






无核显CPU + P40 + N卡亮机卡 windows 10 配置 实现 P40 炼丹与游戏
用了此方法成功双卡(cpu1700x + gtx 1080+p40)正常运行
(注: 这两天我的gtx 1080 挂了,买了块亮机卡nvidia 750ti 按照该方法+部分修改(下面标注部分修改的地方)
(新增注电脑上跑的时候有可能会有这种情况代码里指定的gpu id 和实际使用的gpu id 是相反的,比如nvidia-smi是p40 是卡1,但是你跑代码的时候指定为卡0就可以用p40 了)
鲁大师显卡模块的跑分:由750ti 单独跑9w左右 提升到 使用P40 计算750ti 输出的 37w左右)
操作步骤
Step1
安装最新显卡驱动,点下一步安装前将驱动程序解压的文件夹(一般在系统盘NVIDIA文件夹中),拷贝到桌面。
Step2
正常安装完驱动后,在设备管理器中有一个显示视频器,右键更新驱动程序,选择从本机找驱动程序,浏览到桌面拷贝的文件夹中/international/Display.Driver,手动安装(让我从计算机上。。。这个选项,别点下一步),选择Tesla T4的驱动
提示框选是,等待安装完成
Step3
打开注册表(win+R --> regedit),找到“HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Class{4d36e968-e325-11ce-bfc1-08002be10318}”
0000开始就是这些显卡的下标,你的Tesla具体是具体是哪个卡,看右侧“DriverDesc”字段确定。
“AdapterType”,dword值,改为1
新建一个键:“GridLicensedFeatures”,dword值,改为 7。(这一步是通过注册表强制打开Grid驱动支持,即打开GPUZ中所有显卡功能)
