







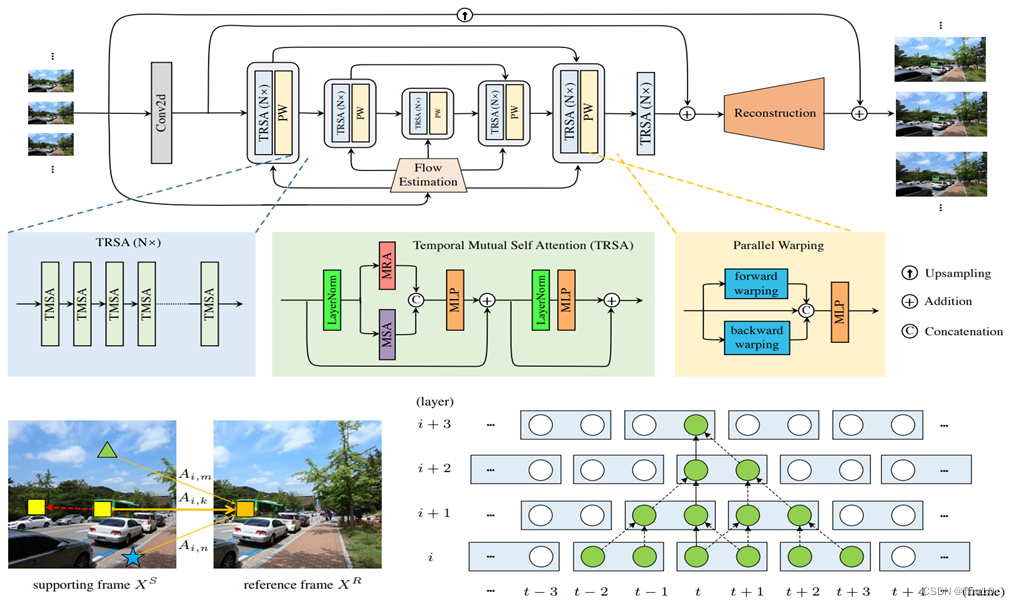
这篇文章提出了一个适用于VSR的并行超分模型——VRT。VRT是一种利用Vision-Transformer来做特征传播的模型,其核心是一个Temporal Mutual Self Attention(TMSA)模块——将基于swin-T的Mutual-Attention和Self-Attention进行融合来提取或者说聚集视频序列的局部和全局特征信息,并使用基于flow-guided DCN Alignment的Parallel Warping(PW)来做对齐,并对相邻帧进行融合,最后通过重建模块完成视频序列的上采样。此外,VRT使用了4种不同的尺度(multi-scale)来进行不同感受野的特征信息提取,对于较小分辨率可以捕捉更大的运动来更好的实现大运动的对齐,而对于较大的分辨率则更有利于捕捉更多局部相关性从而聚合局部信息。
Note:
- VRT可以适用于许多视频恢复任务,诸如超分、去噪、去模糊、去块任务等,但本文只针对解析视频超分VSR部分。
- VRT和VSRT的同一批作者。
- 个人见解:这篇文章貌似就是将一些破铜烂铁堆积起来的感觉,用较大的模型来硬学 L R → H R LR\to HR LR→HR。
参考列表:
①源码
VRT: A Video Restoration Transformer
Abstract
- 自从VSRT之后,VSR领域对于特征传播方式不同可以大致分为3类:①
Sliding-windows;②Recurrent;③Vision-Transformer。滑窗这种local的方式无法捕捉长距离范围内的特征信息;而基于RNN的VSR方法只能串行的执行一帧接一帧的重建。因此为了解决上述2个问题,作者提出了一种既具有捕捉长距离范围内的全局相关性的能力,又可以实现帧并行化的重建,这就是VRT模型。 - VRT由多种尺度组成,每个尺度叫1个stage,实验中一共设置了8个stage。前7种尺度中每种尺度都由1个TMSA组(TMSAG)串接1个Parallel Warping(PW);第8个stage(即RTMSA)只由1个TMSAG组成,但不含PW。此外,1个TMSA由 d e p t h depth depth个TMSA模块串接组成;而每个TMSA模块就是Transformer的Encoder部分,而注意力部分则是由1个Multi-head Mutual Attention和1个Multi-head Self Attention组成;而FFN则是用GEGLU代替。
- 为了减少VSRT在时空上大量的相似度计算,VRT基于Swin-Transformer,即窗口化的形式来聚集局部范围内的相关性。不同于Swin-IR,VRT的窗口是3维窗口,即时间+空间,比如实验中采用了 ( 2 , 8 , 8 ) (2, 8, 8) (2,8,8)的窗口,就是时间维度上以2帧为单位进行分割,空间上以 8 × 8 8\times8 8×8为单位进行分割,因此相似度的计算就在 2 × 8 × 8 2\times8\times8 2×8×8个token之间计算。而所有的窗口都被放到Batch维度,故每个窗口都在GPU上并行并相互独立的做计算。
- 不管是自注意力还是互注意力(mutual-attention),都是基于3D窗口的,而不是整张图像。假设窗口为
(
2
,
8
,
8
)
(2, 8, 8)
(2,8,8),那么自注意力就和VSRT一样,在
2
×
8
×
8
2\times8\times8
2×8×8个token上做时空自注意力;而mutual-attention则是在2帧上各自的2D窗口之间做互注意力。但是这样的特征传播方式会局限于2帧之内,故作者借鉴swin-T的核心——
shifting的思想,设置3D移动窗口 ( 2 / 2 , 8 / 2 , 8 / 2 ) = ( 1 , 4 , 4 ) (2/2, 8/2, 8/2)=(1, 4, 4) (2/2,8/2,8/2)=(1,4,4)在空间和时间上都做移动。 - 自注意力用于提取时空上的特征信息,而互注意力用于特征对齐,这一思想是和TTVSR的轨迹注意力异曲同工。
- VSRT的对齐可以说是并行的,因为他将帧放到batch维度;但是VRT前后项分支的对齐实际上是串行的,通过for循环做的。PW融合的过程和VSRT是一样的——两个分支各自做对齐,最后2个分支的对齐结果和参考帧序列做融合,就其融合本质而言,其实就是时间窗口为3时候的sliding-windows对齐方式—— [ f t − 1 → f t ; f t + 1 → f t ] [f_{t-1}\to f_t;f_{t+1}\to f_t] [ft−1→ft;ft+1→ft];PW使用的是光流引导的DCN对齐方法。
- VRT就目前在排行榜上是第一名,取得了SOTA的表现力。
Note:
-
光流通过SpyNet获取,和TTVSR一样,对于 n n n帧,学习 n − 1 n-1 n−1个光流;而VSRT则是学习 n n n个光流。这里补充下光流估计的一个示意图:
-
在源码中作者使用 64 × 64 64\times64 64×64为patch大小,采用 64 、 32 、 16 、 8 64、32、16、8 64、32、16、8共4种分辨率尺度。
-
VRT的重点:①总体架构设计;②TMSA;③PW;④windows&shifting-windows;⑤multi-scale。
1 Introduction
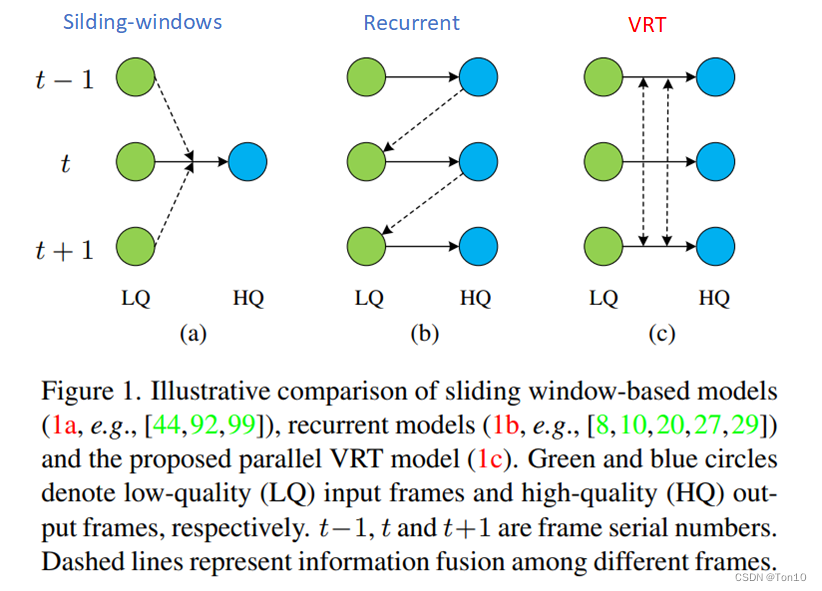
