







案例
官网例子 监听localhost机器的44444端口,接收到数据sink到logger终端
example.conf: A single-node Flume configuration
第一步:配置example.conf文件
(如果是本地windows写好再上传到服务器,一定要确认是否为unix格式。方法:vi example.conf : set ff? unix 就是对的)
我的是在flume 文件夹
## Name the components on this agent 配置各种名字
## 需求:监听localhost机器的44444端口,接收到数据sink到终端
a1.sources = r1
a1.sinks = k1
a1.channels = c1
## Describe/configure the source 配置source的基本属性
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
## Use a channel which buffers events in memory 配置channel的基本属性
a1.channels.c1.type = memory
## Describe the sink 配置sink的基本属性
a1.sinks.k1.type = logger
## Bind the source and sink to the channel 连线
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
执行:
(a1 配置文件中agent 名字)
bin/flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/config/example.conf \
-Dflume.root.logger=INFO,console
安装telnet
如果telnet 命令输入后
-bash: telnet: command not found
yum list telnet* 列出telnet相关的安装包
yum install -y telnet-server 安装telnet服务
yum install -y telnet.* 安装telnet客户端
终端测试
telnet localhost 44444
输入测试字符串(模拟日志信息) 例如1. 2. 3. 4.
[hadoop@hadoop001 config]$ telnet localhost 44444
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
1
OK
2
OK
3
OK
4
OK
sink 到终端输出
2021-07-23 08:47:37,745 (SinkRunner-PollingRunner-DefaultSinkProcessor)
[INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 31 0D 1. }
2021-07-23 08:47:38,766 (SinkRunner-PollingRunner-DefaultSinkProcessor)
[INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 32 0D 2. }
2021-07-23 08:47:39,456 (SinkRunner-PollingRunner-DefaultSinkProcessor)
[INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 33 0D 3. }
2021-07-23 08:47:40,286 (SinkRunner-PollingRunner-DefaultSinkProcessor)
[INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 34 0D 4. }
example2 监控一个文件 ==> HDFS
架构选型:exec->memory->hdfs
exec source tail -F
memory channel
hdfs sink
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/log/flume/hdfs/test.log
a1.sources.r1.channels = c1
# channel
a1.channels.c1.type = memory
#sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://hadoop001:9000/flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.fileType = DataStream
#define agent
exec-hdfs-agent.sources = exec-source
exec-hdfs-agent.channels = exec-memory-channel
exec-hdfs-agent.sinks = hdfs-sink
#define source
exec-hdfs-agent.sources.exec-source.type = exec
exec-hdfs-agent.sources.exec-source.command = tail -F ~/data/data.log
exec-hdfs-agent.sources.exec-source.shell = /bin/sh -c
#define channel
exec-hdfs-agent.channels.exec-memory-channel.type = memory
#define sink
exec-hdfs-agent.sinks.hdfs-sink.type = hdfs
exec-hdfs-agent.sinks.hdfs-sink.hdfs.path = hdfs://hadoop001:9000/flume/tail
# 肉眼可查看的文件类型,默认sequence是无法直接查看文件内容的
exec-hdfs-agent.sinks.hdfs-sink.hdfs.fileType = DataStream
exec-hdfs-agent.sinks.hdfs-sink.hdfs.writeFormat = Text
exec-hdfs-agent.sinks.hdfs-sink.hdfs.batchSize = 10
#bind source and sink to channel
exec-hdfs-agent.sources.exec-source.channels = exec-memory-channel
exec-hdfs-agent.sinks.hdfs-sink.channel = exec-memory-channel
启动
flume-ng agent \
--name exec-hdfs-agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/config/flume-exec-hdfs.conf \
-Dflume.root.logger=INFO,console
造数据
for i in {1..100}; do echo "cnblue $i" >> /home/hadoop/data/data.log;sleep 0.1;done
结果
hadoop001:50070 的web 页面查看该路径下是否有文件生成。
**问题:**sink到HDFS中文件的命名问题:FlumeData.1612619941165.tmp 把后缀去掉
小文件问题
可靠性问题
example3 监控一个文件夹 ==> HDFS (常用)
架构选型:
Spooling Directory source
memory channel
hdfs sink
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /home/hadoop/log/flume/hdfs
# channel
a1.channels.c1.type = memory
#sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://hadoop001:9000/flume/directory/hdfs
a1.sinks.k1.hdfs.fileType = DataStream
执行:
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/config/spooling-memory-logger.conf \
-Dflume.root.logger=INFO,console
-
注意:
-
最好读写的目录不是同一个(生产商)。正确做法是先把log存到一个目录下,等完成后,再cp/mv到spool路径下。
-
如果文件重命名,也会报错
[ERROR - org.apache.flume.source.SpoolDirectorySource$SpoolDirectoryRunnable.run(SpoolDirectorySource.java:280)] FATAL: Spool Directory source r1: { spoolDir: /home/hadoop/log/flume/directory }: Uncaught exception in SpoolDirectorySource thread. Restart or reconfigure Flume to continue processing.
