法;Meta-Learner不涉及具体的算法,他的目的是学习一个学习算法,在训练期间,接受各种不同的tasks,通过来自Learner的反馈,进行参数的调节,从而对于一个新的task,可以快速适应上去。
这里的关键就是RNN结构,RNN具有记忆功能,对于一大堆MDP来说,有
m
i
∼
M
m_i\sim M
mi∼M,把这些都丢到RNN中去,用标准的RL算法进行训练。RNN作为策略网络其实相当于一个Meta-learner,训练期间不断进行调整,找到适应所有task的一个比较好的参数。那么当你给定一个新的task,当然这个task要与之前训练的MDP有一定的相似度,由于RNN的记忆功能,碰到一个熟悉的新task的时候,就会立马给出一个适合新任务(Learner)的策略网络
π
θ
\pi_\theta
πθ,那么同理,对于许多类似的新环境,Meta-Learner都会给出比较不错的解,这足以见证它的通用性强,当然做的这一点必须训练的够好,因此Meta-RL的训练是很难的,你给的MDP需要足够的多。
参考列表:
①论文解读
②原文翻译
③Learning to reinforcement learn论文解读
简介
这篇文章的核心思想和JX Wang的很相似,都是基于RNN来做Meta-RL。两篇文章的思想起源于Hochreiter在2001年发表的一篇文章,首次引入了基于RNN(LSTM)的梯度更新来做Meta-Learning。JX Wang和Yan Duan将Hochreiter的工作搬迁到了强化学习上。
核心内容
对于
R
L
2
RL^2
RL2这个名字,作者的解释是,因为Meta-RL的目的是通过Meta-Learner来学习一个通用性RL算法来解决RL问题,所以使用
R
L
2
RL^2
RL2。
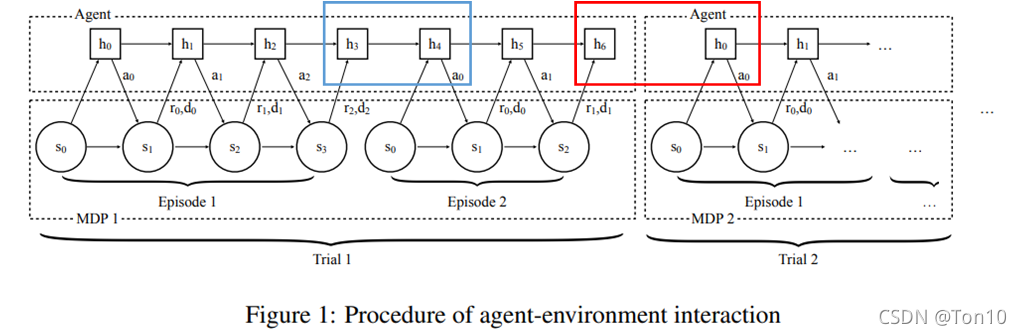
上图就是这篇文章最重要的地方,也就是作者提出的Meta-Learner结构,其本质就是个RNN:
- 定义一个trial里面包含2个episodes,都是用同一个task,不同的trial使用的MDP是不同的。
- 每一个任务都来采样于某个分布: M ∼ ρ M \mathcal{M}\sim\rho_\mathcal{M} M∼ρM。
- 如上图所示,每个episode的初始状态 s 0 s_0 s0都采样于该MDP的状态集 S \mathcal{S} S。
- 上图的过程也很简单,通过RNN去实现一个轨迹 < s 0 , a 0 , s 1 , r 1 , d 1 ⋯ > <s_0,a_0,s_1,r_1,d_1\cdots> <s0,a0,s1,r1,d1⋯>。需要注意的是,RNN结构里有隐藏状态 h i h_i hi,作为RNN的输出,因此其一般都是和动作输出有关。
- 如上图蓝色框所示,相邻episode之间隐藏状态是保留的;如红色框所示,不同MDP之间的隐藏状态是不保留的。
- 我们在标准的RL中,最大化期望累计奖励是基于单个Episode的,在本文中, m a x i m i z e maximize maximize是基于单个trial。
- 在每个step,RNN都接收来自过去时间的
<
s
,
a
,
r
,
d
>
<s,a,r,d>
<s,a,r,d>作为输入,与Learning to Reinforcement Learn不同的是,它并不是在每个episode结束之后重置RNN的隐藏层。此外,通过使用标准的RL算法,比如本文使用的是TRPO(Learning to Reinforcement Learn使用A3C)去训练RNN

,使得RNN对于一个新的task,能做出调整使得Agent在这个MDP有好的performance。 - 至于文章的标题Fast RL via Slow RL,根据作者所说
 Slow应该指的就是Meta-Learner在训练阶段需要很多MDP作为训练样本来训练,其训练是很难的,需要一定的时间。而Fast指的是当Meta-Learner吸取了过往的经验之后,对于一个新的task,可以Fast Adaptation,Agent只需要少量的交互就可以适应新环境。
Slow应该指的就是Meta-Learner在训练阶段需要很多MDP作为训练样本来训练,其训练是很难的,需要一定的时间。而Fast指的是当Meta-Learner吸取了过往的经验之后,对于一个新的task,可以Fast Adaptation,Agent只需要少量的交互就可以适应新环境。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









