







SCN:Deep Networks for Image Super-Resolution with Sparse Prior
1、0范数、p范数等各种范数的意义、计算;为什么基于稀疏编码的方法中要用1范数?
范数,是具有“长度”概念的函数,常常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小。
令向量
0范数:向量中非零元素的个数。
1范数:向量中元素的绝对值之和。
2范数:向量中元素的平方和,再开方。也称欧几里得范数,是向量的模值。
p范数:向量中元素的绝对值的p次方和的1/p次幂。类似于2范数的计算方法。
无穷范数:向量中元素的绝对值的最大值。
为什么基于稀疏编码的方法中要用1范数?
0范数和1范数通常都用来表示稀疏,1范数是0范数 的最优凸近似,且比0范数更好求解。
2、SCN中 迭代式的推导过程
迭代式的推导过程
(1)
由于对后一项求导会遇到绝对值求导数的情况,求导得到的是一个符号函数,所以最终会涉及到一个分情况讨论的情况,这个时候就有了软阈值函数。
所以对于公式(1)的优化结果就是:
3、SCN模型中字典 是怎么得到的?是固定的吗?
是怎么得到的?是固定的吗?
字典对(Dy,Dx)通过对训练块的稀疏编码在其联合空间的推理或通过双层优化进行交替学习,所以是事先学习好的,是固定的。
4、MSCN中每个SR推理模块是一起训练的还是单独训练的?如果是一起训练的,怎么表示不同子空间的特征?
一个SR推理模块的优化目标:
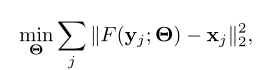
总体优化目标:

由优化目标可以看出是一起训练的。
![]()
这么来表示(?)
5、DBPN中迭代上下采样,为什么要这样迭代上下采样?为什么不直接跟原图比较,而是跟估计图像的上/下采样相比较?

个人理解:下投影单元用来得到LR特征,模拟成像(退化)过程,使退化过程更加符合真实情况;上投影单元上采样得到HR特征,使重建过程更加符合退化过程的逆过程。
前馈体系结构被认为是单向映射,只将输入的丰富表示映射到输出空间。由于LR空间中可用的特征有限,这种方法无法映射LR和HR图像,尤其是在大比例因子下。因此,我们的网络不仅关注使用上采样层生成HR特征的变体,还关注使用下采样层将其投影回LR空间。
我们的网络代表不同类型的图像退化和HR组件。这种能力使网络能够使用所有向上采样步骤中的HR特征映射的深度串联来重建HR图像。
重于提高不同深度的SR特征的采样率,并将计算重建误差的任务分配到每个阶段。该模式使网络能够通过学习各种上下采样运算符来保留HR组件,同时生成更深入的特征。
使用相互连接的上下采样阶段来学习LR和HR图像的非线性关系来指导SR任务。HR和LR图像之间的相互关系是通过创建迭代上下投影单元来构建的。其中上投影单元生成HR特征,然后下投影单元将其投影回LR空间,如图2(d)所示。该模式使网络能够通过学习各种上下采样操作符来保留HR组件,并生成更深的特征来构建大量LR和HR特征。
6、密集连接的好处;Dense-DBPN多个LR特征作为输入的好处。
可以缓解消失梯度问题,产生改进的特征,并能够使特征重用,提高准确率。
7、各向异性、各向同性及其优缺点
对图像来说各向异性就是在每个像素点周围四个方向上梯度变化都不一样;各向同性是说各个方向的值都一致。
各向同性滤波器是旋转不变的,即将原图像旋转后进行铝箔处理给出的结果与先对图像滤波再旋转的结果相同,这种滤波器的相应与其作用的图像的突变方向无关。拉普拉斯算子就是各向同性微分算子。
各向异性滤波是将图像看成物理学的力场或者热流场,图像像素总是向跟他的值相异不是很大的地方流动或者运动,这样那些差异大的地方(边缘)就得以保留,所以本质上各向异性滤波是图像边缘保留滤波器
参考:















 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









