







1.项目自述
针对职业技能教育的网络课堂系统,提供相关课程。项目基于B2B2C的业务模式,培训机构可以在平台入驻、发布课程,运营方人员对发布的课程进行审核,课程包括免费和收费两种形式,对于免费课程普通用户可以直接选课学习,对于收费课程在选课后需要支付成功才可以继续学习。
采用前后端分离架构,后端采用SpringBoot、SpringCloud技术栈开发,数据库使用了MySQL,还使用的Redis、rabbitMQ、minIO、Elasticsearch等中间件系统。
2.核心模块
base模块:定义分页,全局异常处理
课程管理模块:主要负责课程、教师、机构相关增删改查,课程审核、发布
系统模块:数据字典
媒资管理模块:上传照片、上传视频、处理视频、审核媒资、绑定媒资,minIO分布式文件系统
网关:知道每个微服务实例的地址,nacos作为注册中心和配置中心
订单:负责订单管理
学习:选课,支付等
3.数据库
(1)xcplus_course
course_base(课程基础信息表):
课程信息表。id,机构公司id,大分类小分类,审核状态(未审核,已审核,审核成功),课程发布状态(未发布,已发布,下线),课程类型(是否收费)
course_category(课程分类表):
课程分类表。父结点id(第一级的父节点是0,自关联字段id,0,1,1-11,1-11,1-12,1-12,1-12),是否显示,是否叶子,排序字段。
course_market(课程营销表):
收费规则(对应数据字典),价格,有效天数,qq,微信
course_chapter(课程章节表):具体课程内容
id,父id,层级,类型(视频or文档),章节介绍,时长,
course_teacher(课程师资表):
id,课程id,教师id,职位,照片(存储的照片地址)
course_message(消息记录表,用于索引同步):
id,消息类型代码,失恋业务信息,通知次数,处理状态,回复失败内容,回复成功时间,最近通知时间,id,课程发布id,isRedis,isES,isMinIO
(2)xcplus_media
media_files(媒资信息表):
文件id(md5值),机构id,name,type(图片,文档,视频),bucket,路径,审核状态
media_upload(视频上传表):
id,文件id,name,bucket,url(路径),上传状态(未处理,上传中,成功,失败)
media_process(视频处理表):
id,文件id,name,bucket,url(路径),处理状态(未处理,处理中,成功,失败)
meida_content(媒资绑定表):
课程章节id,视频id
(3)xcplus_base
dictionary(字典表):
id,name,code,描述
(4)xcplus_users
user_company(机构表):
id,name,简介,营业执照,logo
user(用户表):
id,name,用户类型(学生,老师,管理员),phone,email
user_role(用户角色表,记录用户-角色):
id,用户id,角色id(一个用户会有多个角色)
user_permission(权限表,记录角色-权限):
id,角色id,权限代码(不是按用户类型,是数字)
user_menu(菜单表,记录权限-菜单):
id,name,pid,权限id(有什么权限,可以访问什么菜单)
(5)xcplus_learning
learn_choose(选课记录表):
id,课程id,用户id,选课状态(选课成功、待支付、选课删除),选课类型(免费课程、收费课程)
learn_courseTable(我的课表):
id,用户id,课程id,机构id
(6)xcplus_order
order(订单表):
id,总价,交易状态,用户id,订单类型,name,订单描述
order_goods(订单-物品表):
id,订单id,物品id,物品类型,物品价格
order_pay(订单支付记录表):
id,本系统支付交易id,第三方交易id,订单id,总价,币种,支付状态
1.base
(1)全局异常处理
1-@ControllerAdvice
1)系统自定义业务异常
抛给框架处理。运用AOP思想,@ControllerAdvice控制增强,通常和@ExceptionHandler结合使用。增强类处理。新建本项目自定义异常类型(继承runtimeexception),新建类写异常处理(可以区别捕获的异常类型)。使用该类的cast函数在业务代码中throw异常
2)jsr303异常
异常处理器中要解析jsr303的异常,定义枚举类
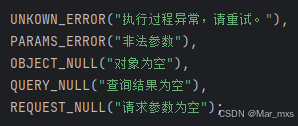
否则会报unknow的统一异常信息,因为他不属于xuecheng的程序员自定义类型异常。
(2)分页
1-mybatisplus
mybatisplus框架,定义pageParam和pageResult
(3)返回
1-高可用VO
定义返回的类型RestResponse
(4)工具类
一些自定义的utils
(5)拿到字典值
所有的魔法值都在这里拿
2.course(课程管理)
(1)课程查询