如上图所示是3种特征传播的方式,从左到右分别是Silding-windows、Recurrent、VRT(也可以作为Transformer类的代表)。
Silding-windows
\colorbox{mediumorchid}{Silding-windows}
Silding-windows:
这种方式是VSR早期的典型方法,将时间窗口(或者说时间大小、时间感受野、时间滤波器)固定为3、5或7帧,典型代表VESPCN、TDAN、Robust-LTD、EDVR等。这种方式的缺陷一来在于可利用的特征信息比较局限,每次对齐只能利用local的帧信息;二来在于在整个训练过程中,同一帧被多次当作支持帧,可能会被做多次从头开始的重复的对齐操作,这就会造成多余的计算消耗,是一种比较低效的特征信息利用方式。
Recurrent
\colorbox{violet}{Recurrent}
Recurrent
这种方式是将VSR建模成Seq2Seq方式,每次对齐的时候都要利用上一帧对齐的结果来帮助当前帧的对齐,因为RNN结构的隐藏状态可以记忆过去的信息,因此可以说是利用到过去或未来所有的特征信息,典型代表BasicVSR系列(BasicVSR、BasicVSR++)、RLSP等。这种方式的缺陷一来在于在长序列中容易产生梯度消失现象,造成未能捕捉较远的特征信息(这是RNN的缺陷);二来在于容易产生误差累积以及信息衰减问题,这是因为某一帧可能对它下一帧的影响很大,但再传播一阵子,这部分信息就会对后面帧的帮助很小,因为在传播过程中,隐藏状态不断被刷新;三来在于在短序列视频中很难产生较高的表现,这在VSRT的实验中已经得到证明;四来这种方式是采用一帧接一帧去重建的,无法做到并行处理。
Vision-Transformer
\colorbox{hotpink}{Vision-Transformer}
Vision-Transformer
既然Recurrent将VSR建模成Seq2Seq问题,那么基于RNN过度到Transformer,以及我们可以根据注意力机制在长序列上提取合适的特征信息来帮助对齐。基于这样的思想,2021年VSRT就出世了,它可以做到并行提取特征信息,并行对齐。但缺陷在于token数目太多,需要消耗太大的计算资源,这也限制了它无法应用于较大的LRS。VRT就是这种并行模型,它可以做到并行计算,并捕捉长距离范围内的相关性,这个长距离即包括空间维度,也包括时间维度上。现在也陆续出了许多基于Vision-Transformer的VSR方法,主要进行计算量的优化、如何捕捉更长序列的特征信息,诸如TTVSR等以及如何进一步聚集更好的局部信息。
接下来我们先对VRT进行简要的介绍。
①VRT网络结构:
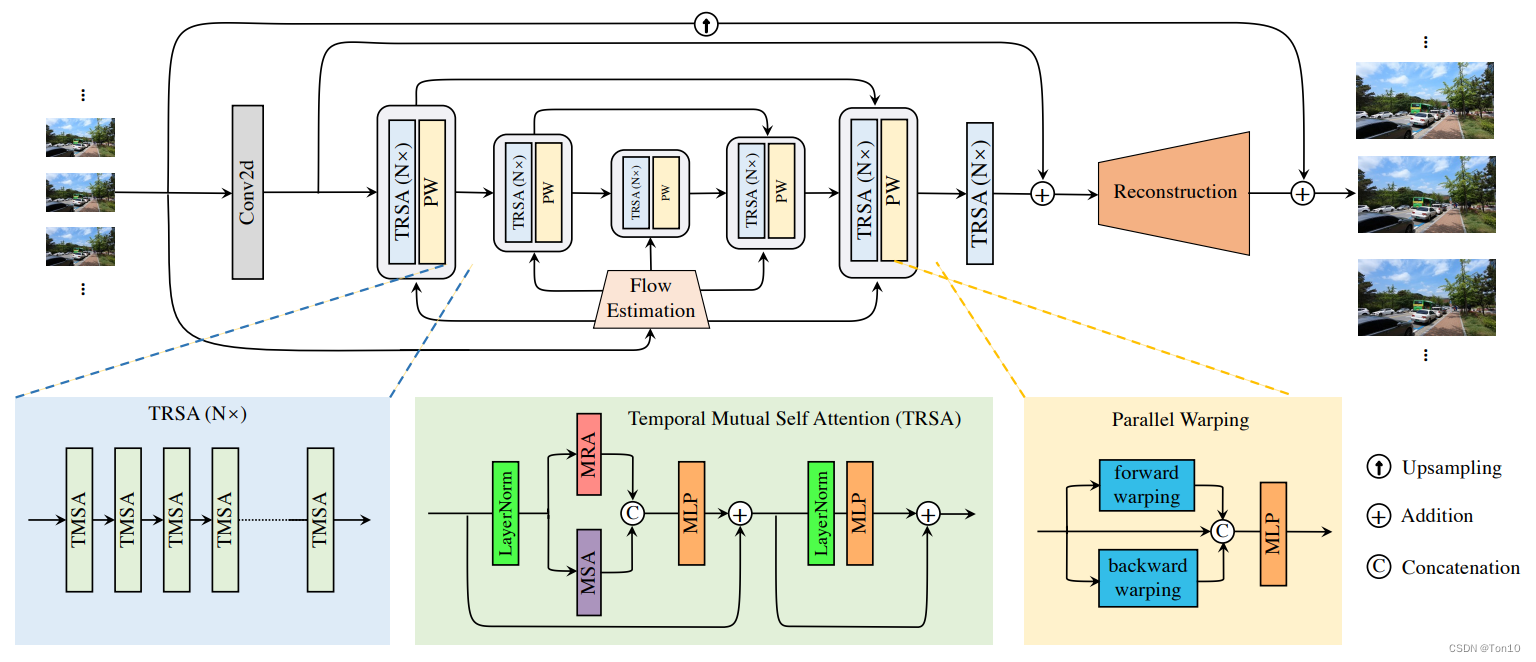
VRT的pipeline是由多个尺度块串接组成的,每个尺度块主要用于基于windows的特征对齐和特征提取;每个块的末尾还接上一个DCN-based对齐块,我们把每个块称为stage。
VRT的8个stage之后就可以进行SR超分重建,为了让重建也可以并行操作,使用3D卷积+pixelshuffle的方式来做(具体分析见第三节)。
②Multi-scale:
VSR的重建需要结合多种感受野或者说多种分辨率尺度的特征提取与对齐,因此设置一定数量的尺度也是有必要的。实验中设置了4种分辨率尺度——
64
×
64
、
32
×
32
、
16
×
16
、
8
×
8
64\times 64、32\times 32、16\times 16、8\times 8
64×64、32×32、16×16、8×8,由于每一种尺度的窗口大小都是一样的,因此
16
×
16
16\times 16
16×16虽然分辨率低,但是每个窗口内的token的感受野更大,更有利于处理大运动的对齐;而
64
×
64
64\times 64
64×64分辨率较高,每个窗口内的token感受野较小,更有利于捕捉更细微的运动。故多种尺度的结合可以更全面的处理视频超分任务。
③TMSA:
TMSA模块就是Transformer中的Encoder模块,其由注意力层和FFN层组成。VRT的注意力层由MMA和MSA组成。MMA和MSA都是基于窗口的,这是为了减小计算量以及更好的聚合局部信息。MSA和VSRT的自注意力层是一样的,只是一个是基于整个patch,VRT是基于windows;关键在于MMA,MMA是相邻两帧之间互相做对方的参考帧,其Query并不在当前windows下进行搜寻,而是在另一帧的Key中计算相似度,这其实是一种对齐方法,可以看成是一种隐式的运动补偿过程。
④PW:
PW本质就是分为2个分支,前向和后向。比如说前向的时候,依次使用flow-guided DCN Alignment来依次对相邻两帧进行对齐,比如
f
(
x
t
−
1
)
→
x
t
f(x_{t-1})\to x_t
f(xt−1)→xt并存到list中,同样在另一个分支中list相同的位置也会有一个
x
←
f
(
x
t
+
1
)
x\gets f(x_{t+1})
x←f(xt+1),最后将
[
f
(
x
t
−
1
)
,
x
t
,
f
(
x
t
+
1
)
]
[f(x_{t-1}), x_t, f(x_{t+1})]
[f(xt−1),xt,f(xt+1)]进行融合输出,并通过重建模块输出就是
x
t
x_t
xt的高分辨率版本了。可以看出这种融合方式和VSRT是一模一样的,只是VSRT是flow-based的并行对齐,而VRT是DCN-based串行对齐。此外,还有个微小不同点是VRT的光流获取个数和TTVSR是一样的,而VSRT要多了一个,但是差别不大。
