









处理数据集
本文用到的mstar数据集文件格式为mat格式,且图像像素为88×88,即数据是以numpy形式存储的。为了后面处理方便,我们需要将numpy数据读取并转换为tensor格式。代码如下:
# 从mat格式文件中读取numpy数据并转换为tensor格式(方法!!!)
data88 = scipy.io.loadmat('./mstar_data/88_88.mat')
train_data = data88['train_data']
train_label = data88['train_labels']
test_data = data88['test_data']
test_label = data88['test_labels']
print(train_data.shape, train_label.shape, test_data.shape,
test_label.shape) # (3671, 88, 88) (1, 3671) (3203, 88, 88) (1, 3203)
train_data = train_data.reshape(3671, 1, 88, 88) # 灰度图像
test_data = test_data.reshape(3203, 1, 88, 88)
print(train_data.shape, train_label.shape, test_data.shape, test_label.shape)
train_data, train_label, test_data, test_label = map(torch.tensor, (
train_data, train_label.squeeze(), test_data, test_label.squeeze()))
print(train_data.shape, train_label.shape, test_data.shape, test_label.shape) # numpy转tensor可以看到,将数据reshape为(图片个数,通道数,88,88),这里通道数为1。
数据集标准化
标准化处理输⼊数据使各个特征的分布相近,这往往更容易训练出有效的模型。因此我们对数据集进行标准化,代码如下:
# 数据集标准化
mean = train_data.mean()
std = train_data.std()
print(mean, std)
train_data = (train_data - mean) / std
test_data = (test_data - mean) / std
print(train_data.mean(), train_data.std(), test_data.mean(), test_data.std())训练集10中样本可视化
先编写显示并保存图像的函数:
def plot_image(img, label, img_name, clas):
fig = plt.figure()
for i in range(10):
plt.subplot(2, 5, i + 1)
# plt.tight_layout()
plt.imshow(img[i].view(88, 88), cmap='gray')
plt.title("{}:{}".format(img_name, label[i].item())) # item()的作用是取出tensor格式的元素值并返回该值,保持原元素类型不变
plt.xticks([])
plt.yticks([])
plt.savefig('fig' + clas)
plt.show()之后我们可以输出训练集的10张图片看一下。将训练集中train_label为0~9的第一张图片都输出,代码及输出结果如下:
# 训练集10种样本可视化
train_data09 = []
train_label09 = []
for i in range(10):
train_data09.append(train_data[train_label == i][0]) # 这里要再加[0]才能正常显示label=i时的第一组图片
train_label09.append(torch.tensor(i)) # 因为此时train_label就等于i,但train_label是tensor格式,因此需要将i转换为tensor格式
print(len(train_data09), train_label09)
plot_image(train_data09, train_label09, 'label', '88_88')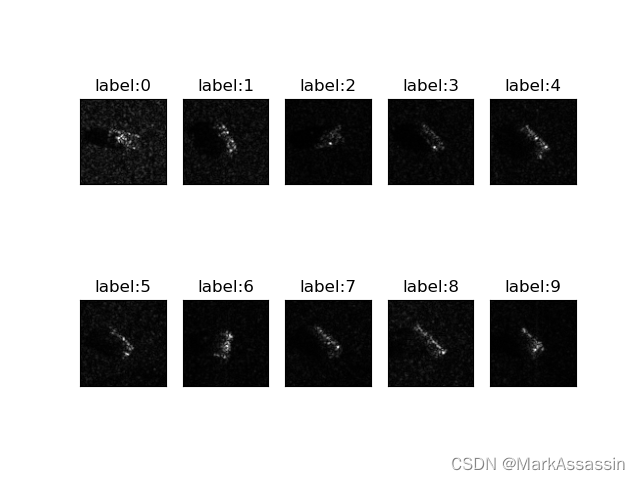
加载数据集
与能够在Pytorch官网下载的数据集(如CIFAR10、MNIST)处理方式不同,因为之前已经将其转换为了Tensor格式,所以需要先将其图片和标签打包在一起,然后再用DataLoader进行batch打包,代码如下:
# 加载数据集
train_xy = TensorDataset(train_data, train_label) # 相当于将图片和对应的标签打包在了一起
test_xy = TensorDataset(test_data, test_label)
train = DataLoader(train_xy, batch_size=64, shuffle=True) # shuffle=True用于打乱数据集,每次都会以不同的顺序返回
