







文章目录
[Song Y. and Ermon S. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems (NIPS), 2019.](Generative Modeling by Estimating Gradients of the Data Distribution)
概
当前生成模型, 要么依赖对抗损失(GAN), 要么依赖替代损失(VAE), 本文提出了基于score matching 训练, 以及利用annealed Langevin dynamics推断的模型, 思想非常有趣.
主要内容
Langevin dynamics
对于分布
p
(
x
)
p(x)
p(x), 我们可以通过下列方式迭代生成
x
~
t
=
x
~
t
−
1
+
ϵ
2
∇
x
log
p
(
x
~
t
−
1
)
+
ϵ
z
t
,
\tilde{x}_t = \tilde{x}_{t-1} + \frac{\epsilon}{2} \nabla_x \log p (\tilde{x}_{t-1}) + \sqrt{\epsilon} z_t,
x~t=x~t−1+2ϵ∇xlogp(x~t−1)+ϵzt,
其中
x
~
0
∼
π
(
x
)
\tilde{x}_0 \sim \pi(x)
x~0∼π(x)来自一个先验分布,
z
t
∼
N
(
0
,
I
)
z_t \sim \mathcal{N}(0, I)
zt∼N(0,I). 当步长
ϵ
→
0
\epsilon \rightarrow 0
ϵ→0并且
T
→
+
∞
T \rightarrow +\infty
T→+∞的时候,
x
~
T
\tilde{x}_T
x~T可以认为是从
p
(
x
)
p(x)
p(x)中采样的样本.
注: 一般的Langevin, dynamics还需要在每一次迭代后计算一个接受概率然后判断是否接受, 不过在实际中这一步往往可以省略.
Score Matching
通过上述的迭代可以发现, 我们只需要获得
∇
x
log
p
(
x
)
\nabla_x \log p(x)
∇xlogp(x)即可采样
x
x
x, 我们可以期望通过下面的方式, 通过一个网络
s
θ
(
x
)
s_{\theta}(x)
sθ(x)来逼近
∇
x
log
p
d
a
t
a
(
x
)
\nabla_x \log p_{data}(x)
∇xlogpdata(x):
min
θ
1
2
E
p
d
a
t
a
(
x
)
[
∥
s
θ
(
x
)
−
∇
x
log
p
d
a
t
a
(
x
)
∥
2
2
]
,
\min_{\theta} \: \frac{1}{2} \mathbb{E}_{p_{data}(x)} [\| s_{\theta} (x) - \nabla_x \log p_{data}(x) \|_2^2],
θmin21Epdata(x)[∥sθ(x)−∇xlogpdata(x)∥22],
但是在实际中, 先验
log
p
d
a
t
a
(
x
)
\log p_{data}(x)
logpdata(x)也是未知的, 幸运的是上述公式等价于:
min
θ
E
p
d
a
t
a
(
x
)
[
t
r
(
∇
x
s
θ
(
x
)
)
+
1
2
∥
s
θ
(
x
)
∥
2
2
]
.
\min_{\theta} \: \mathbb{E}_{p_{data}(x)} [\mathrm{tr}(\nabla_x s_{\theta} (x)) + \frac{1}{2} \|s_{\theta}(x)\|_2^2].
θminEpdata(x)[tr(∇xsθ(x))+21∥sθ(x)∥22].
注: 见 score matching
Denoising Score Matching
一个共识是, 所获得的数据往往是一个低维流形, 即其内在的维度实际上很低. 所以
E
p
d
a
t
a
(
x
)
\mathbb{E}_{p_{data}(x)}
Epdata(x)在实际中会出现高密度的区域估计得很好, 但是低密度得区域估计得非常差. Denosing Score Matching提高了一个较为鲁棒的替代方法:
min
θ
1
2
E
q
σ
(
x
~
∣
x
)
p
d
a
t
a
(
x
)
[
∥
s
θ
(
x
~
)
−
∇
x
log
q
σ
(
x
~
∣
x
)
∥
2
2
]
.