⑤window-attention&shifting-windows:
- 由于VSRT基于全patch的相似度计算量太大了,所以VRT吸取swin-T的思想,只在一个窗口内计算相似度,这样可以大大节约计算量且更好的聚合局部信息,提取局部相关性,但是这样带来的局部感受野毕竟太小,故才会引入多尺度的方式来弥补这一缺陷,其实swin-T本身也是有扩大感受野的步骤的,VRT没有直接照搬,而是直接设置多个scale来增大全局感受野。
- 此外和swin-T不同的是,视频具有时间维度,因此窗口必须升级到3D,从2D的相关性上升到时空相关性。
- Swin-T的核心就是
shifting-windows,故VRT也设置了大小为窗口一半的shifting-windows,比如 ( 2 , 8 , 8 ) → ( 1 , 4 , 4 ) (2, 8, 8)\to (1, 4, 4) (2,8,8)→(1,4,4),当然对于 8 × 8 8\times 8 8×8的尺度来说空间上不能移动了,shifting-window为 ( 2 , 8 , 8 ) → ( 1 , 0 , 0 ) (2, 8, 8)\to (1, 0, 0) (2,8,8)→(1,0,0)。 - 空间上的shifting和swin-T是一样的,关键在于时间维度上的shift,VRT中每个尺度下由 d e p t h depth depth个TMSA,偶数时候为的shifting-windows为 ( 0 , 0 , 0 ) (0, 0, 0) (0,0,0),奇数时候才为正常窗口的一半。这样子时间上的移动可以促使MMA和MSA可以利用更多时间帧上窗口内的特征信息。
Note:
- 加上VRT,目前我们熟知的有4种获取token的方式:①ViT提出的直接从图像中不重叠分割然后通过投影层输出 N N N个token;②COLA-Net提出的unfold方式;③SuperVit提出的使用卷积的方式取token;④VRT先学习出token-embedding的维度 C C C,然后直接用reshape的方式取出固定大小的token。
- 需要注意的是,token的size是3维的——(B, N, C),C是会被相似度计算消耗掉的维度。
小结一下:
- VRT最大的特点在于MMA的并行对齐以及可以一次性直接并行输出所有帧的超分结果。
- 此外VRT可以利用一定时间距离上的特征信息,具有捕捉长距离相关性的能力。
- VRT基于窗口的注意力计算节约了一定的计算量以及更好的集聚局部信息。
2 Related Work
略
3 Video Restoration Transformer
3.1 Overall Framework
首先来看VRT的总体架构设计:
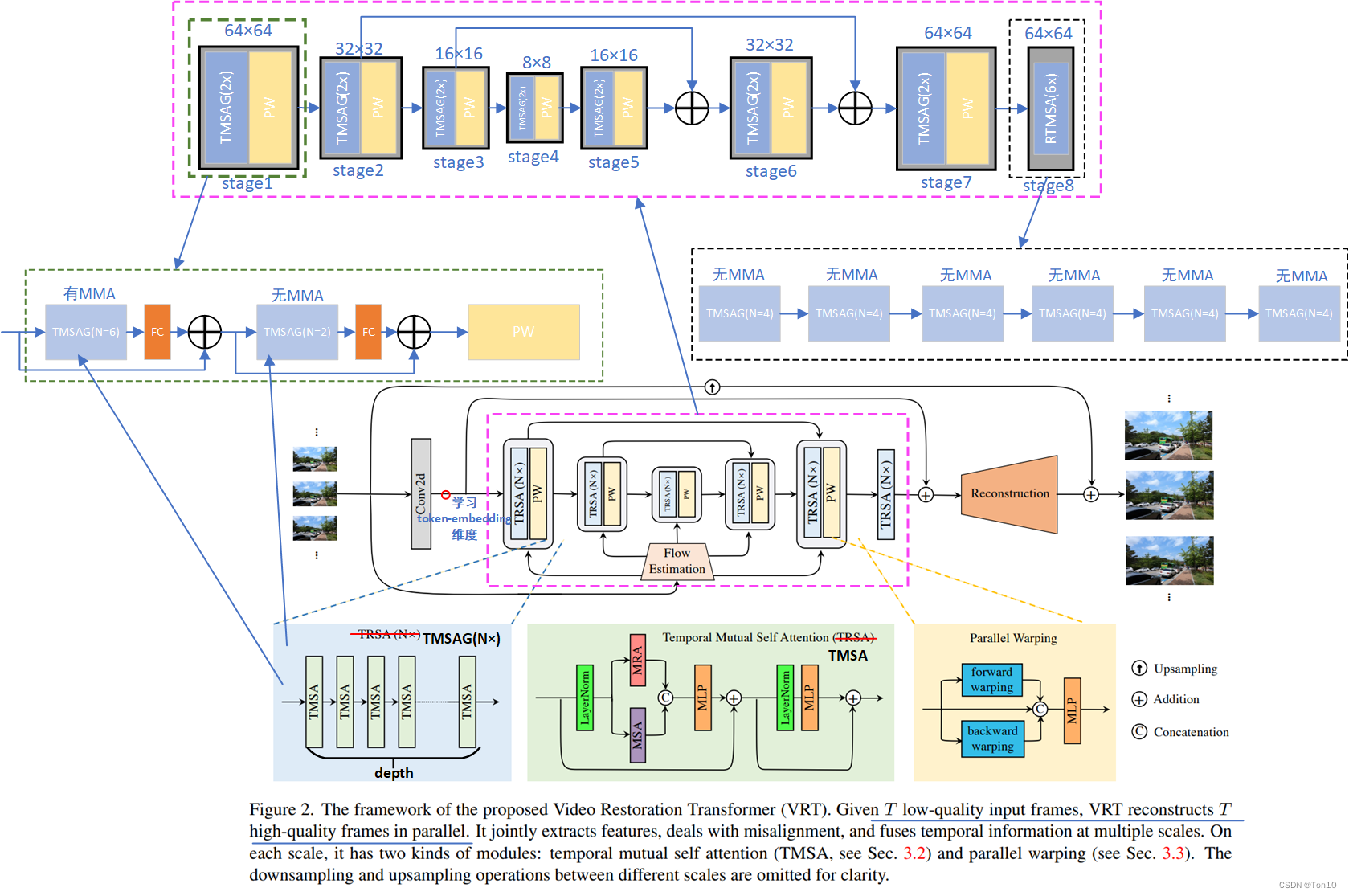
VRT总体分为2部分:①特征提取;②SR重建。
Note:
- 当输入帧为12帧的时候,stage1~7中有MMA的TMSA块采用 ( 2 , 8 , 8 ) (2, 8, 8) (2,8,8)的窗口,而无MMA的TMSA块采用 ( 6 , 8 , 8 ) (6, 8, 8) (6,8,8)的窗口,stage8采用 ( 1 , 8 , 8 ) 、 ( 6 , 8 , 8 ) (1, 8, 8)、(6, 8, 8) (1,8,8)、(6,8,8)的窗口。时间窗口的增大也是为了增强VRT捕捉较远距离相关性的能力。
- Stage1~7的token-embedding维度均为120,而stage8为180。
- Shifting-windows的获取有三道工序:①窗口的一半;②depth为奇数时候才是窗口一半,否则为(0, 0, 0);③根据窗口和输入序列的比较来最终决定shifting-windows的大小。
- Stage1~8都需要使用shifting-windows,这和是否有MMA是无关。此外因为shifting窗口是窗口的一半,那么对于 ( 1 , 8 , 8 ) (1, 8, 8) (1,8,8)的窗口其对应的shift窗口为 ( 0 , 4 , 4 ) (0, 4, 4) (0,4,4)
特征提取
\colorbox{lightskyblue}{特征提取}
特征提取
①:设VSR的输入序列LRS为
I
L
R
∈
R
T
×
H
×
W
×
C
i
n
I^{LR}\in \mathbb{R}^{T\times H \times W\times C_{in}}
ILR∈RT×H×W×Cin。首先经过1个3D卷积层提取浅层特征
I
S
F
∈
R
T
×
H
×
W
×
C
I^{SF}\in\mathbb{R}^{T\times H\times W\times C}
ISF∈RT×H×W×C,其中C为token-embedding的维度,对于stage1~stage7而言
C
=
120
C=120
C=120,对于stage8而言,
C
=
180
C=180
C=180,中间使用1个FC过渡一下即可。
②接下来是VRT的核心部分,其基于4种不同尺度来做不同分辨率上的对齐,多尺度是VRT的一个特点,也是为了弥补swin-T中增加窗口感受野的部分。具体而言,设LRS中输入分辨率为 S × S S\times S S×S( S = 64 S=64 S=64),则每经过1个stage,就下采样2倍,它实际上就是shuffle_down,用 2 × 2 2\times 2 2×2的窗口去将像素堆到通道维度上,然后使用全连接层进行通道缩减,这个和RLSP、Swin-T是一样的;和下采样一样,之后会陆续上采样。具体源码如下:
# reshape the tensor
if reshape == 'none':
