








这篇文章是今年6月份刚出的VSR文章,其推出了一种将循环网络结构和Transformer结构相结合的一种模型——Recurrent Video Restoration Transformer(RVRT)。RVRT完成了Recurrent-based模型和Vision-Transformer模型之间的平衡,从而实现了模型大小、计算效率、表现力之间的trade-off。
Note:
- 本文只探究VSR部分。
参考文档:
①源码
Recurrent Video Restoration Transformer with Guided Deformable Attention
Abstract
- VSR方法大致分为Sliding-windows、Recurrent、Transformer三大类,其中后面两个是目前已被证明更好的方法。现有的视频超分陷入了2个极端,即要么就是Recurrent-based模型,要么就是Transformer-based模型。
- Recurrent-based模型例如RLSP、BasicVSR、BasicVSR++等通过一帧接一帧的方式对LR图像进行超分。虽然基于RNN会使得模型共享从而产生较小的模型量;此外每次处理一帧也使得运算效率很高;但是循环网络模型天然会遭受梯度爆炸/消失、信息衰减、噪声放大等问题,因此其无法捕捉长距离上的特征信息。
- Vision Transformer-based模型例如VSRT、VRT等对多帧同时并行提取特征信息,但是会造成较大的模型参数和显存消耗。
基于两种模型的优缺点,本文作者提出了一种将Recurrent-based和Vision Transformer=based结合的模型——RVRT。
- RVRT将整个序列 L R S LRS LRS分成一段段,每一段作为一个clips,即整个序列由 T N \frac{T}{N} NT个clips组成,每个clips里面有 N N N帧。由于 N < T N < T N<T,故RVRT相当于将整个序列缩短了,这样才能弥补Recurrent-based的缺陷。
- 每个clips内部使用Transformer并行化处理;clips之间使用Guided Deformable Attention(GDA)来做对齐;而整个模型框架还是基于循环网络的,因此可以说RVRT在局部上使用并行结构来提取特征,全局上使用循环结构,两者相互结合,实现了模型大小参数量、计算效率、表现力的trade-off。
- RVRT是VRT的升级版,都是同一批作者,二者都适合于所有的视频恢复任务,如超分、去噪、去模糊、去块等。
- RVRT在通用的数据集上实现了SOTA的表现力,证明了Recurrent和Transformer结合起来实现视频恢复的方案是可行的。
1 Introduction
首先我们先对目前主流的2种VSR模型的优缺点进行简要阐述:
Recurrent model \colorbox{orange}{Recurrent model} Recurrent model
- 优点:因为RNN结构是共享模型的,同一套参数在不同时间段被重复使用,因此其模型参数量较小,计算效率较高。
- 缺点:缺乏长距离建模的能力,这是由于当序列长度较长时候,循环结构会发生梯度消失/爆炸现象,以及天然会存在信息丢失和噪声放大问题;此外无法并行化提取所有帧信息也是比较低效的。
Vision Transformer model \colorbox{deepskyblue}{Vision Transformer model} Vision Transformer model
- 优点:可以直接并行化对所有帧同时提取特征信息,简单来说就是 T T T帧进去, T T T帧出来;可以直接融合所有帧的特征信息,因为Transformer可以根据注意力机制来挑选一些更有用的特征。
- 缺点:模型大、计算复杂度高、训练难度大、显存占用较大。
因此作者打算实现一个同时具备上述2个模型优点的混合模型——RVRT。
