








假设现有系统部署了上万个服务,用户通过浏览器在主界面下单一箱茅台酒,系统给用户提示:系统内部错误,运营人员将问题抛给开发人员定位,开发人员只知道有异常,但是这个异常具体是由哪个微服务引起的就需要逐个服务排查了。
界面出现异常难以排查后台服务,借助日志逐个排查的效率非常低,此时可使用链路追踪系统。
分布式链路追踪就是将一次分布式请求还原成调用链路,将一次分布式请求的调用集中展示,比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
链路跟踪主要功能:
-
故障快速定位:可以通过调用链结合业务日志快速定位错误信息。
-
链路性能可视化:各个阶段链路耗时、服务依赖关系可以通过可视化界面展现出来。
-
链路分析:分析链路耗时、服务依赖关系得到用户行为路径,汇总分析多业务场景。
链路追踪系统(可能)最早是由Goggle公开发布的论文
《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》提出,
论文主要讲述Dapper链路追踪系统的基本原理和关键技术点。
Trace:链路,一个请求经过所有服务的路径,可用树状图表示。

上图是一条完整的链路:chrome -> 服务A -> 服务B -> 服务C -> 服务D -> 服务E -> 服务C -> 服务A -> chrome。服务间经过的局部链路构成了一条完整的链路,其中每一条局部链路都用一个全局唯一的 traceid 标识。
Span:上图中,请求经过服务A,服务A又调用服务B和C,但是调用顺序只有差代码才能确定;
为表达父子关系引入 Span 概念,同一层级 parent id 相同,span id不同,span id从小到大表示请求的顺序,从下图中可以很明显看出服务A是先调了服务B然后再调用了C,上下层级代表调用关系,下图中服务C的span id为2,服务D的parent id为2,表示服务C和服务D形成父子关系,是服务C调用了服务D。
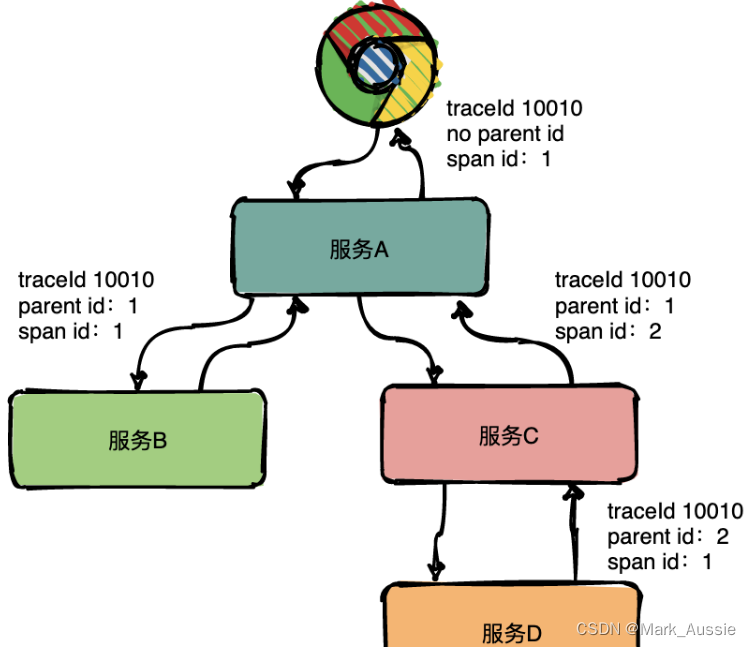
通过事先在日志中埋点,找出相同 traceId 日志,再加上 parent id 和 span id,就可以将一条完整的请求调用链串联起来。
Annotation:用户自定义事件,辅助定位问题。
通常包含四个注解信息:
cs:Client Start,表示客户端发起请求;
sr:ServerReceived,表示服务端收到请求;