java.lang.IllegalStateException: File name has been re-used with different files. Spooling assumptions violated for /home/hadoop/log/flume/directory/data.log.COMPLETED -
一旦错误后,无法再正常工作,必须重启
-
被监控的文件夹中的文件有.completed 表示已经处理完成
复杂些的hdfs sink配置 - 解决小文件问题+时间戳文件夹命名(工作常用)
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /home/hadoop/log/flume/directory
# channel
a1.channels.c1.type = memory
#sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://hadoop001:9000/flume/directory/hdfs/events/%y%m%d%H%M
#roll
a1.sinks.k1.hdfs.rollInterval = 50
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 100000000
#timestamp
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
执行
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/config/hdfs-timestamp-spooling.conf \
-Dflume.root.logger=INFO,console
for i in {1..10000}; do echo "cnblue $i" >> /home/hadoop/log/flume/directory/data.log;sleep 0.1;done
日志:
2021-07-25 21:35:44,750 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSCompressedDataStream.configure(HDFSCompressedDataStream.java:64)] Serializer = TEXT, UseRawLocalFileSystem = false
2021-07-25 21:35:44,762 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:246)] Creating hdfs://hadoop001:9000/flume/directory/hdfs/events/2107252135/FlumeData.1627220144750.gz.tmp
2021-07-25 21:35:44,927 (pool-5-thread-1) [WARN - org.apache.flume.source.SpoolDirectorySource$SpoolDirectoryRunnable.run(SpoolDirectorySource.java:261)] The channel is full, and cannot write data now. The source will try again after 250 milliseconds
2021-07-25 21:35:45,178 (pool-5-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents(ReliableSpoolingFileEventReader.java:305)] Last read was never committed - resetting mark position.
2021-07-25 21:35:45,701 (hdfs-k1-call-runner-0) [INFO - org.apache.hadoop.io.compress.CodecPool.getCompressor(CodecPool.java:153)] Got brand-new compressor [.gz]
2021-07-25 21:35:46,474 (pool-5-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents(ReliableSpoolingFileEventReader.java:324)] Last read took us just up to a file boundary. Rolling to the next file, if there is one.
2021-07-25 21:35:46,474 (pool-5-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile(ReliableSpoolingFileEventReader.java:433)] Preparing to move file /home/hadoop/log/flume/directory/data.log to /home/hadoop/log/flume/directory/data.log.COMPLETED
2021-07-25 21:36:35,707 (hdfs-k1-roll-timer-0) [INFO - org.apache.flume.sink.hdfs.HDFSEventSink$1.run(HDFSEventSink.java:380)] Writer callback called.
2021-07-25 21:36:35,708 (hdfs-k1-roll-timer-0) [INFO - org.apache.flume.sink.hdfs.BucketWriter.doClose(BucketWriter.java:438)] Closing hdfs://hadoop001:9000/flume/directory/hdfs/events/2107252135/FlumeData.1627220144750.gz.tmp