RVRT在以Vision Transformer为基础之上引入循环结构来减小模型参数量;此外RVRT将一定数量的相邻帧合并成1个clip,从而降低了输入帧的有效个数,缓解了Recurrent模型无法捕捉长距离特征信息、信息衰减问题。
具体而言,RVRT的核心为3部分:①循环结构;②Recurrent Feature Refinement(Vision Transformer部分);③Guided Deformable Attention。下面我们简要介绍一下这三部分。
Recurrent Structure \colorbox{yellow}{Recurrent Structure} Recurrent Structure
循环结构可以构建长序列在时间维度上的相关性。但为了避免序列太长导致RNN结构天然的问题,RVRT将整个序列分成 T / N T/N T/N个clips,每个clips里面包含了 N N N帧。其循环结构基本和BasicVSR++类似:所有的clips共用同一个网络——RFR,特征传播沿着两个方向进行,只不过RVRT的隐藏状态更大,因为它是一个clip;此外RFR还有 L L L层的传播迭代用来让对齐更加准确。相比传统的Recurrent-based结构,RVRT不容易产生梯度消失/爆炸、过多的信息衰减以及噪声放大问题。
Recurrent Feature Refinement \colorbox{springgreen}{Recurrent Feature Refinement} Recurrent Feature Refinement
RFR可以说是一整个循环结构,也可以说是单独一个特征校正模块,既然前者已经叙说过了,这里就单指代后者。RFR结构主要由Swin-T结构组成,主要用于对clips内的 N < T N < T N<T帧进行特征提取,在空间中提取到所有的信息,由于只在clip内部进行,因此模型的复杂度被有效降低了。
Guided Deformable Attention \colorbox{mediumorchid}{Guided Deformable Attention} Guided Deformable Attention
一般Transformer用于特征提取比较多,自从VRT出现MMA之后,RVRT也出了Transformer用于对齐的功能。GDA主要利用DA的机制来对齐相邻的clips。一来其可以有效降低Transformer的计算量;二来其比传统的CNN-based对齐方式,比如flow-based方法每次对齐只依赖于1个采样点,而DAT可以基于多个采样点来生产对齐结果;三来相比MMA只能基于局部空间建模,DAT可以在全局空间中建模。
小结一下:
- RVRT可以利用Transformer在帧数较少的clips内部中的局部空间上进行同步并行提取特征信息;此外利用Recurrent结构进行时许上的相关性建模可以减轻模型复杂度;将帧数分成clip-by-clip的形式不但可以减轻梯度消失/爆炸的问题,也可以减轻Transformer计算量。Recurrent+Transformer的结构可以同时占据两者的优势。
- RVRT提出了基于Transformer的对齐方式——GDA,其用于clips-to-clips的对齐。
- RVRT在一系列benchmark上展现了SOTA的水平,实现了模型大小、显存占用量、runtime和表现力之间的trade-off。
2 Related Work
略
3 Methodology
3.1 Overall Architecture
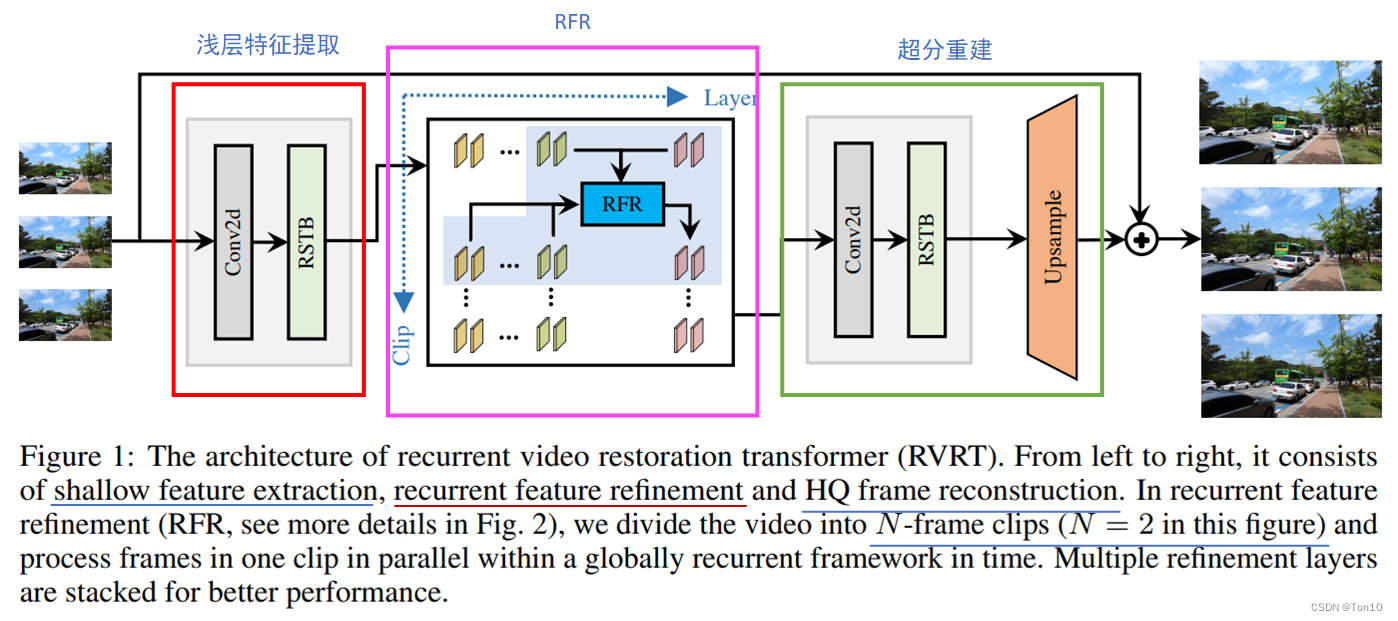
如上图所示就是RVRT的pipeline,其主要由3部分组成:①浅层特征提取模块;②RFR模块;③超分重建模块。
①浅层特征提取:对于超分任务由1个卷积层和RSTB(Residual Swin Transformer Blocks)组成,来提取浅层特征。