test = DataLoader(test_xy, batch_size=256)
print(len(train_xy), len(train), len(test_xy), len(test))这里的shuffle可以将数据集随机打乱,每次训练都以不同的batch顺序进行。这里笔者将训练集和测试集的batch_size分别设置为64和256。
搭建神经网络
本文的神经网络结构参考了Target Classification Using the Deep Convolutional Networks for SAR Images Sizhe Chen, Student Member, IEEE, Haipeng Wang, Member, IEEE,FengXu,Senior Member, IEEE,and Ya-Qiu Jin, Fellow, IEEE这篇文章,该神经网络的特点是没有设置全连接层,整个网络全部是由卷积层构成的,网络结构如下:
由于网络中全是卷积层,因此需要对每一层的卷积核、最大池化层的参数进行设置,从而使输出的维度为10×1×1,网络如下:
class mstar88_cnn(nn.Module): # n=88
def __init__(self):
super(mstar88_cnn, self).__init__()
self.model_cnn = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=0), # n=84
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # 42
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=0), # 38
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # 19
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=6, stride=1, padding=0), # 14
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # 7
nn.Dropout(0.5), # 这里用Dropout2d应该也可以
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=5, stride=1, padding=0), # 3
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=10, kernel_size=3, stride=1, padding=0), # 1
nn.BatchNorm2d(10)
)
def forward(self, x):
x = self.model_cnn(x)
x = x.view(x.shape[0], -1) # 矩阵的每一行就是这个批量中每张图片的各个参数,即矩阵中一行对应一张图片
x = F.softmax(x, 1)
return x输入的维度为1×88×88,经过每一层后像素为(n-f+2*p)/s+1。最终输出一个列向量,其每一行代表一张图像。这里的BatchNorm归一化运算一般加在卷积运算和ReLU函数之间,使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
训练网络
设置好网络、损失函数、优化器、训练次数等,并初始化好存放loss和accuracy的列表,后面画训练损失和准确度图时会用到。这里需要注意以下几点:
1.如果在设置损失函数是使用的是nn.CrossEntropyLoss(),那么在搭建多分类神经网络的最后就不用再进行softmax运算,因为这个“交叉熵”函数内部会自动进行softmax运算;
2.训练的一般步骤就是梯度清零(optimizer.zero_grad())、反向传播(loss.backward())、参数优化(optimizer.step())。
3.enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,因此它给每个batch都标了序号,存放在batch_idx中。
笔者是每轮整个训练和测试结束后再输出训练和测试各自的loss和accuracy值。代码如下:
model = mstar88_cnn()
model.to(device)
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
learning_rate = 0.001
# optimizer=torch.optim.SGD(params=model.parameters(),lr=learning_rate,momentum=0.9)
train_acc_list = []
train_loss_list = []
test_acc_list = []
test_loss_list = []
epochs = 10
for epoch in range(epochs):
if (epoch + 1) == 50:
learning_rate = learning_rate * 0.9
optimizer = torch.optim.SGD(params=model.parameters(), lr=learning_rate, momentum=0.9)
