







Flume 架构
Flume 架构图
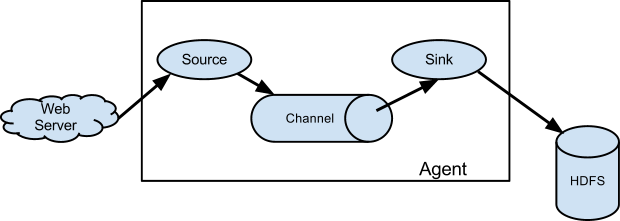
上图是Flume官网最基础的数据流图。后面还会介绍多路复用、拦截等不同配置。
Flume Event
定义
- 一行文本内容被反序列化成一个event。
- event的最大定义为2048字节,超过会被切割放到下一个event中。
- event 包含两个 header、body
- header是一个map,body是一个字节数组
- body是真正传输的数据,header传输的数据不会被sink出去。
源码
- Event.java (Interface)
package org.apache.flume;
import java.util.Map;
/**
* Basic representation of a data object in Flume.
* Provides access to data as it flows through the system.
*/
public interface Event {
/**
* Returns a map of name-value pairs describing the data stored in the body.
*/
public Map<String, String> getHeaders();
/**
* Set the event headers
* @param headers Map of headers to replace the current headers.
*/
public void setHeaders(Map<String, String> headers);
/**
* Returns the raw byte array of the data contained in this event.
*/
public byte[] getBody();
/**
* Sets the raw byte array of the data contained in this event.
* @param body The data.
*/
public void setBody(byte[] body);
}
- ExecSource.java
- 以ExecSource为例,按行扫描的,如果eventList 的大小超过bufferCount, 那就会把剩余的eventList, flush到下一个event里。
while ((line = reader.readLine()) != null) {
sourceCounter.incrementEventReceivedCount();
synchronized (eventList) {
eventList.add(EventBuilder.withBody(line.getBytes(charset)));
if (eventList.size() >= bufferCount || timeout()) {
flushEventBatch(eventList);
}
}
}
private void flushEventBatch(List<Event> eventList) {
channelProcessor.processEventBatch(eventList);
sourceCounter.addToEventAcceptedCount(eventList.size());
eventList.clear();
lastPushToChannel = systemClock.currentTimeMillis();
}
- EventBuilder
- 这里注释写的很清楚,headers是可用可无的,如果是null的话可以忽略。
- withBody方法的参数都是有携带body的
public class EventBuilder {
/**
* Instantiate an Event instance based on the provided body and headers.
* If <code>headers</code> is <code>null</code>, then it is ignored.
* @param body
* @param headers
* @return
*/
public static Event withBody(byte[] body, Map<String, String> headers) {
Event event = new SimpleEvent();
if (body == null) {
body = new byte[0];
}
event.setBody(body);
if (headers != null) {
event.setHeaders(new HashMap<String, String>(headers));
}
return event;
}
public static Event withBody(byte[] body) {
return withBody(body, null);
}
public static Event withBody(String body, Charset charset,
Map<String, String> headers) {
return withBody(body.getBytes(charset), headers);
}
