






摘要:
基于学习的单图像超分辨率(SISR)方法不断显示出优于传统的基于模型的方法的有效性和效率,这主要归功于端到端训练。但是,与基于模型的方法在统一的MAP (maximum a posteriori)框架下处理不同尺度因子、模糊内核和噪声水平的SISR问题不同,基于学习的方法通常缺乏这种灵活性。为了解决这一问题,本文提出了一种端到端可训练展开网络,它利用了基于学习的方法和基于模型的方法。具体来说,通过半二次分裂算法展开映射推理,可以得到由交替求解一个数据子问题和一个先验子问题组成的固定迭代次数。这两个子问题可以用神经模块来解决,从而形成一个端到端可训练的迭代网络。因此,该网络继承了基于模型的方法的灵活性,可以通过单一模型对不同尺度因子的模糊、噪声图像进行超分辨,同时保持了基于学习的方法的优点。大量的实验证明了所提出的深度展开网络在灵活性、有效性和可推广性方面的优越性。
1.引言
对于s的尺度因子,传统的SISR退化模型,假设LR图像y是一个模糊的、抽取的、有噪声的HR图像x。
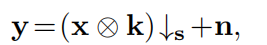
其中⊗表示二维卷积(x)与模糊k内核,↓s为标准s形向下采样器,即,保留每个不同的s×s patch的左上像素,并丢弃其他的,和n通常假定为添加的,高斯白噪声(AWGN)指定的标准偏差(或噪声)σ。式(1)通过对底层HR图像设置适当的模糊核、尺度因子和噪声,可以逼近各种LR图像,物理意义明确。特别是,Eq.(1)已经在基于模型的方法中得到了广泛的研究,这种方法解决了MAP框架下数据项和先验项的组合。
虽然基于模型的方法通常可以通过算法解释,但它们通常缺乏评估的标准标准,因为除了规模因素外,式(1)还包含了一个模糊核和添加的噪声。为了方便,研究人员采用了双三次退化,而没有考虑模糊核和噪声水平,然而,双三次退化在数学上是复杂的,这反过来又阻碍了基于模型的方法的发展。出于这个原因,最近提出SISR解决方案主要是基于学习的方法,学习从一个双三次下采样的LR图像到其HR估计的映射函数。事实上,在改善双三次退化的PSNR和感知质量方面,已经通过基于学习的方法取得了显著进展,其中基于卷积神经网络的方法由于其强大的学习能力和并行计算的速度,是最受欢迎的方法。然而,利用CNNs通过单一模型来处理Eq.(1)的工作却很少。与基于模型的方法不同,CNNs通常缺乏通过单一端到端训练模型对不同尺度因子的模糊、噪声LR图像进行超分辨的灵活性。在本文中,我们提出了一种深度展开超分辨率网络(USRNet)来弥补基于学习的方法和基于模型的方法之间的差距。
一方面,与基于模型的方法类似,USRNet可以有效地处理经典的退化模型(即,式(1)))通过单一模型,具有不同的模糊核、尺度因子和噪声水平。
另一方面,与基于学习的方法类似,USRNet可以以端到端的方式进行培训,以保证有效性和效率。
为了实现这一点,我们首先展开基于模型的能量函数通过半二次分裂算法。相应地,我们可以得到一个推理,它迭代地交替解决两个子问题,一个与数据项有关,另一个与前一个项有关。然后,我们将推理作为一个深层网络,用神经模块替换这两个子问题的解。由于这两个子问题分别对应于执行退化一致性知识和保证去噪器先验知识,所以USRNet对于显式退化和先验约束是很有原则的,这是与现有的基于学习的SISR方法的显著优势。值得注意的是,由于USRNet涉及到每个子问题的超参数,因此网络包含一个额外的模块用于生成超参数。此外,为了减少参数的数量,所有之前的模块共享相同的架构和相同的参数。
这项工作的主要贡献如下:
- 提出了一种端到端可训练展开超分辨率网络(USRNet)。USRNet是第一个尝试处理经典退化模型与不同的尺度因子,模糊内核和噪声水平通过一个单一的端到端训练模型。
- USRNet融合了基于模型方法的灵活性和基于学习方法的优点,为弥合基于模型方法和基于学习方法之间的鸿沟提供了途径。