②RFR:RVRT的核心部分,其利用Recurrent机制来做全局范围内的或者说时间维度上的相关性建模以及利用Transformer来做局部空间范围内的相关性建模,从而实现了模型复杂度和表现力的trade-off;此外RFR中使用了GDA来做clips之间的对齐。
③超分重建:这部分也是使用了1个卷积层和RSTB组成,外加Pixelshuffle来做上采样生成最终的SR图像。
损失函数:
Charbonnier函数: L = ∣ ∣ I S R − I L R ∣ ∣ 2 2 + ϵ 2 , ( ϵ = 1 0 − 3 ) \mathcal{L} = \sqrt{||I^{SR} - I^{LR}||^2_2 + \epsilon^2},(\epsilon=10^{-3}) L=∣∣ISR−ILR∣∣22+ϵ2,(ϵ=10−3)。
3.2 Recurrent Feature Refinement
RFR这个结构和BasicVSR++很像——它的结构主要由双向传播与传播迭代组成;具体结构如下图所示:

别看它看起来复杂,其实就是个BasicVSR加了 L L L次传播迭代,只不过特征校正和对齐的方式变了。
具体而言,其横向是传播迭代,纵向是双向或者单向的特征传播;此外最重要的一点是,传统的Recurrent-based模型都是基于单张特征图之间的对齐,而RFR则是clips-to-clips之间的对齐。
Note:
- 但要注意的是RFR没有coupled-propagation。
- 此外BasicVSR系列的对齐使用flow-based或者flow-guided这些CNN-based方法,而RVRT使用的是Transformer-based方法——
Guided Deformable Attention来做对齐。 - BasicVSR系列的特征校正模块都是使用CNN-Based例如残差块堆积的方式;而RVRT使用Transformer-based方法——
MRSTB,一种基于Swin-T的结构,该结构将一个clips里面的 N N N帧同时并行提取特征而不像传统Recurrent-based模型中采取frames-by-frames的样式。 - 图中 F t i − 2 F_t^{i-2} Fti−2表示第 i − 2 i-2 i−2层中第 t t t个clips,其中每个clips内含有 N N N个连续帧。
接下来我们具体展开对RFR模型进行叙述。
设第 i i i层(即共 L L L个RFR块中的第 i i i个)的特征表示为 F i ∈ R T × H × W × C F^i\in\mathbb{R}^{T\times H\times W\times C} Fi∈RT×H×W×C;首先对它进行split为 T N \frac{T}{N} NT个clips,每个clips内含 N N N个连续帧,记为 F i ∈ R T N × N × H × W × C F^i\in\mathbb{R}^{\frac{T}{N}\times N\times H\times W\times C} Fi∈RNT×N×H×W×C,则每个clips可表示为 F 1 i , F 2 i , ⋯ , F T N i ∈ R N × H × W × C F_1^i, F_2^i, \cdots, F^i_{\frac{T}{N}}\in\mathbb{R}^{N\times H\times W\times C} F1i,F2i,⋯,FNTi∈RN×H×W×C;每个clips内部的 N N N个连续帧表示为 F t , 1 i , F t , 2 i , ⋯ , F t , N i ∈ R H × W × C F^i_{t,1},F^i_{t,2},\cdots, F^i_{t,N}\in\mathbb{R}^{H\times W\times C} Ft
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1810
1810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









