







 本文介绍了Flume在大数据日志分析中的作用,它适用于流处理和批处理。Flume由Source、Channel和Sink组成,用于高效收集、聚合和传输日志数据。Event是其传输的基本单位,具备事务性。文章还详细阐述了Flume的安装过程,包括JDK和Flume的下载、解压及环境变量配置。
本文介绍了Flume在大数据日志分析中的作用,它适用于流处理和批处理。Flume由Source、Channel和Sink组成,用于高效收集、聚合和传输日志数据。Event是其传输的基本单位,具备事务性。文章还详细阐述了Flume的安装过程,包括JDK和Flume的下载、解压及环境变量配置。
Flume架构介绍和安装
写在前面
在学习一门新的技术之前,我们得知道了解这个东西有什么用?我们可以使用它来做些什么呢?简单来说,flume是大数据日志分析中不能缺少的一个组件,既可以使用在流处理中,也可以使用在数据的批处理中。
1.流处理:
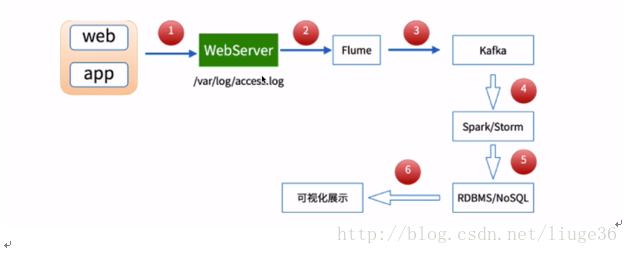
2.离线批处理:
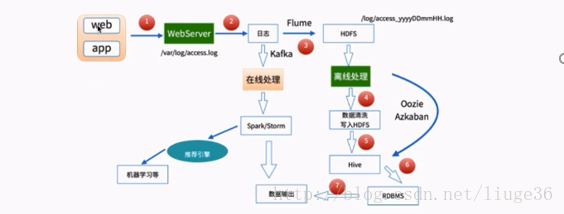
分析:不管你是数据的实时流处理,还是数据的离线批处理,都是会使用flume这个日志收集框架来做日志的收集。因此,学习这个这个组件是很重要的。这个组件的使用也是很简单的。
简单介绍一下Flume
Flume是一种分布式的、可靠的、可用的服务,用于高效地收集、聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调的可靠性机制和许多故障转移和恢复机制,具有健壮性和容错性。它使用一个简单的可扩展的数据模型,允许联机分析应用程序。
一句话总结:Flume就是用来做日志收集的这么一个工具
Flume架构介绍
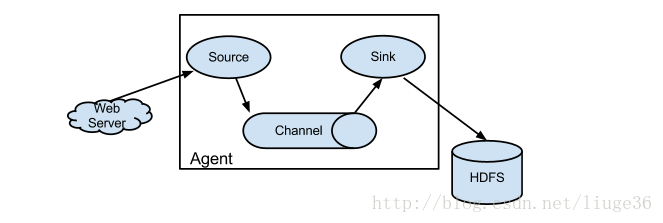
1) Source 收集 (从webserver读取数据到Channel中去)
2) Channel 聚集 (减少直接与磁盘的对接次数(生产环境中一般使用类型为Memory),当channel满了,再写到sink中去。同时,也起到了容错的作用,因为只有当sink接收到了数据,channel才会把原有的数据丢弃)
3) Sink 输出(从channel中读取数据,写到目的地,这里的目的地可以是HDFS、其余的一些文件系统或者作为下一个agent的source等)
顺便说一下
Event的概念
在整个数据的收集聚集传送的过程中,流动的是event,即事务保证是在ev
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