- USRNet本质上强加了一个退化约束(即估计的HR图像应符合退化过程)和一个先验约束(即,估计的HR图像应该具有自然特征)上的解决方案。
2.相关工作
2.1 退化模型
退化模型的知识对于SISR的成功至关重要,因为它定义了如何从HR图像退化LR图像。除了经典退化模型和双三次退化模型外,在SISR文献中还提出了其他几种退化模型。在一些早期的工作中,退化模型假设LR图像直接从HR图像上向下采样而不产生模糊,这与图像插值问题相对应。在中,进一步假设双柔下采样的图像被高斯噪声或JPEG压缩噪声所破坏。在[15,42]中,退化模型主要关注高斯模糊和随后的带尺度因子3的下采样。注意,与Eq.(1)不同的是,对于每个不同的3×3 patch,它们的下采样保持的是中心像素,而不是左上角像素。在中,退化模型假设LR图像是模糊的、双柔下采样的HR图像高斯噪声。通过假设双柔下采样的干净HR图像也是干净的,[68]将退化模型视为LR图像和上的去模糊合成、双三次降解的SISR。虽然已经提出了许多退化模型,基于cnn的SISR用于经典退化模型的研究较少,值得深入研究
2.2 灵活SISR方法
尽管基于cnn应用于处理其他更实用的降解模型并非易事。为了实用,最好设计一个灵活的超级分解器,它需要三个关键因素:,尺度因子,模糊核和噪声水平。已经提出了几种通过单一模型处理具有不同尺度因子的双三次退化的方法,例如逐步向上采样的LapSR [30],MDSR[36]具有特定规模的分支,Meta-SR[23]具有超高档模块。灵活处理模糊问题LR图像,[44,67]中提出的方法以PCA降维模糊核作为输入。然而,这些方法仅限于高斯模糊核。最灵活的基于cnn的工作,可以处理各种模糊内核,规模因素和噪音水平,是深入即插即用的方法[65,68]。这种方法的主要思想是将学习到的CNN先验插入MAP框架下的迭代解中。不幸的是,这些本质上是基于模型的方法,计算量大,涉及手动选择超参数。如何设计一个端到端可训练模型,以实现更好的结果与更少的迭代仍然没有研究。虽然基于学习的盲图像恢复最近受到了相当大的关注[12,39,43,50,62],但我们注意到这项工作主要关注非盲SISR,假定LR图像、模糊核和噪声水平是已知的。事实上,非盲SISR仍是一个活跃的研究方向。
首先,模糊核和噪声水平可以估计,或根据其他信息(如相机设置)知道。
其次,用户可以通过调节模糊内核和噪声级别来控制锐度和平滑度的优先级。
第三,非盲SISR可以是一个中间步骤.
2.3。深展开图像复原
除了深入的即插即用方法(参见,例如,[7,10, 22, 57]),深度展开方法也可以将基于模型的方法与基于学习的方法相结合。它们的主要区别是,后者通过在大型训练集上最小化损失函数,以端到端方式优化参数,从而通常在迭代次数较少的情况下产生更好的结果。早期的深度展开方法可以追溯到[4,48,54],其中提出了一种基于梯度下降算法的压缩地图推理来进行图像去噪。从那时起,一系列深度展开方法基于特定的优化算法(如half-quadratic分裂[2],乘数的交替方向方法[6]和非[1,9])提出了解决不同的图像修复任务,如图像去噪(11日32),图像去模糊(29岁,49),图像压缩传感(61、63)和图像demosaicking [28]。
与基于纯学习的方法相比,深度展开方法具有可解释性,可以将退化约束融合到学习模型中。但是,它们中的大多数都存在以下一种或几种缺陷。
(i)不使用深度求先验子问题的解CNN的功能还不够强大。
(ii)数据子问题没有以封闭形式解出,可能会阻碍收敛。
(iii)整个推理是通过分阶段和微调的方式进行训练的,而不是完整的端到端方式。此外,考虑到经典退化模型不存在深度展开SISR方法,提出克服上述问题的方法具有特别的意义。
3.方法
3.1 退化模型:经典vs.双三次