\min_{\theta} \: \frac{1}{2} \mathbb{E}_{q_{\sigma}(\tilde{x}|x)p_{data}(x)} [\| s_{\theta} (\tilde{x}) - \nabla_x \log q_{\sigma}(\tilde{x}|x) \|_2^2].
θmin21Eqσ(x~∣x)pdata(x)[∥sθ(x~)−∇xlogqσ(x~∣x)∥22].
当优化得足够好的时候,
s
θ
∗
(
x
)
=
∇
x
log
q
σ
(
x
)
,
q
σ
(
x
~
)
:
=
∫
q
σ
(
x
~
∣
x
)
p
d
a
t
a
(
x
)
d
x
.
s_{\theta^*}(x) = \nabla_x \log q_{\sigma}(x), \: q_{\sigma}(\tilde{x}) := \int q_{\sigma}(\tilde{x}|x) p_{data}(x) \mathrm{d}x.
sθ∗(x)=∇xlogqσ(x),qσ(x~):=∫qσ(x~∣x)pdata(x)dx.
实际中, 通常取
q
σ
(
x
~
∣
x
)
=
N
(
x
~
∣
x
,
σ
2
I
)
q_{\sigma}(\tilde{x}|x) = \mathcal{N}(\tilde{x}|x, \sigma^2 I)
qσ(x~∣x)=N(x~∣x,σ2I), 相当于在真实数据
x
x
x上加了一个扰动, 当扰动足够小(
σ
\sigma
σ足够小)的时候,
q
σ
(
x
)
≈
p
d
a
t
a
(
x
)
q_{\sigma}(x) \approx p_{data}(x)
qσ(x)≈pdata(x), 则
s
θ
∗
(
x
)
≈
∇
x
log
p
d
a
t
a
(
x
)
s_{\theta^*}(x) \approx \nabla_x \log p_{data}(x)
sθ∗(x)≈∇xlogpdata(x).
注: 为啥期望部分要有 p d a t a p_{data} pdata? 实际上上述目标和score matching依旧是等价的.
Noise Conditional Score Networks
Slow mixing of Langevin dynamics
假设
p
d
a
t
a
(
x
)
=
π
p
1
(
x
)
+
(
1
−
π
)
p
2
(
x
)
p_{data}(x) = \pi p_1(x) + (1 - \pi)p_2(x)
pdata(x)=πp1(x)+(1−π)p2(x), 且
p
1
,
p
2
p_1, p_2
p1,p2的支撑集合是互斥的, 那么
∇
x
log
p
d
a
t
a
(
x
)
\nabla_{x} \log p_{data}(x)
∇xlogpdata(x)要么为
∇
x
log
p
1
(
x
)
\nabla_{x} \log p_{1}(x)
∇xlogp1(x)或者
∇
x
log
p
2
(
x
)
\nabla_{x} \log p_{2}(x)
∇xlogp2(x), 与
π
\pi
π没有丝毫关联, 这会导致训练的结果与
π
\pi
π也没有关联. 在实际中, 若
p
1
,
p
2
p_1, p_2
p1,p2近似互斥, 也会产生类似的情况:
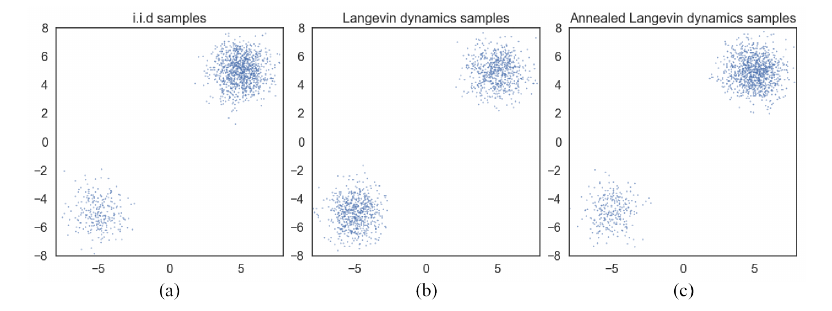
如上图所示, 通过Langevin dynamics采样的点几乎是1:1的, 这与真实的分布便有了出入.