print("-----第{}轮训练开始------".format(epoch + 1))
train_loss = 0.0
test_loss = 0.0
train_sum, train_cor, test_sum, test_cor = 0, 0, 0, 0
# 训练步骤开始
model.train()
for batch_idx, data in enumerate(train):
inputs, labels = data
inputs, labels=inputs.to(device),labels.to(device)
labels = torch.tensor(labels, dtype=torch.long) # 需要将label转换成long类型
optimizer.zero_grad()
outputs = model(inputs.float()) # 需要加.float(),否则会报错
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
# 计算每轮训练集的Loss
train_loss += loss.item()
# 计算每轮训练集的准确度
_, predicted = torch.max(outputs.data, 1) # 选择最大的(概率)值所在的列数就是他所对应的类别数,
train_cor += (predicted == labels).sum().item() # 正确分类个数
train_sum += labels.size(0) # train_sum+=predicted.shape[0]
# 测试步骤开始
model.eval()
# with torch.no_grad():
for batch_idx1, data in enumerate(test):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
labels = torch.tensor(labels, dtype=torch.long)
outputs = model(inputs.float())
loss = loss_fn(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
test_cor += (predicted == labels).sum().item()
test_sum += labels.size(0)
print("Train loss:{} Train accuracy:{}% Test loss:{} Test accuracy:{}%".format(train_loss / batch_idx,
100 * train_cor / train_sum,
test_loss / batch_idx1,
100 * test_cor / test_sum))
train_loss_list.append(train_loss / batch_idx)
train_acc_list.append(100 * train_cor / train_sum)
test_acc_list.append(100 * test_cor / test_sum)
test_loss_list.append(test_loss / batch_idx1)
# 保存网络
torch.save(model, "mstar_88_epoch{}.pth".format(epochs))画出曲线
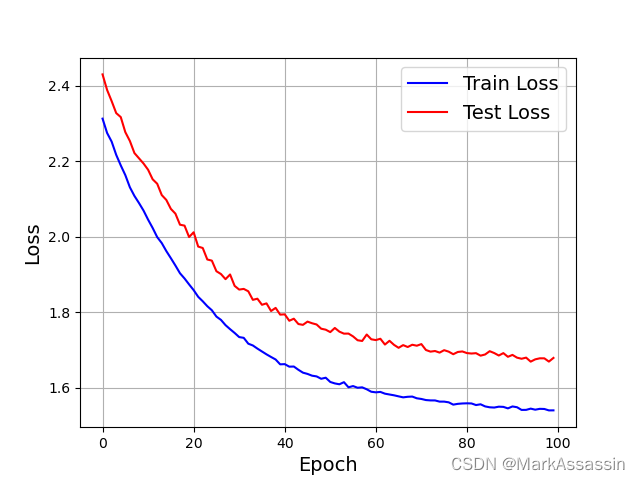
最后,画出损失和准确率的曲线,代码及图像如下:
fig = plt.figure()
plt.plot(range(len(train_loss_list)), train_loss_list, 'blue')
plt.plot(range(len(test_loss_list)), test_loss_list, 'red')
plt.legend(['Train Loss', 'Test Loss'], fontsize=14, loc='best')
plt.xlabel('Epoch', fontsize=14)
plt.ylabel('Loss', fontsize=14)
plt.grid()
plt.savefig('figLOSS')
plt.show()
fig = plt.figure()
plt.plot(range(len(train_acc_list)), train_acc_list, 'blue')
plt.plot(range(len(test_acc_list)), test_acc_list, 'red')
plt.legend(['Train Accuracy', 'Test Accuracy'], fontsize=14, loc='best')
plt.xlabel('Epoch', fontsize=14)
plt.ylabel('Accuracy(%)', fontsize=14)
plt.grid()
plt.savefig('figAccuracy')
plt.show()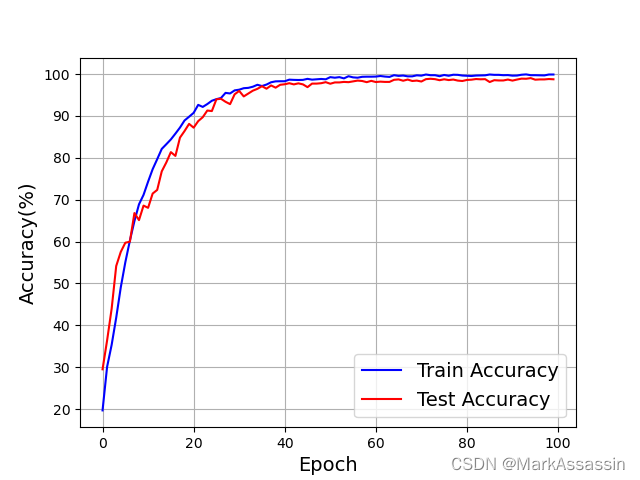
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