self.reshape = nn.Sequential(Rearrange('n c d h w -> n d h w c'),
nn.LayerNorm(dim),
Rearrange('n d h w c -> n c d h w'))
# 降采样
elif reshape == 'down':
self.reshape = nn.Sequential(Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2),
nn.LayerNorm(4 * in_dim),
nn.Linear(4 * in_dim, dim),
Rearrange('n d h w c -> n c d h w'))
# 上采样
elif reshape == 'up':
self.reshape = nn.Sequential(Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2),
nn.LayerNorm(in_dim // 4),
nn.Linear(in_dim // 4, dim),
Rearrange('n d h w c -> n c d h w'))
一般我们做上采样或者下采样,可以选用上面这种shuffle_down(本质是pixelshuffle的逆过程,即shuffle_up)、各种插值办法interpolation(如最近邻插值)、上池化、反卷积。
③Stage1~7下都由含有MMA和MSA的TMSA组成;而Stage8则由只含MSA的TMSA组成,且其token-embedding的维度为180,分辨率都是 S × S S\times S S×S。最后Stage8的输出就是深层特征 I D F ∈ R T × H × W × C I^{DF}\in \mathbb{R}^{T\times H\times W\times C} IDF∈RT×H×W×C。
SR重建
\colorbox{gold}{SR重建}
SR重建
接下来通过FC对
I
S
F
I^{SF}
ISF做通道缩减并与
I
S
F
I^{SF}
ISF相加。之后使用亚像素卷积来做上采样到
I
S
R
∈
R
T
×
s
H
×
s
W
×
C
o
u
t
I^{SR}\in\mathbb{R}^{T\times sH\times sW\times C_{out}}
ISR∈RT×sH×sW×Cout。
Note:
- 对于输入是 64 × 64 64\times 64 64×64来说,最后的 I S R ∈ R T × 256 × 256 × 3 I^{SR}\in\mathbb{R}^{T\times 256\times 256\times 3} ISR∈RT×256×256×3。
对于损失函数,VRT采用charbonnier:
L
=
∣
∣
I
S
R
−
I
L
R
∣
∣
2
+
ϵ
2
,
ϵ
=
1
0
−
3
.
(1)
\mathcal{L} = \sqrt{||I^{SR} - I^{LR}||^2 + \epsilon^2}, \;\epsilon=10^{-3}.\tag{1}
L=∣∣ISR−ILR∣∣2+ϵ2,ϵ=10−3.(1)
3.2 Temporal Mutual Self Attention
TMSA就是Transformer中的Encoder部分,由注意力和前馈神经网络组成;在VRT中,注意力层使用MMA和MSA的融合,FFN使用GEGLU模块。
Mutual Attention
\colorbox{yellow}{Mutual Attention}
Mutual Attention
首先我们来介绍多头互注意力MMA:简单来说就是相邻2帧
X
1
,
X
2
X_1, X_2
X1,X2(VRT中是相邻2帧上相同空间位置处的2个窗口)之间,你对我做一次注意力计算,我再对你做一次注意力计算,最后2个结果相融合。和MSA不同的是,MMA是拿
X
1
X_1
X1自己的Query去
X
2
X_2
X2中搜寻token完成相似度计算;然后
X
2
X_2
X2拿着自己的Query去
X
1
X_1
X1中搜寻token完成相似度计算。
源码如下:
x1_aligned = self.attention(q2, k1, v1, mask, (B_, N // 2, C), relative_position_encoding=False)
x2_aligned = self.attention(q1, k2, v2, mask, (B_, N // 2, C), relative_position_encoding=False)
接下来具体介绍MMA。
这里我们得引出参考帧
X
R
∈
R
N
×
C
X^R\in\mathbb{R}^{N\times C}
XR∈RN×C和支持帧
X
S
∈
R
N
×
C
X^S\in\mathbb{R}^{N\times C}
XS∈RN×C。其中
N
N
N为token的个数,在VRT中相当于1个窗口内的像素总和
w
H
×
w
W
wH\times wW
wH×wW,这是因为
C
C
C早就变成token-embedding的维度了,这也是VRT创造token的特殊方式。
然后我们将输入参考帧的Query——
Q
R
Q^R
QR,支持帧的Key和Value——
K
S
、
V
S
K^S、V^S
KS、VS通过线性层表示出来,这都是Transformer的常规步骤了:
Q
R
=
X
R
P
Q
,
K
S
=
X
S
P
K
,
V
S
=
X
S
P
V
.