由于双三次降解已经得到了很好的研究,因此研究其与经典降解模型的关系是很有趣的。实际上,可以通过在式(1)中设置合适的模糊核来近似双三次退化。为了实现这一点,我们采用数据驱动的方法,通过在一个较大的HR/ bicubicr - lr对{(x, y)}上最小化重构误差来解决下面的核估计问题。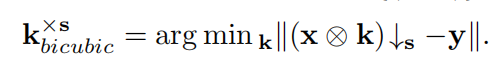
图2显示了比例因子2、3和4的近似双三次核。需要注意的是,由于downsamlping操作为每个不同的s×s patch选择左上角像素,因此比例因子2、3和4的双三次核分别向左上角偏移0.5、1和1.5像素。
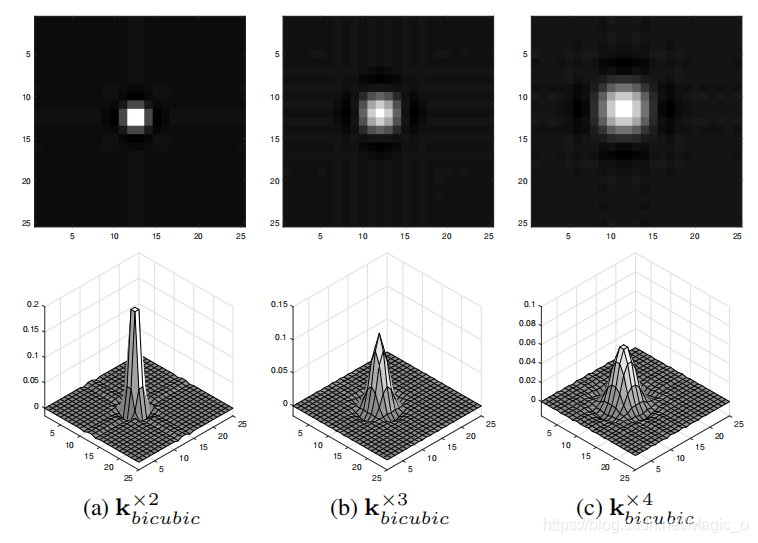
图2。比例因子2、3、4和的近似双三次在经典SISR退化模型假设下。注意,这些内核包含负值。
3.2。展开优化
根据MAP框架,可以通过最小化后续的能量函数来估计HR图像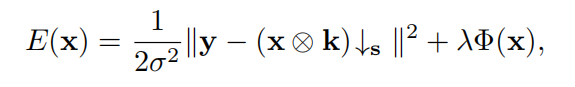
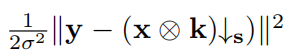 是数据项,Φ(x)是前一项,λ是一个权衡参数。为了得到Eq.(3)的展开推理,我们选择了半二次分裂(HQS)算法,因为它在很多应用中简单且收敛速度快。qs通过引入一个辅助变量z来处理Eq.(3),得到如下近似等价
是数据项,Φ(x)是前一项,λ是一个权衡参数。为了得到Eq.(3)的展开推理,我们选择了半二次分裂(HQS)算法,因为它在很多应用中简单且收敛速度快。qs通过引入一个辅助变量z来处理Eq.(3),得到如下近似等价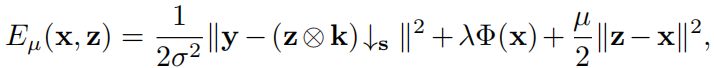 µ惩罚参数的地方。这种问题可以通过迭代求解x和z的子问题来解决,
µ惩罚参数的地方。这种问题可以通过迭代求解x和z的子问题来解决,
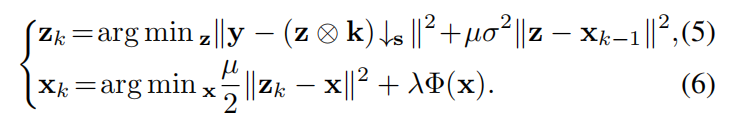
根据情商。(5),µ应该足够大,这样x和z约等于不动点。然而,这也会导致缓慢的收敛。因此,一个好的经验法则是迭代式µ增加。为了方便起见,在kµ迭代用µk。可以看出,数据项和先验项分别解耦为Eq.(5)和Eq.(6)。对于Eq.(5)的求解,假设在圆形边界条件下进行卷积,可以利用快速傅里叶变换(FFT)。值得注意的是,它有一个封闭的表达式[71]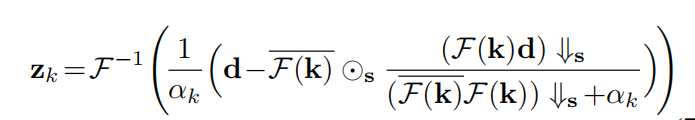
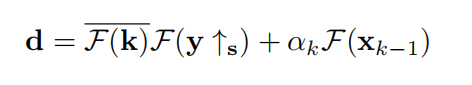

3.3 深入展开网络
一旦确定展开优化,下一步就是设计展开超分辨率网络
(USRNet)。因为展开优化主要包括迭代求解一个数据子问题(即,式(5))和一个先验子问题(即,则USRNet应该在数据模块D和之前的模块P之间进行切换。此外,子问题的解决方案也把hyper-parametersαkβk作为输入,分别进一步引入USRNet hyper-parameter模块H。图3展示了带有K个迭代的USRNet的总体架构,其中K被经验地设置为8,以权衡速度-准确性。接下来,关于D、P和的更多细节
H。
5.结论
本文以经典的SISR退化模型为研究对象,提出了一种深度展开超分辨率网络。受传统基于模型方法展开优化的启发,我们设计了一个端到端可训练的深度网络,该网络融合了基于模型方法的灵活性和基于学习方法的优点。该网络的主要新颖之处在于它可以通过一个单一的模型来处理经典的退化模型。具体来说,该网络由三个可解释模块组成,包括使人力资源估算更清晰的数据模块、使人力资源估算更清晰的先验模块和控制其他两个模块输出的超参数模块。结果表明,该方法既能对解施加退化约束,又能对解施加先验约束。大量的实验结果证明了该方法对各种退化LR图像的超分辨的灵活性、有效性和通用性。














 76
76











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









