







密度峰值算法(Clustering by fast search and find of density peaks),一种基于密度的聚类方法,主要思想是寻找被低密度区域分离的高密度区域。 密度峰值算法(DPCA)的假设:
(1)类簇中心点的密度大于周围邻居点的密度;
(2)类簇中心点与更高密度点之间的距离相对较大。
DPCA 有两个需要计算的量:局部密度;与高密度点之间的距离。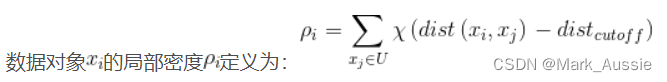
dist(cutoff) 是阶段距离,
![]() 代表找到与第
代表找到与第个数据点之间的距离小于截断距离
的数据个数,
将其作为第 i 个数据点的密度。

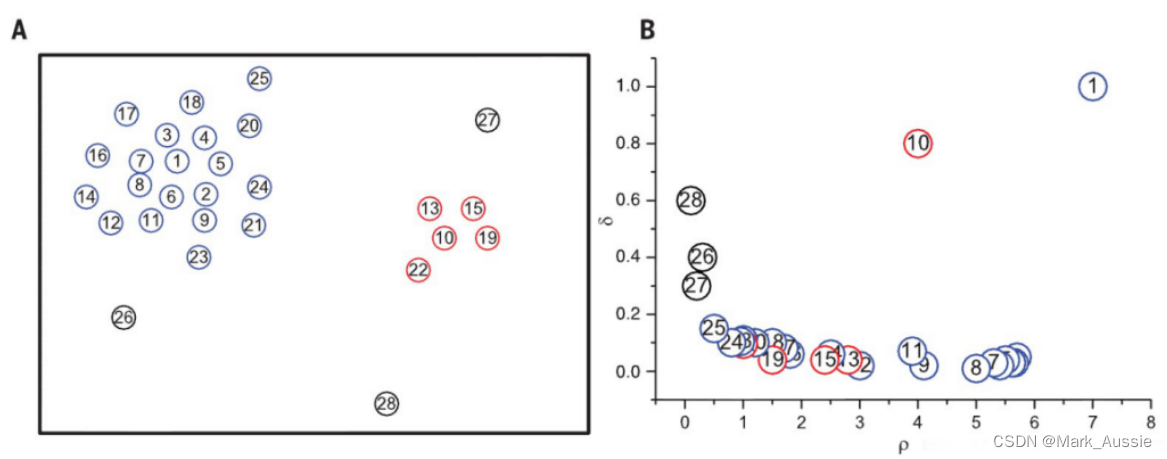
密度峰聚类算法的重点在于聚类中心距离 δi的选定。根据局部密度的定义,计算出上图中每个点的密度,依照密度确定聚类中心距离 δi。
1. 将每个点的密度从大到小排列: ρi > ρj > ρk > ….;密度最大的点的聚类中心距离与其他点的聚类中心距离的确定方法是不一样的;
2.先确定密度最大的点的聚类中心距离–i点是密度最大的点,聚类中心距离 δi 等于与 i 点最远点 n到 i 的直线距离 d(i,n);
3. 再确定其他点的聚类中心距离——其他点的聚类中心距离是等于在密度大于该点的集合中,与该点距离最小的的那个距离。如i、j、k的密度都比n点的密度大,且j点离n点最近,则n点的聚类中心距离等于d(j,n)。
4. 依次确定所有的聚类中心距离δ
将所有点的聚类中心密度都统计出来后,按 δi 和 pi 作为坐标轴作图可以得到的结果,图中1,10两个聚类中心同时远离坐标轴。普通点则是靠近p轴,异常点靠近 δ轴。
参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