(2)
Q^{R} = X^{R} P^Q, \;\;\; K^S = X^S P^K, \;\;\; V^S = X^S P^V.\tag{2}
QR=XRPQ,KS=XSPK,VS=XSPV.(2)其中
P
Q
、
P
K
、
P
V
∈
R
C
×
D
P^Q、P^K、P^V\in\mathbb{R}^{C\times D}
PQ、PK、PV∈RC×D是线性层,可以用卷积或者FC表示,源码中
D
=
C
D=C
D=C。
接下来我们的MMA的注意力计算如下:
M
A
(
Q
R
,
K
S
,
V
S
)
=
S
o
f
t
m
a
x
(
Q
R
(
K
S
)
T
D
)
V
S
.
(3)
MA(Q^R, K^S, V^S) = Softmax(\frac{Q^R (K^S)^T}{\sqrt{D}})V^S.\tag{3}
MA(QR,KS,VS)=Softmax(DQR(KS)T)VS.(3)和我们的自注意力计算是一样的,只不过
Q
Q
Q和
K
,
V
K,V
K,V属于不同的帧。
Note:
- Softmax是针对注意力矩阵的行来做的,即将每一行的 N N N个相似度变成softmax的分布。
- 在代码中,注意力矩阵和 V V V的结合可以直接用矩阵相乘实现。
接下来我们分析MMA背后的一些东西,首先将式(3)简化成注意力计算的一般形式:
Y
i
,
:
R
=
∑
j
=
1
N
A
i
,
j
V
j
,
:
S
.
(4)
Y^R_{i, :} = \sum^N_{j=1} A_{i, j} V^S_{j, :}.\tag{4}
Yi,:R=j=1∑NAi,jVj,:S.(4)其中
i
∈
I
i\in\mathcal{I}
i∈I表示所有的token,
j
∈
J
j\in\mathcal{J}
j∈J表示搜索范围内的token;
Y
Y
Y表示和
Q
Q
Q对应的输出的新token,其聚集了搜索范围内的token信息;
K
,
V
K,V
K,V是同一个token的不同表达;
A
i
,
j
A_{i,j}
Ai,j则表示
i
t
h
i^{th}
ithtoken和
j
t
h
j^{th}
jthtoken之间的相似度。
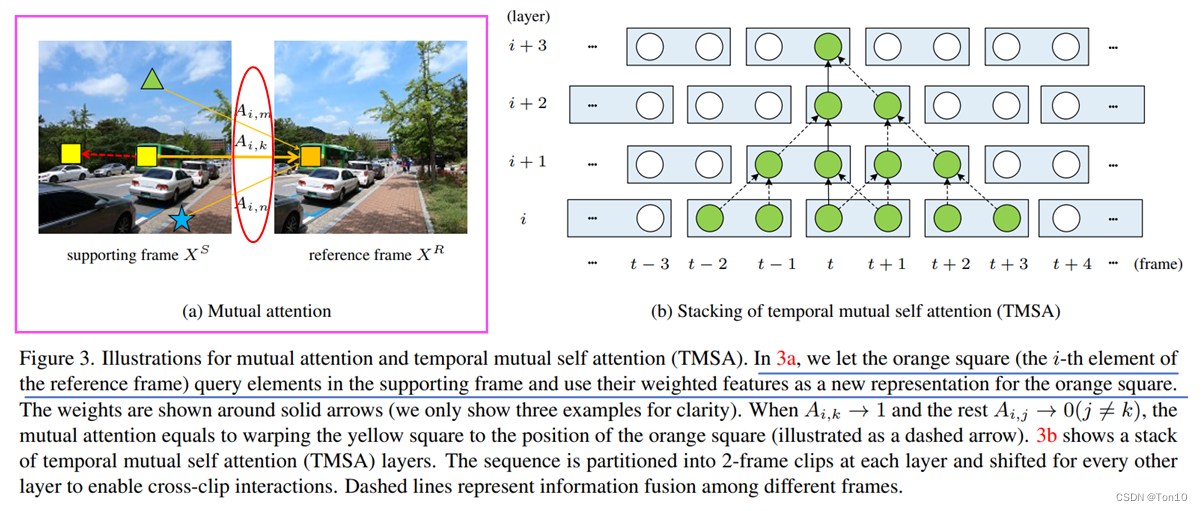
如上图(a)所示是2帧之间的相似度计算,计算了3个
A
i
,
m
,
A
i
,
k
,
A
i
,
n
A_{i, m},A_{i, k}, A_{i, n}
Ai,m,Ai,k,Ai,n,则当对于
∀
j
≠
k
(
j
≤
N
)
\forall j\ne k (j\leq N)
∀j=k(j≤N),都有
A
i
,
k
>
A
i
,
j
A_{i, k} > A_{i, j}
Ai,k>Ai,j,则说明支持帧中
k
t
h
k^{th}
kth个token和参考帧中
i
t
h
i^{th}
ith个token是最相似的。特别的,当除了
k
t
h
k^{th}
kth个token以外所有的token都和参考帧中
i
t
h
i^{th}
ith个token都十分不同时,则有如下表达:
{
A
i
,
k
→
1
,
A
i
,
j
→
0
,
f
o
r
j
≠
k
,
j
≤
N
.
(5)
\begin{cases} A_{i, k}\to 1, \\ A_{i, j}\to 0, \;\;\;\;\;\; for\;\;\; j\ne k, j\leq N \end{cases}.\tag{5}
{Ai,k→1,Ai,j→0,forj=k,j≤N.(5)那么此时就有
Y
i
,
:
R
=
V
k
,
:
S
Y^R_{i, :} = V_{k, :}^S
Yi,:R=Vk,:S,这就相当于将支持帧中的
k
t
h
k^{th}
kth个token移到了参考帧中
i
t
h
i^{th}
ith的位置出。这其实就是TTVSR中的硬注意力机制,其是一种隐式的运动补偿。这种硬注意力等效于warp,其结果就是实现了支持帧和参考帧的对齐。
为什么MMA具有对齐功能呢?