2021-07-25 21:36:35,722 (hdfs-k1-call-runner-2) [INFO - org.apache.flume.sink.hdfs.BucketWriter$7.call(BucketWriter.java:681)] Renaming hdfs://hadoop001:9000/flume/directory/hdfs/events/2107252135/FlumeData.1627220144750.gz.tmp to hdfs://hadoop001:9000/flume/directory/hdfs/events/2107252135/FlumeData.1627220144750.gz
example4 多个AvroSink->一个AvroSource(设置Interceptor和Channel Selectors)
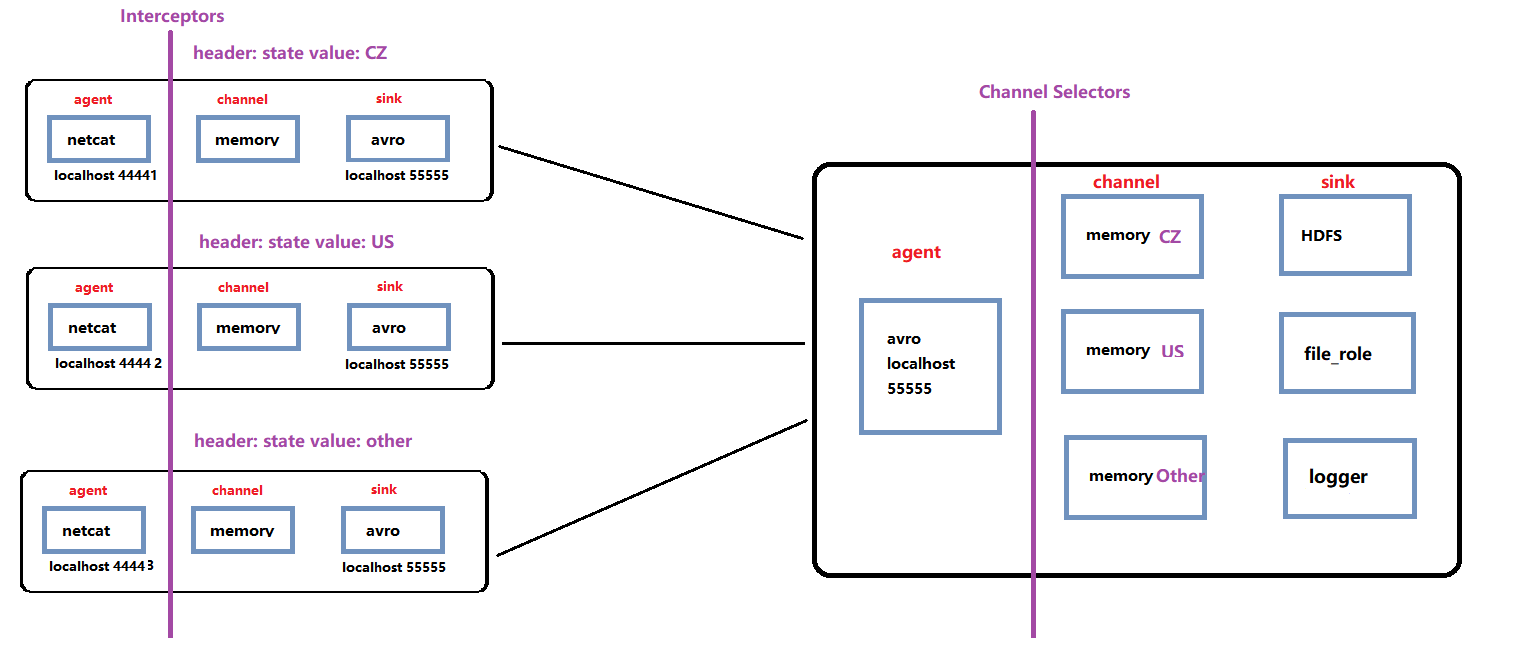
-
上游的三个avro Sink
(1) avroSink1.conf
agent1.sources = r1 agent1.channels = c1 agent1.sinks = k1 # define source agent1.sources.r1.type = netcat agent1.sources.r1.bind = 0.0.0.0 agent1.sources.r1.port = 44441 agent1.sources.r1.interceptors = i1 agent1.sources.r1.interceptors.i1.type = static agent1.sources.r1.interceptors.i1.key = state agent1.sources.r1.interceptors.i1.value = CZ #define channel agent1.channels.c1.type = memory # define sink agent1.sinks.k1.type = avro agent1.sinks.k1.hostname = 0.0.0.0 agent1.sinks.k1.port = 55555 # build agent1.sources.r1.channels = c1 agent1.sinks.k1.channel = c1(2) avroSink2.conf
agent2.sources = r1 agent2.channels = c1 agent2.sinks = k1 # define source agent2.sources.r1.type = netcat agent2.sources.r1.bind = 0.0.0.0 agent2.sources.r1.port = 44442 agent2.sources.r1.interceptors = i1 agent2.sources.r1.interceptors.i1.type = static agent2.sources.r1.interceptors.i1.key = state agent2.sources.r1.interceptors.i1.value = US #define channel agent2.channels.c1.type = memory # define sink agent2.sinks.k1.type = avro agent2.sinks.k1.hostname = 0.0.0.0 agent2.sinks.k1.port = 55555 # build agent2.sources.r1.channels = c1 agent2.sinks.k1.channel = c1(3) avroSink3.conf
agent3.sources = r1 agent3.channels = c1 agent3.sinks = k1 # define source agent3.sources.r1.type = netcat agent3.sources.r1.bind = 0.0.0.0 agent3.sources.r1.port = 44443 agent3.sources.r1.interceptors = i1 agent3.sources.r1.interceptors.i1.type = static agent3.sources.r1.interceptors.i1.key = state agent3.sources.r1.interceptors.i1.value = default #define channel agent3.channels.c1.type = memory # define sink agent3.sinks.k1.type = avro agent3.sinks.k1.hostname = 0.0.0.0 agent3.sinks.k1.port = 55555 # build agent3.sources.r1.channels = c1 agent3.sinks.k1.channel = c1 -
下游的avro Source
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 k3 a1.channels = c1 c2 c3 #Avro Source a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 55555 #multi Channel Selectors a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = state a1.sources.r1.selector.mapping.CZ = c1 a1.sources.r1.selector.mapping.US = c2 a1.sources.r1.selector.default = c3 # Use a channel1 which buffers events in memory a1.channels.c1.type = memory # Use a channel which buffers events in memory a1.channels.c2.type = memory # Use a channel which buffers events in memory a1.channels.c3.type = memory #define the sink 1 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://hadoop001:9000/flume/directory/hdfs/events/%y%m%d #roll a1.sinks.k1.hdfs.rollInterval = 50 a1.sinks.k1.hdfs.rollSize = 0 a1.sinks.k1.hdfs.rollCount = 100000000 #timestamp a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute #define the sink 2 a1.sinks.k2.type = file_roll a1.sinks.k2.sink.directory = /home/hadoop/log/flume/channel1 #define the sink 3 a1.sinks.k3.type = logger # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 c3 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2 a1.sinks.k3.channel = c3 -