这里是部分修改的: tesla 卡这边修改:FeatureScore, 值从cf修改为d1 (十六进制,hex)
tesla 卡这边修改: 新增或者修改 EnableMsHybrid, 类型为DWORD(32bit) ,值为 1
输出卡下面(比如我的是输出卡 项 Driver Desc 描述的是 750ti):新增或者修改 EnableMsHybrid, 类型为DWORD(32bit) ,值为 2
Step4
在设备管理器中禁用T4再启用
Step5
重启电脑
安装完成后,运行nvidia-smi 如下所示
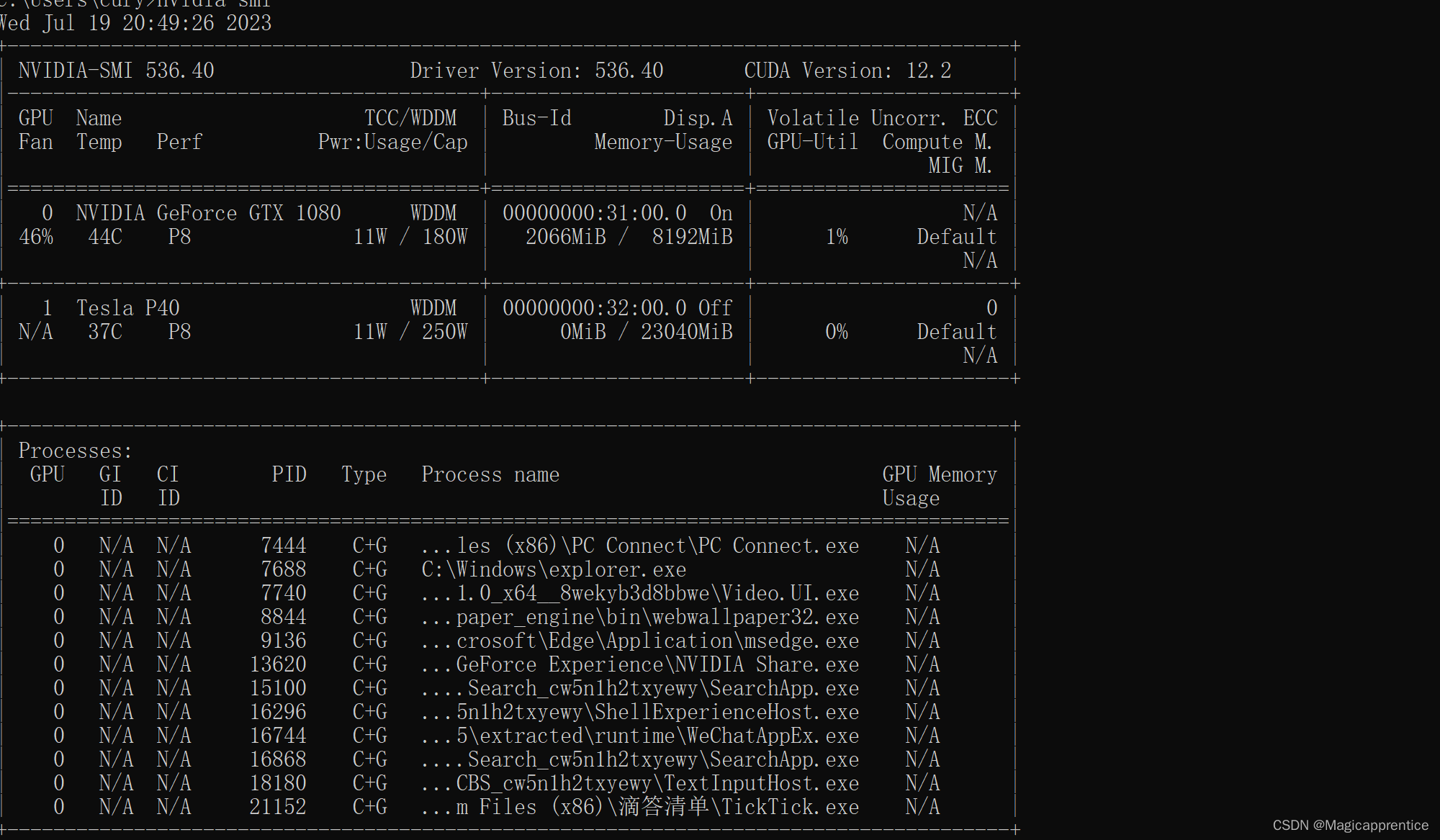
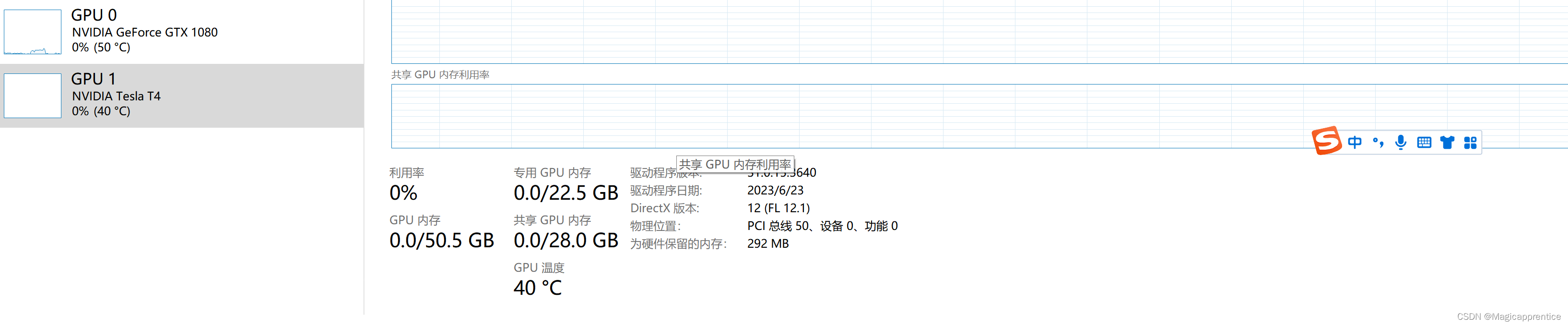
Step 6
可以在windows 10桌面 --> 右键 -->显示设置 --> 图形设置 --> 中 为指定的游戏 选择指定显卡