1-分页
每个服务的model去引入base依赖。使用时在微服务的service层配置@bean,mybatisPlusInterceptor拦截器指明数据库类型,进行分页。
Page<CourseBase> page = new Page<>(pageParams.getPageNo(), pageParams.getPageSize());
Page<CourseBase> pageResult = courseBaseMapper.selectPage(page, queryWrapper);
List<CourseBase> items = pageResult.getRecords();2-测试
postman,junit,httpclient
(2)课程新增
1-JSR303分组校验
JSR303分组校验。在Model的dto中分组校验,Controller中接收参数时在@RequestBody后插入
@Validated(ValidationGroups.Inster.class)
前端后端都要校验,为了防止使用postman等访问后端
2-数据库事务控制
关于文件上传过程中的事务控制,抽取出只有数据库操作的方法来加。在类内curProxy通过代理对象调用。
(3)课程分类查询
1-递归查询分类目录
with recursive t1 as (
select * from course_category p where id= '1'
union all
select t.* from course_category t inner join t1 on t1.id = t.parentid
)
select * from t1 order by t1.id, t1.orderby用mapper.select(),拿到数据表所有行,建立map(根结点排除,前端要查的是该id的childrenTree),key=id,value=一行。
从头遍历 List<CourseCategoryTreeDto> ,一边遍历一边找子节点放在父节点childrenTreeNodes
(4)课程营销增删改查
(5)课程计划增删改查
(6)课程审核
审核时不允许修改课程内容,以免发生冲突。
审核成功或失败后可以继续进行修改,重新进入到审核阶段
(7)课程发布
发布后公开展示在网站上供学生查看、选课和学习
1-CAP理论
要么cp,要么ap
C:一致性,查哪个结果都是最新的
A:可用性,都能查到结果,不保证最新
P:分区容忍性,网络通信异常情况下仍可对外服务
2-索引同步(AP)
如何快速搜索课程?
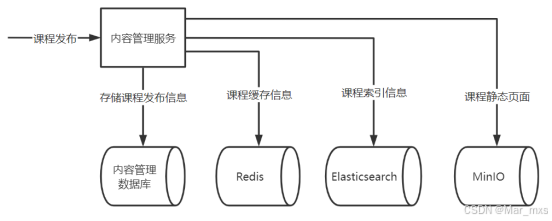
本地消息表+任务调度的机制来完成分布式事务的最终数据一致性的控制。建的本地消息表和课程发布表在同一个数据库,使用数据库事务控制,保证发布了就一定会在消息表中,然后任务调度定时调度消息表存储给redis,es,minIO。若当中有失败的,则下次定时会继续发,已经成功的根据幂等性,会跳过。
不是财务类似系统,采用AP服务
满足CP的话有一个写失败就要回滚
采用xxl-job,只要在一定时间内最终向redis、elasticsearch、MinIO写数据成功即可。
3-分布式事务(CP)
两阶段提交协议(2PC - Two-Phase Commit)
两阶段提交是最常见的分布式事务协议,分为两个阶段:准备阶段和提交阶段。
- 准备阶段(Prepare Phase):事务管理器向所有数据库发送“准备提交”请求,各参与者执行事务操作但不提交,并将状态返回给协调者。
- 提交阶段(Commit Phase):如果所有参与者都表示准备就绪,协调者发送“提交”指令,所有参与者正式提交事务;如果有一个参与者返回失败,协调者发送“回滚”指令,所有参与者撤销操作。
三阶段提交,要多一个预提交阶段,锁颗粒度更小,时间短。
4-openFeign
微服务之间的声明式调用。在nacos注册,请求来了之后到gateway负载均衡和请求转发,然后使用openfeign进行声明式调用。
5-Hystrix
Hystrix:设置超时时间。在FeignClient中指定fallbackFactory
熔断:保证C服务不会影响到B
降级:本地的一个方法,C出现问题时,给B返回说C出现问题了
返回一个null对象,上游服务请求接口得到一个null说明执行了降级处理。
3.media(媒资管理)
(1)上传照片
1-minIO
使用minIO来存储。分布式文件系统,损坏磁盘在1/2以下都可以恢复
bucket(桶)相当于存储的目录
有两个桶:mediafiles: 普通文件。video:视频文件
连接需要三个参数Endpoint(minio的http:端口)、Access Key(用户id)、Secret Key(密码)
增加:先使mimeType=通用的字节流,然后通过扩展名(.mp4)得到mimeType
通过路径去增删改查
根据bucket名和路径上传,看md5值判定是否已经在minio里。
@Transactional开启事务,因此需要impl内currentProxy
(2)上传视频
1-断点续传
视频比较大,所以需要断点续传