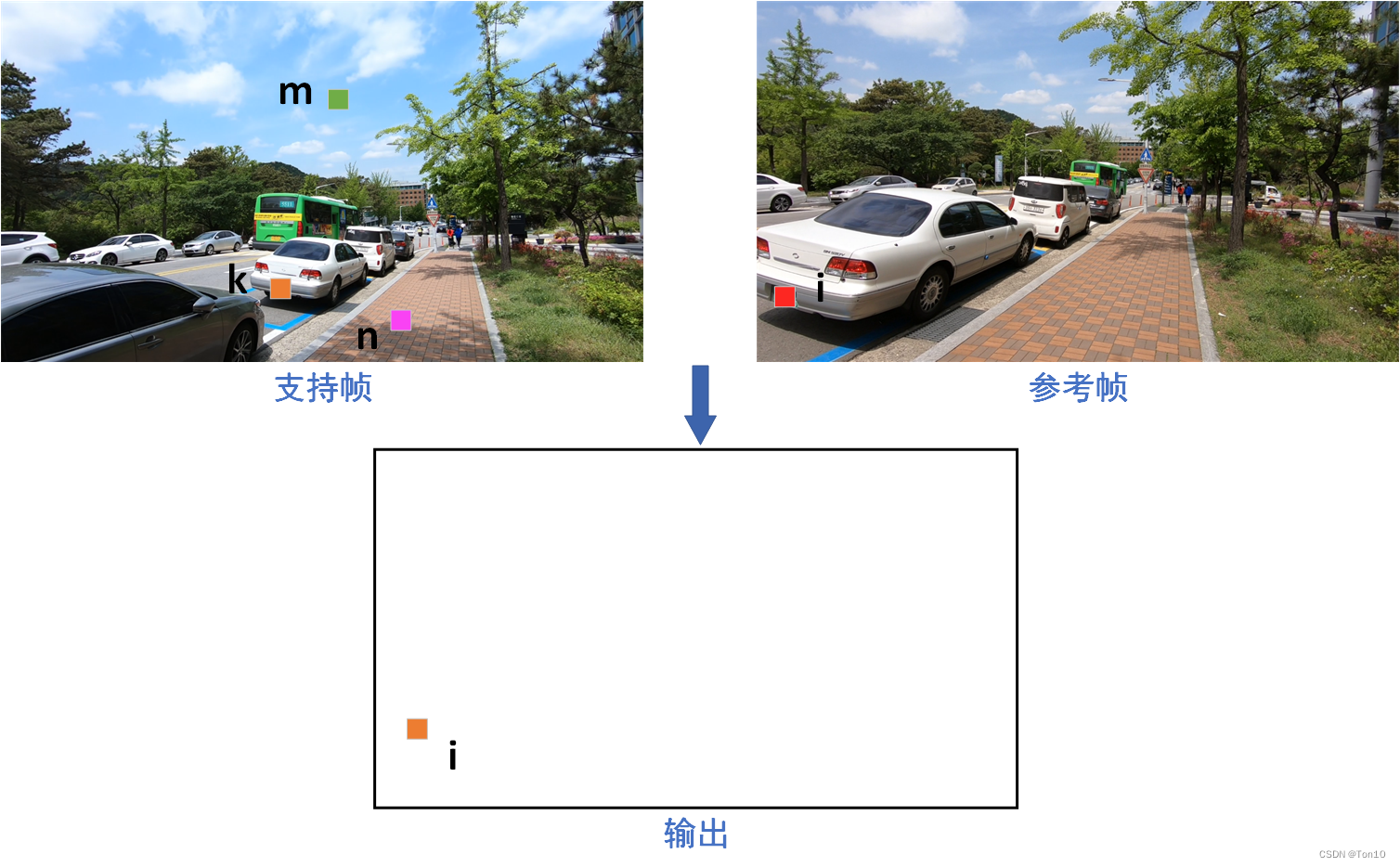
具体解释如上图所示,由于输出新的token是和Query的索引是一致的,故输出在和参考帧中相同位置处的token就是支持帧中
k
t
h
k^{th}
kth的token复制过来的。这种复制就和flow-based对齐的复制很类似,因此MMA可以说成是隐式的光流估计+warp的过程。
Note:
- 那么自然当式(5)不符合时候,式(4)就变成了soft版本的隐式warp的过程。
- 上述两帧不是相邻帧,但为了视觉效果,就将它两当相邻帧处置。
接下来将参考帧和支持帧换个位置,再做一次式子(3),就得到了第二个结果,我们将上述2个结果进行融合就是最终MA的结果。和自注意力一样,MA也可以引入多头(multi-head)的做法,成为MMA。
MMA相对于flow-based对齐的优势:
- 硬注意力的MMA可以直接保存原有的特征信息,它直接复制目标token,而不涉及插值的运算,flow-based这种方式不可避免引入插值运算,会损失一定的高频信息且容易引入混叠等artifacts。
- MMA基于Transformer,因此其没有flow-based基于CNN那样对于局部相关性的归纳偏置,但这也带来了好处:当1个token中几个像素之间的运动方向都是不同的话,flow-based在处理的时候就会进行插值操作,那么最后warp出的某个像素点的值一定是有问题的;而MMA直接复制的做法就不会受到影响。
- MMA属于one-stage对齐,它一次性完成了flow-based对齐中光流估计+warp2个操作的过程。
MMA实际上是在窗口上做的,我们设窗口为为
(
2
,
N
,
N
)
(2, \sqrt{N}, \sqrt{N})
(2,N,N),则MMA的输入为
X
∈
R
2
×
N
×
C
X\in\mathbb{R}^{2\times N\times C}
X∈R2×N×C,如果是自注意力,就直接在
2
N
2N
2N个token上做注意力,这和VSRT的时空注意力是一样的,而MMA首先用torch.chunk将
X
X
X沿时间轴劈成2份——
X
1
∈
R
1
×
N
×
C
、
X
2
∈
R
1
×
N
×
C
X_1\in\mathbb{R}^{1\times N\times C}、X_2\in\mathbb{R}^{1\times N\times C}
X1∈R1×N×C、X2∈R1×N×C,然后执行:
X
1
→
w
a
r
p
X
2
,
X
2
→
w
a
r
p
X
1
.
X_1 \mathop{\rightarrow}\limits^{warp} X_2, \\ X_2 \mathop{\rightarrow}\limits^{warp} X_1.
X1→warpX2,X2→warpX1.并将2个结果进行融合即可。
Temporal mutual self attention
\colorbox{orange}{Temporal mutual self attention}
Temporal mutual self attention
MMA会将2帧的信息进行互相对齐,但会失去原有的特征信息,故作者又设置了自注意力MMA来保存MMA失去的信息。MMA采用基于windows的自注意力计算,和VSRT一样相当于时空注意力层。具体做法是将MMA和MSA在token-embedding维度上融合,然后使用FC进行通道缩减。MMA和MSA的结合就是TMSA的注意力层,然后再接FFN就是完整的TMSA模块,具体表达式如下:
X
1
,
X
2
=
S
p
l
i
t
0
(
L
N
(
X
)
)
Y
1
,
Y
2
=
M
M
A
(
X
1
,
X
2
)
,
M
M
A
(
X
2
,
X
1
)
Y
3
=
M
S
A
(
[
X
1
,
X
2
]
)
X
=
M
L
P
(
C
o
n
c
a
t
2
(
C
o
n
c
a
t
1
(
Y
1
,
Y
2
)
,
Y
3
)
)
+
X
X
=
M
L
P
(
L
N
(
X
)
)
+
X
.
