







笔记简介
笔记:记录一下实现Informer时序预测的过程,同时加注一些要点,并加上构建自己数据集进行预测的过程。
内容:
1、Informer论文解读、复现
2、构建自己的数据集
3、利用Informer对数据集进行预测
一、Informer论文

摘要:许多实际应用需要长序列时间序列的预测,例如电力消耗计划。长序列时间序列预测(LSTF)要求模型具有较高的预测能力,即能够准确有效地捕捉输出与输入之间的长期依赖耦合。最近的研究表明,Transformer可以提高预测能力。然而,然而,Transformer存在几个严重的问题,这些问题使它无法直接应用于LSTF,包括二次时间复杂度、高内存使用和编码器-解码器架构的固有限制。为了解决这些问题,我们为LSTF设计了一个高效的基于Transformer的模型,名为Informer,它具有三个显著的特征:1、ProbSparse自注意力机制,该机制在时间复杂度和内存使用上达到 ,并且在序列依赖对齐方面具有相当的性能。2、自注意力提取通过将级联层输入减半来突出主导注意力,并有效地处理超长输入序列。3、生成式解码器虽然在概念上简单,但它可以通过一次前向运算而不是一步一步地预测长时间序列序列,从而大大提高了长序列预测的推理速度。在四个大规模数据集上的大量实验表明,Informer算法显著优于现有方法,为LSTF问题提供了一种新的解决方案。
论文地址:https://arxiv.org/abs/2012.07436
官方代码地址:https://github.com/zhouhaoyi/Informer2020
二、Informer网络结构
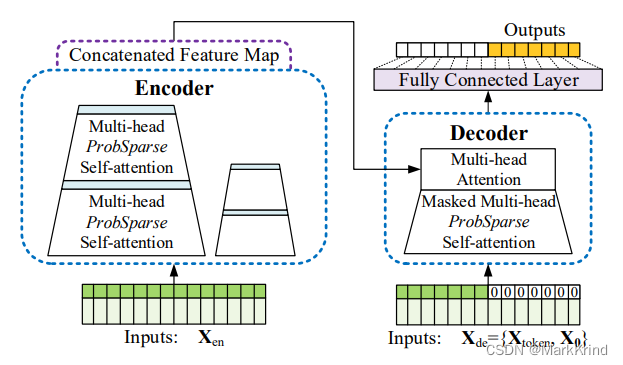
左:编码器接收大量长序列输入(绿色序列)。用ProbSparse自注意力机制代替了典型的自注意力机制。蓝色梯形是自注意力提取操作,用于提取主导注意力,大幅减少网络规模。层堆叠副本增加了鲁棒性。右:解码器接收长序列输入,将目标元素填充为零,测量特征图的加权注意力组成,并以生成风格即时
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