对文件分块,然后上传时检查,最后合并分块,校验是否完整
文件上传到一半不上传了,定时任务去表里查看视频处理表,删了
(3)处理视频
主要将视频格式统一保存,转mp4。(兼容性好,文件小)
1-xxl-job分布式任务调度(多线程)
高效处理任务,使用分布式+多线程,主要有调度中心、执行器、任务
调度中心:自身不承担业务代码,主要职责为执行器管理、任务管理、监控运维、日志管理等
执行器:负责接收调度请求并执行任务逻辑
任务:负责执行具体的业务处理
可以任务分片,为了保证多个执行器不重复执行
配置调度过期策略和阻塞处理策略,避免同一个执行器多次重复执行同一个任务
调度过期策略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间;
阻塞处理策略:丢弃后续调度。
和@Scheduled优缺点
优点:
不需要依赖外部框架。
简单快速实现任务。@EnableScheduling、@Scheduled 注解
缺点:
无法管理任务。要停止某个任务,必须重新发布。
不支持动态调整。修改任务参数需要重启项目。
不支持集群方式部署。集群模式下会出现任务多次被调度执行的情况,因为集群的节点之间是不会共享任务信息的,每个节点上的任务都会按时执行。
2-幂等性(分布式锁)
上传视频,如果正在处理中或处理完则不再处理
1.数据库锁(乐观)
谁update成功谁拿到锁
2.redis(setnx)
使用SETNX命令在Redis中设置一个键值对,如果该键不存在,则设置成功,表示获取到了锁;如果该键已经存在,则设置失败,表示锁已经被其他客户端持有。
为了避免锁的过期导致死锁,可以为锁设置一个过期时间
释放锁时,可以使用DEL命令删除对应的键。
3.另起线程看门狗
看线程是否干完活,可以续过期时间。
(4)绑定媒资
将媒资和课程内容章节绑定起来,写入到meida_content中
(5)课程预览
1-模板引擎
Jsp、Freemarker、Thymeleaf
一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配置文件,源代码等)的通用工具。
要在naocs的公用配置组添加freemarker-config-dev.yaml
在使用freemarker渲染生成视图时需要数据模型,此数据模型包括了基本信息、营销信息、课程内容、师资、课程视频等信息。
所以定义一个数据模型类,拿到这些信息,addobject给freemarker
静态化开发,在freemarker中替换课程名称、预览图片等
2-nginx
作为web服务器,访问静态资源,css、js、图片等。
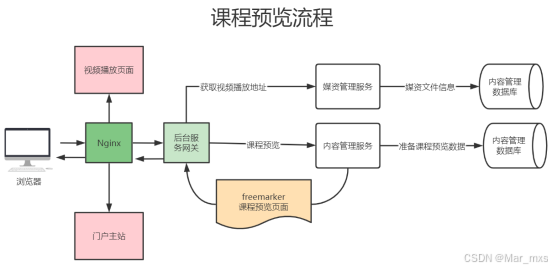
对http://file.51xuecheng.cn/mediafiles/网址进行转化,并且使本地html可以通过网址访问到
负载均衡,隐藏后端服务器地址,静态资源缓存可以频繁在本地访问,减少访问后端服务器次数
通过nginx访问网关,是最前方的代理。原来前端直接指向后台网关地址,现在要更改为Nginx地址
4.gateway
连接nacos。网关的yml中配置routes,uri使用loadbalance:uri: lb://content-api。
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/content/** # 这个是按照路径匹配,只要以/content/开头就符合,转给content-api
可以配置白名单:http://gatewayserver/content/open/
然后让nginx转到这个地址
1-nacos
服务注册中心和配置中心
1)配置文件名组成
namespace、group、dataid。
namespace(开发环境,测试环境,上线环境)和group(学成在线,瑞吉外卖)。
Dataid: 包括三部分:(content-service)-(dev). (yaml)三部分组成
content-service=application.yaml中配置的应用名,nacos 客户端要根据此确定配置文件名称,所以spring.application.name不在nacos中配置,而是要在工程的bootstrap.yml进行配置。
dev=spring.profiles.active
2)extend和shared
在项目的yml中,extension-configs是特有的,shared-configs是共有的。
因为api接口工程依赖了service工程 的jar,所以这里使用extension-configs扩展配置文件 的方式引用service工程所用到的配置文件
3)执行顺序及配置优先级
执行顺序:bootstrap.yml->nacos->application.yml
各配置文件的优先级:项目应用名配置文件(nacos自己根据spring.application.name找的) > 扩展配置文件 > 共享配置文件 > 本地配置文件(application.yml)。名字name在bootstrap.yml
2-跨域
浏览器同源策略:协议、ip、端口。服务器间没有
三种方案:
JSONP,通过script标签的src属性