作者的想法是, 设计一个noise conditional score networks:
s
θ
(
x
,
σ
)
,
s_\theta(x, \sigma),
sθ(x,σ),
给定不同的
σ
\sigma
σ其拟合不同扰动大小的
p
σ
p_{\sigma}
pσ, 在采样中, 首先用大一点的
σ
\sigma
σ, 然后再逐步缩小, 这便是一种退火的思想. 显然, 一开始用大一点的
σ
\sigma
σ能够为后面的采样提供更好更鲁棒的初始点.
损失函数
设定
σ
i
,
i
=
1
,
2
,
⋯
,
L
\sigma_i, i=1,2,\cdots, L
σi,i=1,2,⋯,L, 且满足:
σ
1
σ
2
=
⋯
=
σ
L
−
1
σ
L
>
1
,
\frac{\sigma_1}{\sigma_2} = \cdots = \frac{\sigma_{L-1}}{\sigma_L} > 1,
σ2σ1=⋯=σLσL−1>1,
即一个等比例(缩小)的数列.
对于每个
σ
\sigma
σ采用如下损失:
ℓ
(
θ
;
σ
)
=
1
2
E
p
d
a
t
a
(
x
)
E
N
(
x
~
∣
x
,
σ
I
)
[
∥
s
θ
(
x
~
,
σ
)
+
x
~
−
x
σ
2
∥
2
2
]
.
\ell(\theta; \sigma) = \frac{1}{2} \mathbb{E}_{p_{data}(x)} \mathbb{E}_{\mathcal{N}(\tilde{x}|x, \sigma I)} [\| s_{\theta} (\tilde{x}, \sigma) + \frac{\tilde{x} - x}{\sigma^2} \|_2^2].
ℓ(θ;σ)=21Epdata(x)EN(x~∣x,σI)[∥sθ(x~,σ)+σ2x~−x∥22].
注: ∇ x ~ q σ ( x ~ ∣ x ) = − x ~ − x σ 2 \nabla_{\tilde{x}} q_{\sigma}(\tilde{x}|x) = -\frac{\tilde{x} - x}{\sigma^2} ∇x~qσ(x~∣x)=−σ2x~−x.
于是总损失为
L
(
θ
;
{
σ
i
}
i
=
1
L
)
:
=
1
L
∑
i
=
1
L
λ
(
σ
i
)
ℓ
(
θ
;
σ
i
)
,
\mathcal{L}(\theta; \{\sigma_i\}_{i=1}^L) := \frac{1}{L}\sum_{i=1}^L \lambda (\sigma_i)\ell(\theta;\sigma_i),
L(θ;{σi}i=1L):=L1i=1∑Lλ(σi)ℓ(θ;σi),
λ
(
σ
i
)
\lambda(\sigma_i)
λ(σi)为权重系数.
Annealed Langevin dynamics
Input: { σ i } i = 1 L , ϵ , T \{\sigma_i\}_{i=1}^L, \epsilon, T {σi}i=1L,ϵ,T;
- 初始化 x 0 x_0 x0;
- For
i
=
1
,
2
,
⋯
,
L
i=1,2,\cdots, L
i=1,2,⋯,L do:
- α i ← ϵ ⋅ σ i 2 / σ L 2 \alpha_i \leftarrow \epsilon \cdot \sigma_i^2 / \sigma_L^2 αi←ϵ⋅σi2/σL2;
- For
t
=
1
,
2
,
⋯
,
T
t=1,2,\cdots, T
t=1,2,⋯,T do:
- 采样 z t ∼ N ( 0 , I ) z_t \sim \mathcal{N}(0, I) zt∼N(0,I);
- x t ← x t − 1 + α i 2 s θ ( x t − 1 , σ ) + α i z t x_t \leftarrow x_{t-1} + \frac{\alpha_i}{2}s_{\theta}(x_{t-1}, \sigma) + \sqrt{\alpha_i} z_t xt←xt−1+2αisθ(xt−1,σ)+αizt;
- x 0 ← x T x_0 \leftarrow x_T x0←xT;
Output: x T x_T xT.