启动
先启动下游的,再启动上游的,否则会报错
flume-ng agent \ --name a1 \ --conf-file $FLUME_HOME/config/multiSource.conf \ -Dflume.root.logger=INFO,console flume-ng agent \ --name agent1 \ --conf-file $FLUME_HOME/config/avroSink1.conf \ -Dflume.root.logger=INFO,console flume-ng agent \ --name agent2 \ --conf-file $FLUME_HOME/config/avroSink2.conf \ -Dflume.root.logger=INFO,console flume-ng agent \ --name agent3 \ --conf-file $FLUME_HOME/config/avroSink3.conf \ -Dflume.root.logger=INFO,console
程序 -> log4j -> Flume avro source -> 其他地方
MockDataApp.java
import org.apache.log4j.Logger;
public class MockDataApp {
private static Logger logger = Logger.getLogger(MockDataApp.class);
public static void main(String[] args) throws InterruptedException {
int index = 0;
while(true){
Thread.sleep(1000);
logger.info("当前输出值为" + index++);
}
}
}
log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = %d{HH:mm:ss,SSS} [%t] [%c] [%p] - %m\r\n
pom.xml
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-node</artifactId>
<version>1.8.0</version>
<!--version>1.6.0-cdh5.16.2</version-->
</dependency>
16:30:16,870 [main] [MockDataApp] [INFO] - 当前输出值为0
16:30:17,872 [main] [MockDataApp] [INFO] - 当前输出值为1
16:30:18,873 [main] [MockDataApp] [INFO] - 当前输出值为2
16:30:19,874 [main] [MockDataApp] [INFO] - 当前输出值为3
配置flume的log4j.appender
#...
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = hadoop001
log4j.appender.flume.Port = 44444
log4j.appender.flume.UnsafeMode = true
# configure a class's logger to output to the flume appender
log4j.logger.org.example.MyClass = DEBUG,flume
会报javaClassNotFound exception,添加依赖
<dependency>
<groupId>org.apache.flume.flume-ng-clients</groupId>
<artifactId>flume-ng-log4jappender</artifactId>
<version>1.8.0</version>
</dependency>
第一种:输出到logger上
conf文件
agent1.sources = avro-source
agent1.channels = logger-channel
agent1.sinks = log-sink
# define channel
agent1.channels.logger-channel.type = memory
# define source
agent1.sources.avro-source.channels = logger-channel
agent1.sources.avro-source.type = avro
agent1.sources.avro-source.bind = 0.0.0.0
agent1.sources.avro-source.port = 44444
# define sink
agent1.sinks.log-sink.channel = logger-channel
agent1.sinks.log-sink.type = logger
启动
flume-ng agent \
--name agent1 \
--conf-file $FLUME_HOME/config/flume-code.conf \
-Dflume.root.logger=INFO,console
终端输出
21/08/15 16:49:57 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1629017395701, flume.client.log4j.address=ip, flume.client.log4j.logger.name=MockDataApp, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: E5 BD 93 E5 89 8D E8 BE 93 E5 87 BA E5 80 BC E4 ................ }