添加响应头, Access-Control-Allow-Origin:(在system模块添加)
nginx代理跨域,因为服务器间没有
5.search
(1)课程搜索
1-elasticsearch
1)es结构
index是表,document是行,field是字段,mapping是结构
创建索引,并指定Mapping
通过GET /course-publish/_mapping 查询course-publish的索引结构
删除索引命令:DELETE /course-publish
2)倒排索引
倒排索引,对课程发布信息进行索引和搜索。
倒排索引将文档的内容作为索引的键,将文档的编号或者标识作为索引的值,从而可以根据关键词快速定位到包含该关键词的文档。倒排索引由词项(Terms)和倒排列表(Posting List)组成。
假设有以下文档:
- 文档1: "apple orange banana"
- 文档2: "apple banana"
- 文档3: "orange banana"
构建的倒排索引可能如下所示:
Term Posting List
apple 1, 2
orange 1, 3
banana 1, 2, 3
当用户输入一个关键词进行查询时,系统会根据关键词在倒排索引中查找对应的倒排列表,从而得到包含该关键词的文档编号或者标识,进而检索出相应的文档。
3)MultiMatchQuery(聚合搜索,根据关键字搜索)
根据关键字搜索name、description字段。
{
"query": {
"multi_match": {
"query": "搜索关键词",
"fields": ["字段1", "字段2", "字段3"],
"type": "best_fields" // 可选项,默认为best_fields
}
}
}还可以为每一个fields加权重,配置模糊查询
4)过滤器(根据确定的学科分类搜索)
根据分类、课程等级搜索采用过滤器实现精确查找,不用计算相关度得分,只是判断文档是否符合过滤条件,效率更高。
5)分页
6)高亮
2-kibana
通过可视化界面访问elasticsearch的索引库,进行测试的时候使用用DSL测试成功之后
{
"query": {
"bool": {
"must": {
"match": {
"content": "Elasticsearch"
}
},
"filter": {
"term": {
"status": "published"
}
}
}
}
}
正式使用java。
6.auth
(1)统一认证
认证通过由认证服务向给用户颁发令牌,相当于访问系统的通行证,用户拿着令牌去访问系统的资源
(2)单点登录
用户只需要认证一次,便可以在多个拥有访问权限的系统中访问。
1-JWT
普通令牌校验每次要去auth验证,而且是存在session,加大服务器压力
而JWT会给每个为微服务一个密钥,自己可以校验令牌。而且基于json,是无状态认证。
由三部分组成,header(头部),内容(用户的信息),签名(前两部分想加再加密),
一个接口有很多个实现类,在service中增加名字(password,wx,phone)
(3)权限控制(RBAC)
1-基于角色or资源访问控制
1)基于角色的访问控制
比如:主体的角色为总经理可以查询企业运营报表,查询员工工资信息等
if(主体.hasRole("总经理角色id")){
查询工资
}2)基于资源的访问控制
比如:用户必须具有查询工资权限才可以查询员工工资信息等,访问控制流程如下:
if(主体.hasPermission("查询工资权限标识")){
查询工资
}if里面写的是角色还是是否有这个权限(一个属性字段)。基于资源的访问控制健壮性更好。使用@PreAuthorize("hasAuthority('权限标识符')")进行控制,标识符会在数据库中定义。在方法前面加该注解,拥有此权限才可以访问该方法。
划分更加细致,可以有多种组合,不用定义非常多的用户类型,让用户去组合角色类型即可形成大量的权限等级。
细粒度授权(数据权限),对某一资源有访问权限,但是可以访问到的数据不一样,比如两个培训机构。course_base中有培训机构id。在service接口根据参数去做,security框架无法实现
(4)白名单(无需鉴权)
1-redis
redis存放白名单接口(无需认证即可访问)所需要的数据,缓存了普通用户所要查询的数据(我的订单、我的选课),缓存热点数据(最新发布的课程信息、推荐课程信息等)。
每类信息有不同的缓存过期时间,为了避免缓存雪崩缓存时间加了随机数。
1)如何限流:
-
令牌桶算法:通过在令牌桶中存放一定数量的令牌,每个令牌代表一个可用的请求。当有请求到来时,需要先从令牌桶中获取一个令牌,如果令牌桶中没有足够的令牌,则拒绝请求或者将请求放入队列中等待。
-
基于计数器的限流:通过Redis的计数器功能,可以对请求的数量进行计数,并根据设定的阈值来限制请求的流量。
-
漏桶算法:漏桶算法是另一种常见的流量控制算法,它通过固定速率从漏桶中漏出请求,当有请求到来时,将请求放入漏桶中,然后以固定速率处理漏桶中的请求。如果漏桶已满,则拒绝新的请求。
2)为什么快?