(6)
X_1, X_2 = Split_0(LN(X))\\ Y_1, Y_2 = MMA(X_1, X_2), \; MMA(X_2, X_1)\\ Y_3 = MSA([X_1, X_2])\\ X = MLP(Concat_2(Concat_1(Y_1, Y_2), Y_3)) + X\\ X = MLP(LN(X)) + X.\tag{6}
X1,X2=Split0(LN(X))Y1,Y2=MMA(X1,X2),MMA(X2,X1)Y3=MSA([X1,X2])X=MLP(Concat2(Concat1(Y1,Y2),Y3))+XX=MLP(LN(X))+X.(6)
windows and shifting-windows
\colorbox{gold}{windows and shifting-windows}
windows and shifting-windows
可以看出目前而言,MMA的对齐只能利用相邻2帧之间,这样的时间感受野显然是不够的,能够利用的信息是局部的,为了解决这个问题,VRT采用swin-T中shifting操作的思想,对时间帧进行移动。具体做法为:设窗口为
(
2
,
8
,
8
)
(2, 8, 8)
(2,8,8),正常情况下时间窗口的移动为窗口的一半,即1,当TMSAG中的TMSA为奇数层的时候,我们将序列的时间维度移动1格,否则不移动,并且无论TMSA内部不管是否移动,都会最终恢复到移动前的序列状态。
如此一来,经过时间轴移动之后,
i
t
h
i^{th}
ith的windows在做MMA的时候,就会利用到之前
2
(
i
−
1
)
,
i
≥
2
2(i-1), i\ge 2
2(i−1),i≥2帧的特征信息。具体如下图(b)所示:
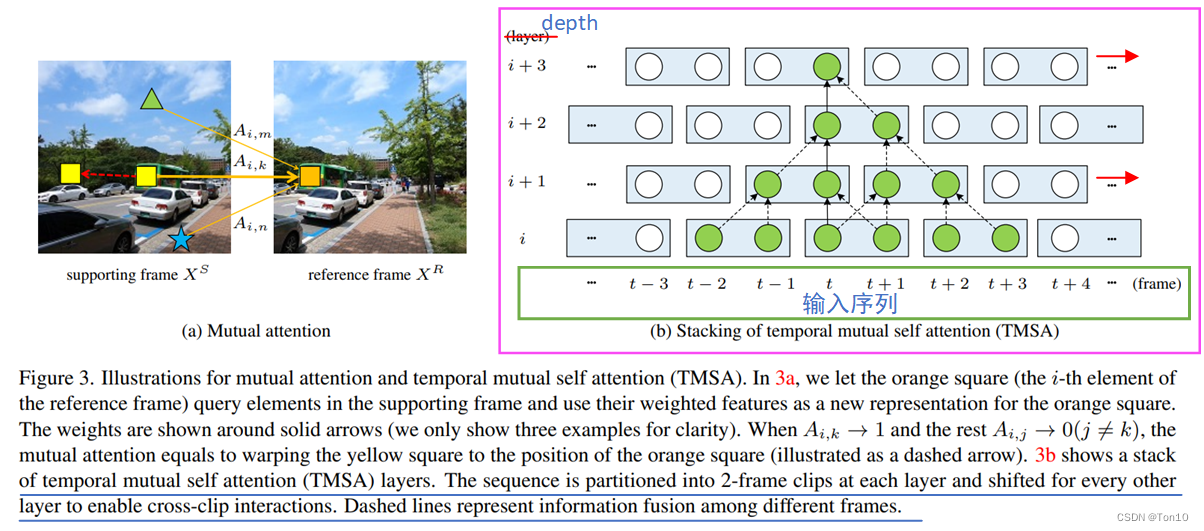
为了减小Transformer因为token过多带来的计算量以及增加特征传播的范围,作者使用了3维的窗口以及3维的shifting-windows,空间上是和swin-T一样的操作,只是少了增大感受野的token融合机制;此外由于VRT应用于视频超分,因此在时间维度上也要增加窗口以及shifting窗口机制。
3.3 Parallel Warping
Parallel Warping本质就是输入序列 x ∈ R B × D × C × H × W x\in\mathbb{R}^{B\times D\times C\times H\times W} x∈RB×D×C×H×W中2帧之间依次使用BasicVSR++提出的flow-guided DCN Alignment对齐,前向和后向都这样做,等序列都做完之后,将前向对齐结果和后向对齐结果以及 x x x做融合,并使用全连接层进行通道缩减。
VRL中用到的光流引导的DCN对齐方式和BasicVSR++是一样的。不过在这里还是再啰嗦一遍吧,如下图所示:
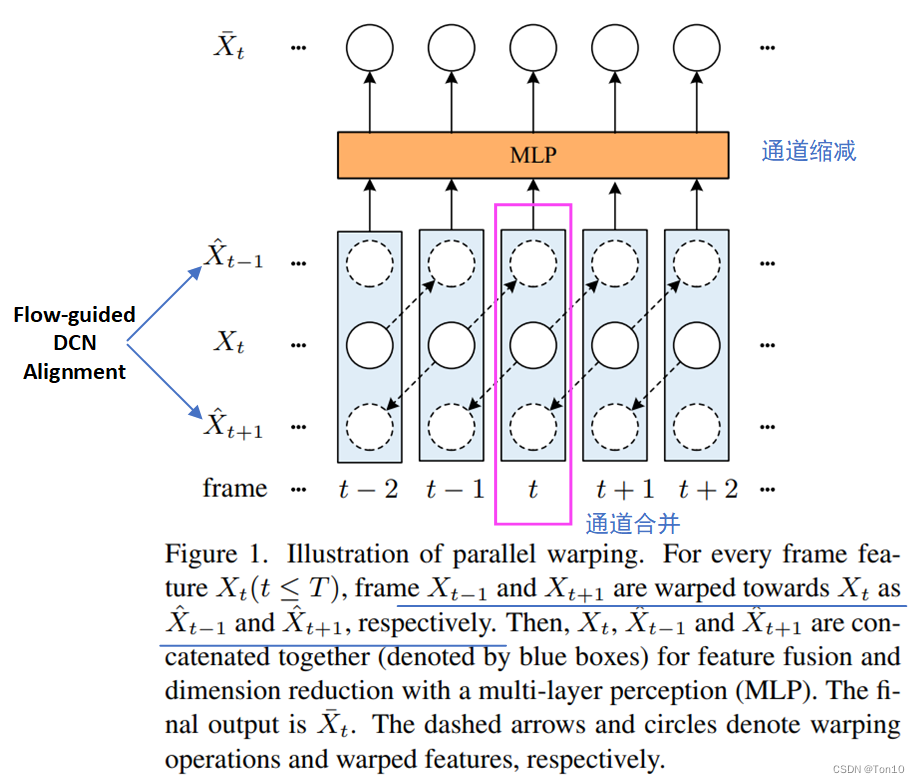
VRT和VSRT一样,需要将2格相邻帧分别和中间帧做对齐,然后将三者进行融合。
设
O
t
−
1
,
t
、
O
t
+
1
,
t
O_{t-1, t}、O_{t+1, t}
Ot−1,t、Ot+1,t分别是2个光流信号;
W
\mathcal{W}
W是flow-based做warp;
X
t
−
1
′
,
X
t
+
1
′
X_{t-1}^{'},X_{t+1}^{'}
Xt−1′,Xt+1′是预对齐之后的结果:
{
X
t
−
1
′
=
W
(
X
t
−
1
,
O
t
−
1
,
t
)
,
X
t
+
1
′
=
W
(
X
t
+
1
,
O
t
+
1
,
t
)
.
(7)
\begin{cases} X_{t-1}^{'} = \mathcal{W}(X_{t-1}, O_{t-1, t}),\\ X_{t+1}^{'} = \mathcal{W}(X_{t+1}, O_{t+1, t}).\tag{7} \end{cases}
{Xt−1′=W(Xt−1,Ot−1,t),Xt+1′=W(Xt+1,Ot+1,t).(7)
接下来使用1个轻量的多个CNN叠加的网络
C
\mathcal{C}
C去学习残差部分的offset和modulation mask:
o
t
−
1
,
t
,
o
t
+
1
,
t
,
m
t
−
1
,
t
,
m
t
+
1
,
t
=
C
(
C
o
n
c
a
t
(
O
t
−
1
,
t
,
O
t
+
1
,
t
)
,
X
t
−
1
′
,
X
t
+
1
′
)
.
(8)
o_{t-1, t}, o_{t+1, t}, m_{t-1, t}, m_{t+1, t} = \mathcal{C}(Concat(O_{t-1, t}, O_{t+1, t}), X_{t-1}^{'}, X_{t+1}^{'}).\tag{8}
ot−1,t,ot+1,t,mt−1,t,mt+1,t=C(Concat(Ot−1,t,Ot+1,t),Xt−1′,Xt+1′).(8)
最终使用
D
C
N
DCN
DCN来做warp,用
D
\mathcal{D}
D表示,对齐的结果为
X
^
t
−
1
,
X
^
t
+
1
\hat{X}_{t-1}, \hat{X}_{t+1}
X^t−1,X^t+1:
{
X
^
t
−
1
=
D
(
X
t
−
1
,
O
t
−
1
,
t
+
o
t
−
1
,
t
,
m
t
−
1
,
t
)
,
X
^
t
+
1
=
D
(
X
t
+
1
,
O
t
+
1
,
t
+
o
t
+
1
,
t
,
m
t
+
1
,
t
)
.