ss:Server Send,表示服务端完成处理,并将结果发送给客户端;
cr:ClientReceived,表示客户端获取到服务端返回信息;
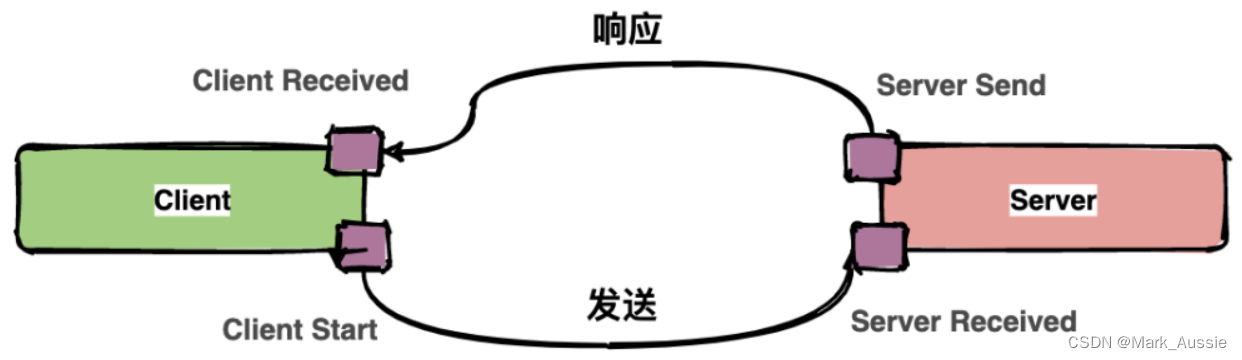
一次请求和响应过程:四个点对应四个Annotation事件。
如下面的图表示从客户端调用服务端的一次完整过程。如果要计算一次调用的耗时,只需要将客户端接收的时间点减去客户端开始的时间点,也就是图中时间线上的T4 - T1。如果要计算客户端发送网络耗时,也就是图中时间线上的T2 - T1,其他类似可计算。
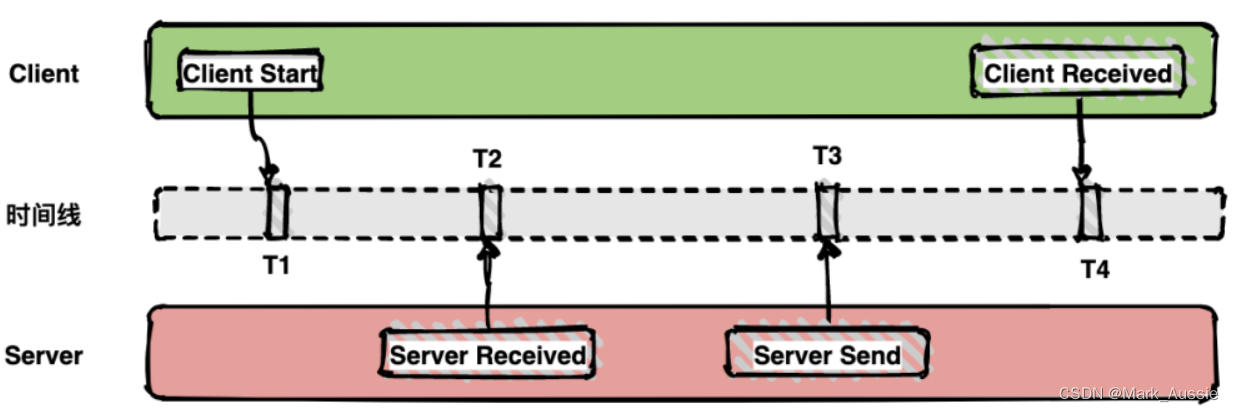
链路信息的还原依赖于带内和带外两种数据;
带外数据是各个节点产生的事件,如cs,ss,这些数据可以由节点独立生成,并且需要集中上报到存储端。通过带外数据,可以在存储端分析更多链路的细节。
带内数据如traceid,spanid,parentid,标识trace,span,及span在一个trace中的位置,这些数据需要从链路的起点一直传递到终点。通过带内数据的传递,可以将一个链路的所有过程串起来。
采样:由于每一个请求都会生成一个链路,为减少性能消耗,避免存储资源浪费,dapper并不会上报所有的span数据,而是使用采样的方式。举个例子,每秒有1000个请求访问系统,如果设置采样率为1/1000,只会上报一个请求到存储端。
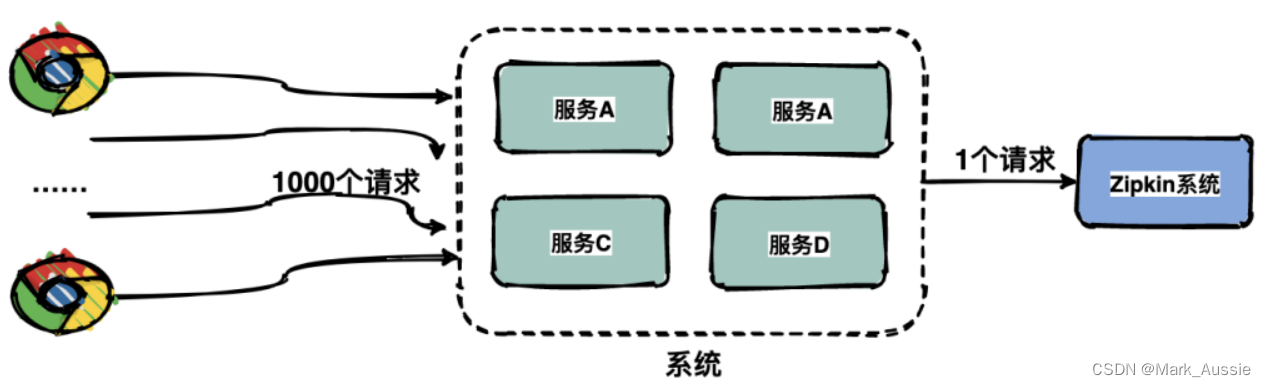
数据采样:通过采集端自适应地调整采样率,控制span上报的数量,可以在发现性能瓶颈的同时,有效减少性能损耗。
存储:链路中的span数据经过收集和上报后集中存储在一个地方,Dapper使用了BigTable数据仓库,常用的存储还有ElasticSearch, HBase, In-memory DB等。

小结:
-
分布式链路追踪就是将每一次分布式请求还原成调用链路。
-
链路追踪的核心概念:Trace、Span、Annotation、带内和带外数据、采样、存储。
-
业界常用的开源组件都是基于谷歌Dapper论文演变而来;
-
Zipkin核心组件有:Collector、Storage、Query Service、Web UI。
参考:















 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