public static Event withBody(String body, Charset charset) {
return withBody(body, charset, null);
}
}
特别注意
- header 可以为null, 也可以在header处设置一些key-value, 方便后面source设置拦截器,然后分别发到各个channel, 最后再sink到不同地方。
- 不建议通过对event的body解析来设置header,因为flume只是数据的搬运工,加工等数据全部sink到指定地方下游后,再去做处理。
更多的可以往下看Interceptors、Channel Selector、Sink Processor 部分有更详细说明。
Flume 组件
Source
下一篇会分享具体的案例。
1. Avro Source
- 监听Avro的端口
- 可以从上一个Avro Sink 端,也就是外部的Avro客户端接收消息
- 也可以创建分层集合拓扑
补充:Avro & Thrift 区别
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
2. Thrift Source
- 监听Thrift的端口
a1.sources.r1.type = thrift
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
3. Exec Source
-
Exec Source 一直监听某个文件,cat tail -F 一起使用。
-
场景:监听某个log4J产生的日志文件/hive日志等。
-
缺点:官网在Exec Source后有个Warning的部分,有提到Exec Source 在传递Event信息给Channel的时候,Channel接收与否,对于Source源来说是无感知的。一旦Channel发生异常,消息没有接收,Exec Source 可能会崩溃。如果想要可靠性高的,使用Spooling Directory 或者Taildir这两种。
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure
4. JMS Source(Active MQ)
从JMS系统(消息、主题)中读取数据
5. Taildir Source(常用!重点!支持断点续传)
-
但目前不支持windows, 通过更改源代码或者增加tail的方式来让windows支持
https://www.cnblogs.com/laoqing/p/12836826.html
-
优点:可以断点续传、比如有100个文件,在传到第60个的时候挂掉了,就会将偏移量记录到json 文件中,恢复后可以再读取第60个文件恢复传输
参数介绍:
| 参数 | 解释 |
|---|---|
| positionFile | 记录偏移量的文件路径 |
| filegroups | 设置多个监控文件路径 |
| headers.. | 设置header的值,如果有多个,可以设成一组 |
| idleTimeout | 关闭不活跃的文件的时间,如果重新写入的话,会再reopen |
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /var/log/flume/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /var/log/test1/example.log
a1.sources.r1.headers.f1.headerKey1 = value1
a1.sources.r1.filegroups.f2 = /var/log/test2/.*log.*
a1.sources.r1.headers.f2.headerKey1 = value2
a1.sources.r1.headers.f2.headerKey2 = value2-2
a1.sources.r1.fileHeader = true
a1.sources.ri.maxBatchCount = 1000
6. Spooling Directory Source 监控文件夹
-
监控这个文件夹下面是否有新的文件,这种方式也是可靠的
-
有两点要注意的:
- 拷贝到spool目录下的文件不可以再打开编辑
- spool目录下不可包含相应的子目录。
-
官网建议尽量生成日志的时候,给日志加上时间戳来命名,防止出现错误
参数介绍:
| 参数 | 解释 |
|---|---|
| fileSuffix | 文件读取后添加的后缀名 默认是.COMPLETED 可更改 |
| fileHeader | 在event中加上一个header,保存event所属文件的绝对路径 |
| batchSize | source每次写入到channel的events的批大小,也就是说source读取的events数量到达此值,才会写入到channel |
7. Netcat Source
- 在某个端口上监听,一般用于linux本机测试,telnet localhost port 逐行读取发送的信息
8. Kafka Source
- 可以把Kafka Source 视为 Kafka 的一个consumer ,读取Kafka 的topic的消息。
- 目前是支持 0.10 版本及以上的Kafka
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.batchSize = 5000