细节
-
关于参数 λ ( σ ) \lambda(\sigma) λ(σ)的选择:
作者推荐选择 λ ( σ ) = σ 2 \lambda(\sigma) = \sigma^2 λ(σ)=σ2, 因为当优化到最优的时候, ∥ s θ ( x , σ ) ∥ 2 ∝ 1 / σ \|s_{\theta}(x, \sigma)\|_2 \propto 1 / \sigma ∥sθ(x,σ)∥2∝1/σ, 故 σ 2 ℓ ( θ ; σ ) = 1 2 E [ ∥ σ s θ ( x , σ ) + x ~ − x σ ∥ 2 2 ] \sigma^2 \ell(\theta;\sigma) = \frac{1}{2}\mathbb{E}[\|\sigma s_{\theta}(x, \sigma) + \frac{\tilde{x} - x}{\sigma} \|_2^2] σ2ℓ(θ;σ)=21E[∥σsθ(x,σ)+σx~−x∥22], 其中 σ s θ ( x , σ ) ∝ 1 , x ~ − x σ ∼ N ( 0 , I ) \sigma s_{\theta}(x, \sigma) \propto 1, \frac{\tilde{x} - x}{\sigma} \sim \mathcal{N}(0, I) σsθ(x,σ)∝1,σx~−x∼N(0,I), 故 σ 2 ℓ θ , σ \sigma^2 \ell_{\theta,\sigma} σ2ℓθ,σ与 σ \sigma σ无关. -
关于 α i ← ϵ ⋅ σ i 2 / σ L 2 \alpha_i \leftarrow \epsilon \cdot \sigma_i^2 / \sigma_L^2 αi←ϵ⋅σi2/σL2:
对于一次Langevin dynamic, 其获得的信息为:
α
i
2
s
θ
(
x
t
−
1
,
σ
)
\frac{\alpha_i}{2} s_{\theta}(x_{t-1}, \sigma)
2αisθ(xt−1,σ), 其噪声为
α
i
z
t
\sqrt{\alpha_i}z_t
αizt, 故其信噪比(signal-to-noise)为(应该是element-wise的计算?)
α
i
s
θ
(
x
,
σ
i
)
2
α
i
z
,
\frac{\alpha_i s_{\theta}(x, \sigma_i)}{2 \sqrt{\alpha_i} z},
2αizαisθ(x,σi),
当我们按照算法中的取法时, 我们有
∥
α
i
s
θ
(
x
,
σ
i
)
2
α
i
z
∥
2
2
≈
α
i
∥
s
θ
(
x
,
σ
i
)
∥
2
2
4
∝
∥
σ
i
s
θ
(
x
,
σ
i
)
∥
2
2
4
∝
1
4
.
\begin{array}{ll} \|\frac{\alpha_i s_{\theta}(x, \sigma_i)}{2 \sqrt{\alpha_i} z}\|_2^2 &\approx\frac{\alpha_i \| s_{\theta}(x, \sigma_i)\|_2^2}{4} \\ &\propto\frac{\|\sigma_i s_{\theta}(x, \sigma_i)\|_2^2}{4} \\ &\propto \frac{1}{4}. \end{array}
∥2αizαisθ(x,σi)∥22≈4αi∥sθ(x,σi)∥22∝4∥σisθ(x,σi)∥22∝41.
故采用此策略能够保证SNR保持一个稳定的值.















 1503
1503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