21/08/15 16:49:58 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1629017396932, flume.client.log4j.address=ip, flume.client.log4j.logger.name=MockDataApp, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: E5 BD 93 E5 89 8D E8 BE 93 E5 87 BA E5 80 BC E4 ................ }
21/08/15 16:49:59 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1629017398089, flume.client.log4j.address=ip, flume.client.log4j.logger.name=MockDataApp, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: E5 BD 93 E5 89 8D E8 BE 93 E5 87 BA E5 80 BC E4 ................ }
21/08/15 16:50:00 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1629017399180, flume.client.log4j.address=ip, flume.client.log4j.logger.name=MockDataApp, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: E5 BD 93 E5 89 8D E8 BE 93 E5 87 BA E5 80 BC E4 ................ }
21/08/15 16:50:02 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1629017400279, flume.client.log4j.address=ip, flume.client.log4j.logger.name=MockDataApp, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: E5 BD 93 E5 89 8D E8 BE 93 E5 87 BA E5 80 BC E4 ................ }
21/08/15 16:50:03 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1629017401457, flume.client.log4j.address=ip, flume.client.log4j.logger.name=MockDataApp, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: E5 BD 93 E5 89 8D E8 BE 93 E5 87 BA E5 80 BC E4 ................ }
21/08/15 16:50:04 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1629017402575, flume.client.log4j.address=ip, flume.client.log4j.logger.name=MockDataApp, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: E5 BD 93 E5 89 8D E8 BE 93 E5 87 BA E5 80 BC E4 ................ }
21/08/15 16:50:05 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1629017403660, flume.client.log4j.address=ip, flume.client.log4j.logger.name=MockDataApp, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: E5 BD 93 E5 89 8D E8 BE 93 E5 87 BA E5 80 BC E4 ................ }
第二种:输出到hdfs上
conf
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#Avro Source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44440
# Use a channel1 which buffers events in memory
a1.channels.c1.type = memory
#define the sink 1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop001:9000/flume/directory/hdfs/events/%y%m%d%H%M%S
a1.sinks.k1.hdfs.filePrefix = ruozedata
a1.sinks.k1.hdfs.writeFormat = Text
#roll
a1.sinks.k1.hdfs.rollInterval = 50
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 100000000
#timestamp
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动
flume-ng agent \
--name a1 \
--conf-file $FLUME_HOME/config/log4j-hdfs.conf \
-Dflume.root.logger=INFO,console
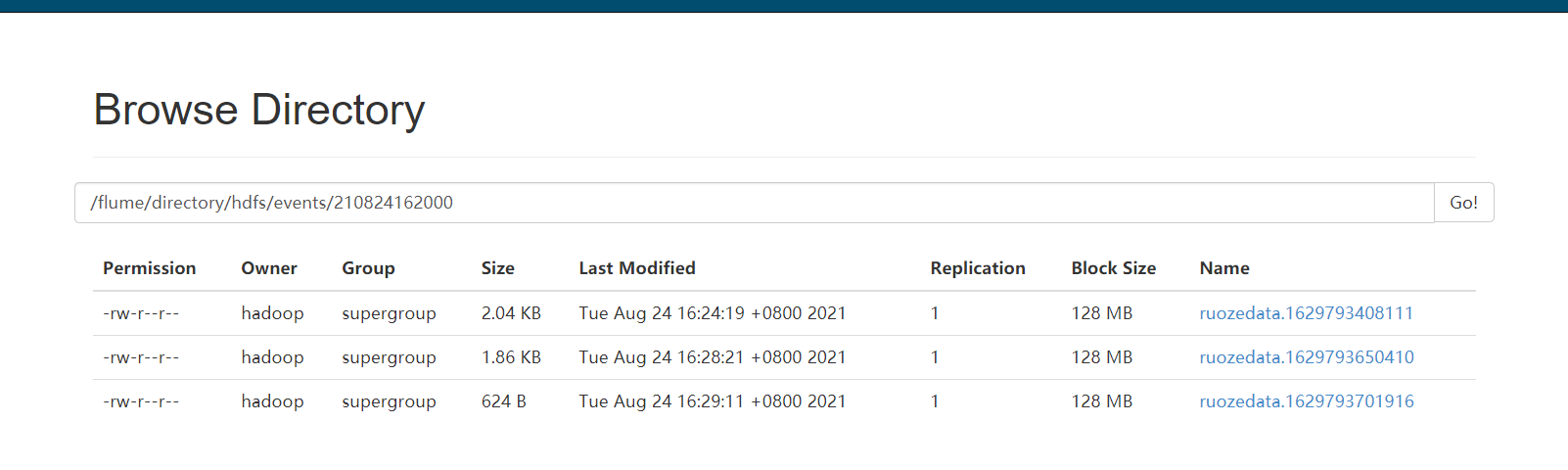
HDFS















 1668
1668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