tier1.sources.source1.batchDurationMillis = 2000
tier1.sources.source1.kafka.bootstrap.servers = localhost:9092
tier1.sources.source1.kafka.topics = test1, test2
tier1.sources.source1.kafka.consumer.group.id = custom.g.id
Channel
1. Memory Channel
event保存在Java Heap中。如果允许数据小量丢失,推荐使用
2. Kafka Channel
event 保存在Kafka Topic中,可实现Channel HA
3. File Channel
event保存在本地文件中,可靠性高,但吞吐量低于Memory Channel
4. JDBC Channel
event保存在关系数据中,一般不推荐使用
Sink
主要分类 Logger、Kafka、HDFS、Avro、Custom Sink
| Logger Sink | |
| Kafka Sink | |
| HDFS Sink | |
| Avro Sink | |
| Custom Sink |
Interceptors
定义
- Flume Interceptor拦截器的作用在于能够在Event从Source传输到Channel过程中,修改或者删除Event的Header。多个拦截器Interceptor组成一个拦截器链,拦截器的执行顺序与配置顺序相同,上一个拦截器Interceptor处理后的Event List会传给下一个Interceptor
- 在Flume中自定义Interceptor时,需要实现org.apache.flume.interceptor.Interceptor接口,以及创建静态内部类去实现org.apache.flume.interceptor.Interceptor.Builder接口
分类及作用(常用的加黑)
| 名称 | 解释 |
|---|---|
| Timestamp Interceptor | 将时间戳插入到flume的event的header中 |
| Host Interceptor | 插入agent运行的机器的主机名或者ip地址 |
| Static Interceptor | 为所有的事件增加一个static的header |
| UUID Interceptor | 被拦截的所有事件上设置一个唯一的标识符 |
| Morphline Interceptor | morphline可以忽略某些events,或者通过基于正则表达式的模式匹配来改变或者插入某些event headers |
| Search and Replace Interceptor | 基于Java正则表达式,与Java Matcher.replaceAll()方法相同的规则 |
| Regex Filtering Interceptor | 筛选出与配置的正则表达式相匹配的事件。常用于数据清洗. |
| Regex Extractor Interceptor | 使用指定的正则表达式提取正则表达式匹配组 |
Channel Selector
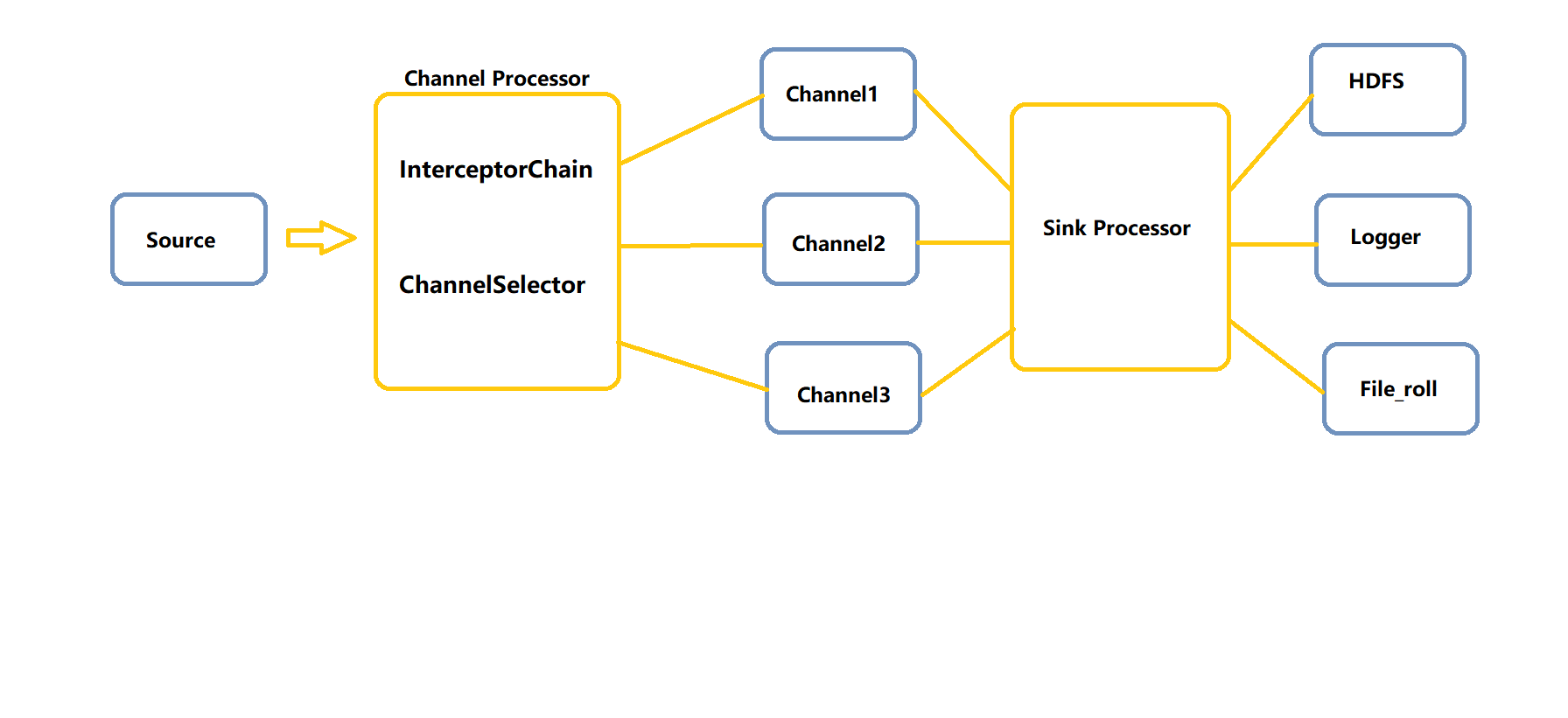
定义
- Channel Selector 简单理解就是Interceptor设置了一些header信息,Selector可以根据header来筛选,哪些发给Channel1 哪些发给Channel2。
分类
| 名称 | 解释 |
|---|---|
| Replicating | 其实就是单Channel, 没有选择 |
| Multiplexing | 有设置多个Channel, 每种设置不同或者相同的header |
| Custom | 自定义,二次开发 |
Sink Processor
定义
- 目的是为了实现高可用。假如一个Sink 挂了,Channel的信息无法发送,Channel很可能会崩坏。
- 使用Sink Processor 可以分配给多个sink, 一个挂掉并不影响整体的数据流。
分类
1. default: single sink
2. failover
维护一个优先级Sink组件列表,设置数量越大,优先级越高。
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2 k3
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5 #优先级值, 绝对值越大表示优先级越高
a1.sinkgroups.g1.processor.priority.k2 = 7
a1.sinkgroups.g1.processor.priority.k3 = 6
a1.sinkgroups.g1.processor.maxpenalty = 20000 #失败的Sink的最大回退期(millis)
3. load balance
-
负责将Channel暂存的Event均衡到对应的多个Sink组件上,而每个Sink组件分别连接到一个独立的Agent上.
-
负载均衡,包括round_robin(轮询)和random(随机) 两种。















 1153
1153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