redis是单线程但速度依旧很快,基于内存的数据存储,使用了IO多路复用模型。
3)数据类型
string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
查询所有的key用:
KEYS *
SCAN 0 MATCH *
keys会阻塞一段时间,推荐用scan,因为是非阻塞的。
4)布隆过滤器
可以用来判断一个元素一定不在集合中,但不保证一定在集合中。
核心是一个位数组(Bit Array)和多个哈希函数
-
初始化:创建一个长度为m的位数组,所有位都初始化为0。
-
插入操作:将待插入的元素通过多个哈希函数计算出多个哈希值,然后将位数组中对应的位置置为1。
-
查询操作:将待查询的元素通过多个哈希函数计算出多个哈希值,然后检查位数组中对应的位置是否都为1。如果所有位置都为1,则说明该元素可能在集合中;如果存在任意一个位置不为1,则说明该元素一定不在集合中。
5)Zset
与普通集合相比,在存储元素的同时,每个元素都关联了一个分数(score),这样就可以根据分数对元素进行排序。
Zset的底层数据结构是跳跃表(Skip List)和哈希表(Hash Table)的结合。
跳表:负责元素的排序和范围查询,用于实现按分数的有序访问。
哈希表:负责快速查找元素的分数和判断元素是否存在,用于支持高效的增删改查操作。key是元素,value是元素分数
6)持久化
RDB:快照的持久化方式,在指定的时间间隔内将数据集快照写入磁盘,可能会丢失
AOF:基于日志的持久化方式,将写命令追加到文件末尾,文件大,恢复慢
2-缓存三兄弟
缓存穿透,高并发请求发现缓存中没有,会去多次查数据库。
解决方案:第一次请求时数据库中不存在数据给缓存到redis,但是值为null,加过期时间,防止数据库中什么时候真的有了该key。
缓存雪崩,缓存的大量key失效,因为他们设置了相同的缓存失效时间。
解决方案:对同一类型的key设置不同的过期时间。
缓存击穿,大量并发访问同一个热点数据,热点数据失效后同时访问数据库。
解决方案:热点数据不过期,有写操作时更新redis。
7.learning
(1)选课
收费课程,免费课程,选课成功后有课程资料权限
(2)支付
涉及订单数据库
1-RabbitMQ支付通知
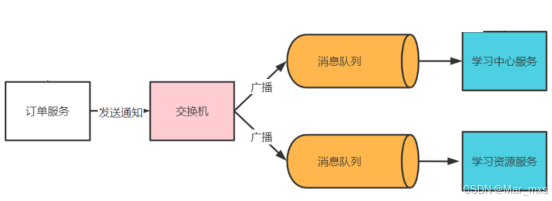
将支付结果发通过给fanout类型的交换机,由交换机将消息广播发送至每个接收支付结果的微服务。
1、订单服务创建支付结果通知交换机。
2、学习中心服务绑定队列到交换机。
为什么用:异步处理,用户体验更好,流量削峰,消息不会丢失。
1)丢失
消息持久化:在发送消息时,设置消息的持久化属性,确保消息被持久化到磁盘中,
确认机制:生产者消费者确认机制
2)重复
消息唯一标识:给每个消息分配一个唯一的ID,进行去重,避免重复处理相同的消息。
3)顺序
默认不有序。有序的话在消息的内容中添加序列号或者时间戳等标识。
4)堆积
定期监控队列深度:超过一定阈值时,触发报警或者自动进行处理。
消息 TTL 设置:为队列设置消息的 TTL(Time To Live),即消息的生存时间。当消息在指定的时间内没有被消费者处理,则消息会被丢弃或者进入死信队列,避免消息在队列中长时间堆积。
(3)学习
学生付费成功后可在线学习
8.难点
1-视频上传过程中断了怎么办?
2-多个微服务抢着去处理同一个视频

















 3364
3364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