(9)
\begin{cases} \hat{X}_{t-1} = \mathcal{D}(X_{t-1}, {\color{red}O_{t-1, t}+o_{t-1, t}}, m_{t-1, t}), \\ \hat{X}_{t+1} = \mathcal{D}(X_{t+1}, {\color{pink}O_{t+1, t}+ o_{t+1, t}}, m_{t+1, t}).\tag{9} \end{cases}
{X^t−1=D(Xt−1,Ot−1,t+ot−1,t,mt−1,t),X^t+1=D(Xt+1,Ot+1,t+ot+1,t,mt+1,t).(9)
4 Experiments
4.1 Experimental Setup
①VRT实验设置:
- 共设置4种尺度(stage1~7),对于 64 × 64 64\times 64 64×64的patch,设置 64 × 64 、 32 × 32 、 16 × 16 、 8 × 8 64\times 64、32\times 32、16\times 16、8\times 8 64×64、32×32、16×16、8×8四种分辨率。对于每一种尺度设置8个TMSA模块,其中前6个时间窗口为2,后2个时间窗口为8(对于输入序列为16帧的时候)且无MMA。空间窗口为 8 × 8 8\times 8 8×8,head数为6。最后一组TMSA模块(stage8)设置6个TMSAG,每个里面有4个TMSA模块且都是自注意力无MMA。
- 对于stage1~7,token-embedding维度设置为120,而stage8则设置为180。
- 光流估计使用SpyNet网络(前2W个iterations固定参数,学习率设为 5 × 1 0 − 5 5\times 10^{-5} 5×10−5),FFN使用GRGLU网络。
- batch设为8,iterations设为30W次。
- 使用Adam和CA做优化,初始学习率设为 4 × 1 0 − 4 4\times 10^{-4} 4×10−4,并逐渐下降。
- 输入的patch选择为 64 × 64 64\times 64 64×64。
- 实验共训练2种序列长度——5和16,分别在8张A100上耗时5和10天。
②数据集:
还是老样子的那几个:REDS、Vimeo-90K。具体的就不介绍了,都太熟悉了,只说一下REDS4是
c
l
i
p
s
{
000
,
011
,
015
,
020
}
clips\{000, 011, 015, 020\}
clips{000,011,015,020}。
4.2 Video SR
实验的结果如下:
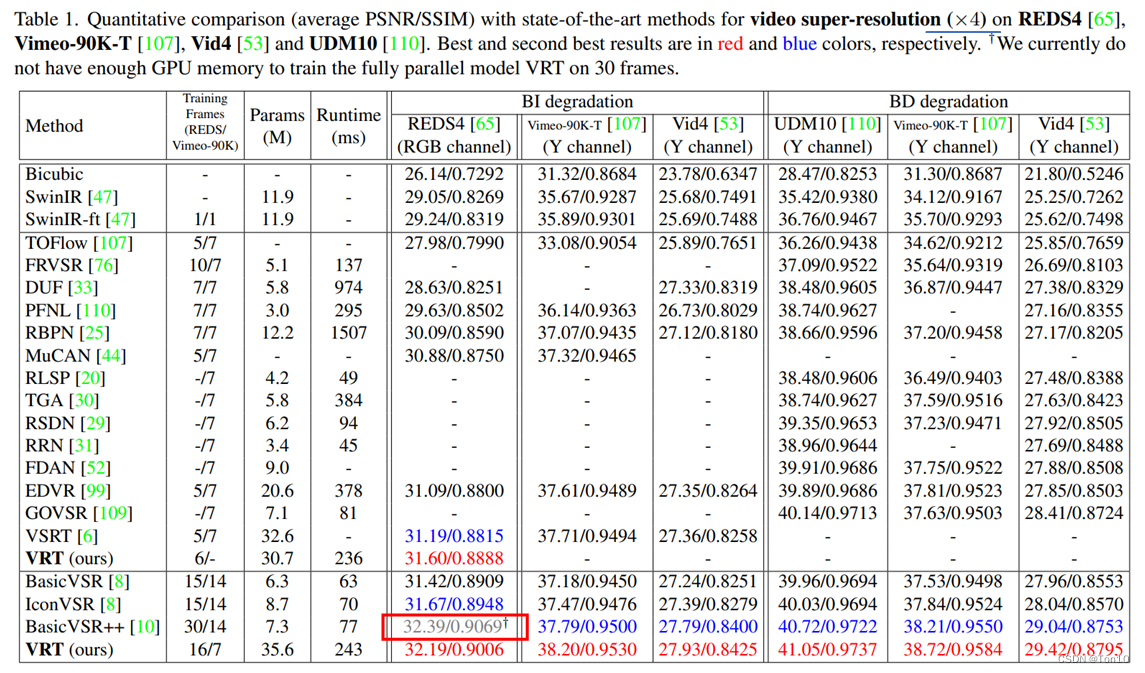
实验结论如下:
- 在VSRT的论文实验中已经证明了BasicVSR在短序列上较弱的表现力,而VRT可以在短序列和长序列上都有不错的表现力,尤其是在短序列上,由于其较好的聚合了局部空间信息,所以哪怕序列长度较短,也可以较好的重建视频。
- VRT在REDS上略微逊色于BasicVSR++,这是因为VRT只在16帧上训练,而后者是在30帧上训练的结果。
可视化结果如下:

4.3 Video Deblurring
略
4.4 Video Denoising
略
4.5 Ablation Study
Multi-scale & Parallel warping
\colorbox{tomato}{Multi-scale \& Parallel warping}
Multi-scale & Parallel warping
为了探究多种尺度和PW的影响,相关实验结果如下:

实验结论如下:
- 可以看出尺度越丰富对于性能的提升越多,这是因为多尺度可以保证VRT可以利用多种分辨率的特征信息,较大的感受野可以处理大运动问题。
- PW也带来了0.17dB的性能提升。
TMSA
\colorbox{yellow}{TMSA}
TMSA
为了探究TMSA中MMA和MSA的影响,相关实验结果如下:
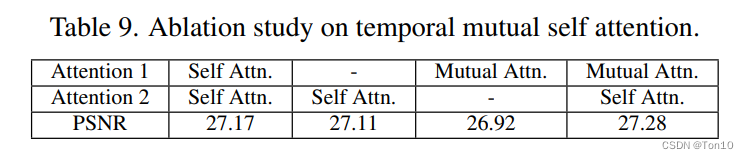
实验结论如下:
- 单单只有MMA而没有MSA是不行的,因为MMA会丢失原有的特征信息。
- 在增加了MMA和MSA的情况下,VRT的表现力得到了提升。
Window size
\colorbox{lightskyblue}{Window size}
Window size
在每个尺度下的TMSAG中,作者将后面2个TMSA的时间感受野增加,这是为了进一步增加长序列范围内捕捉特征信息的能力。相关实验结果如下:

实验结论如下:
- 时间窗口从1到2对于PSNR的提升有限,但是到8的时候,还是有一定程度上的改进,因此最后时间维度的窗口大小就设定了8。
5 Conclusion
- 文章推出了一种基于Vision-Transformer的并行化视频超分模型——VRT。VRT基于多尺度(
multi-scale)的方式来做不同分辨率下的对齐,同时不同的尺度可以提取出不同的局部特征信息。VRT总体架构分为特征提取和SR重建2个部分,其可以适用于多种视频恢复任务。 - VRT汲取swin-T的思想,在空间和时间尺度上都进行shifting,从而分别保证了空间局部相关性的集聚和长序列捕捉全局相关性的能力。
- VRT介绍了MMA,一种互注意力机制,不同于自注意力用来提取时空特征,MMA可以用来做one-stage的特征对齐。此外MMA和MSA都是基于窗口的,除了可以较好的提取局部信息还可以减少相似度的计算量。
- VRT吸取BasicVSR++中光流引导的DCN对齐方式,对VSRT中flow-based对齐做出改进,从而推出了Parallel Warping模块。
















 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