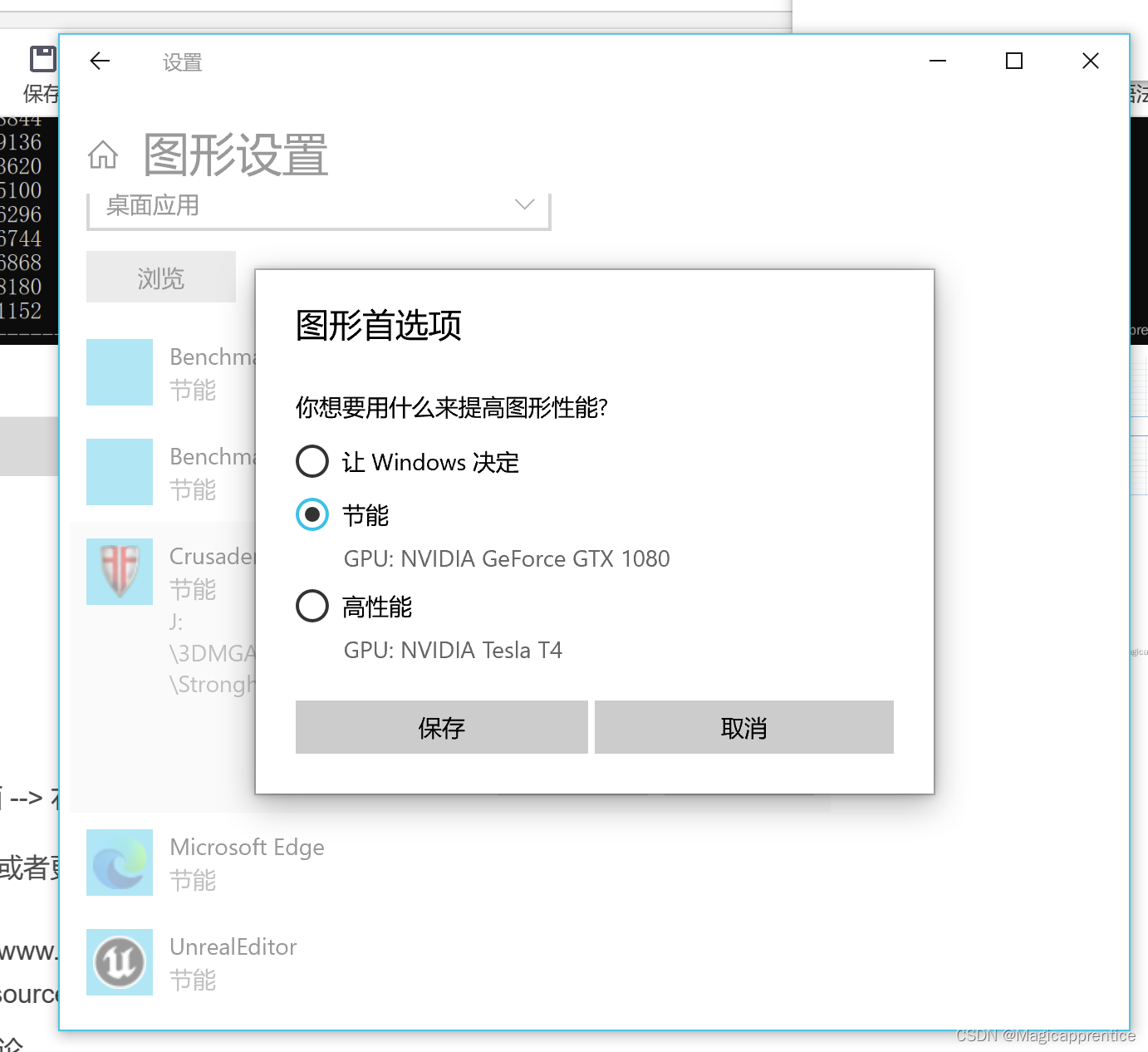
部分图例
单独使用750ti 的鲁大师显卡评分
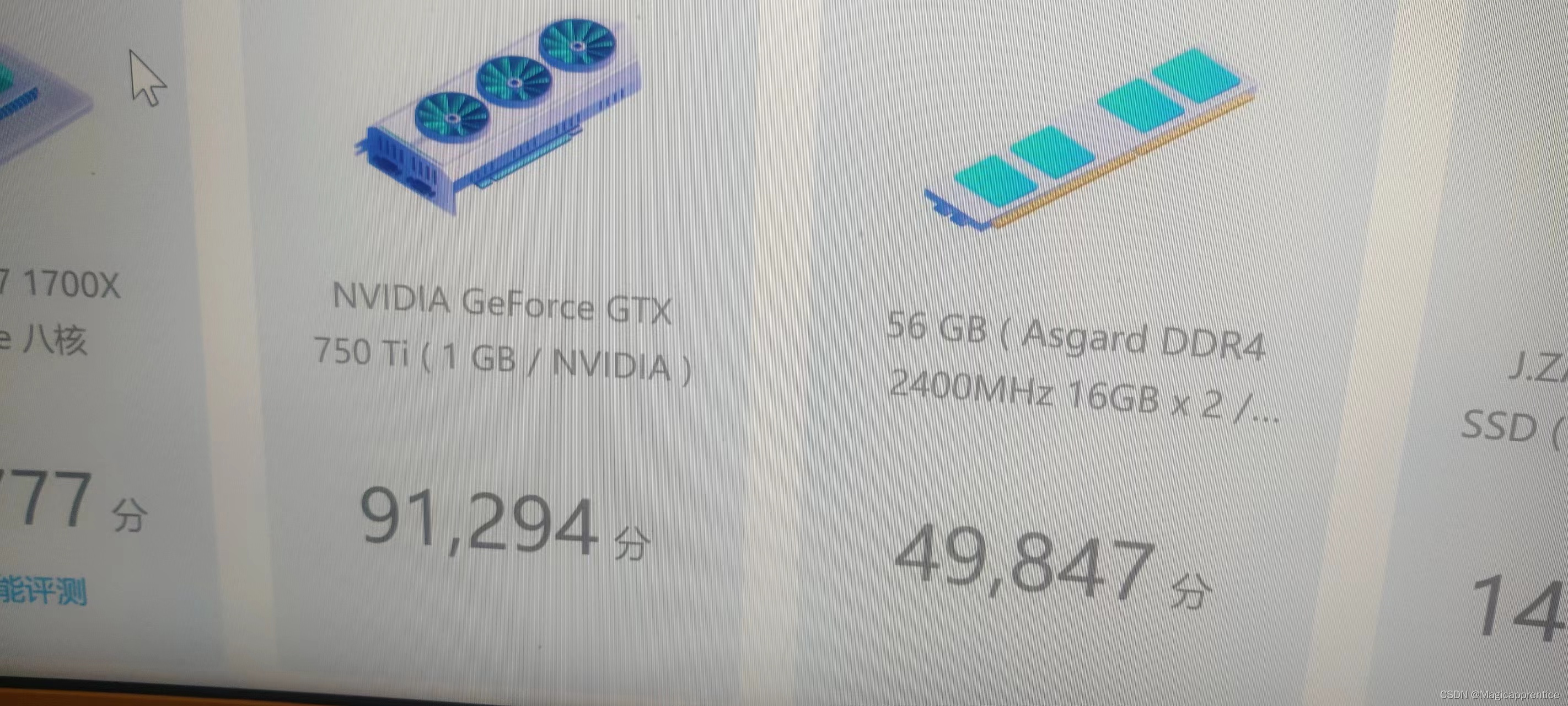
使用p40计算 gtx 750ti 输出的鲁大师显卡评分

备注
备注:若后续更新驱动或者更新windows 10 之后导致P40显卡掉了,可以按照上述步骤从步骤2开始再来一遍即可。
参考链接
- 参考链接:https://www.bilibili.com/video/BV13W4y1s7so/
- 上述视频对应的评论
- 新增修改部分参考链接: https://www.bilibili.com/video/BV1tY411D74p/

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









