






在上个博客中,我们已经知道了,词法分析中的词法规范就是用正则表达式来实现的,我们用正则表达式来表述了编程语言中各种不同的token class。
而有限自动机也是一种正则表达式的应用实现,它和正则表达式密切相关,它能够表述和正则表达式一样的规范
自动机中一些常见的符号
:一组能够读取的合法的输入字符集
S:一组有限的状态
n:一个开始状态
F:一组可接受状态
->:一组转化公式,在指定状态读取到指定输入值后可以转化为另种状态
If end of input and in accepting state => accept :自动机可以不断读取输入的字符串,并基于输入不断从当前状态转变为新的状态,当字符串被读取结束后,要求状态必须处于aceepting state,这样才能表明这个字符串是合法的,被接受的。
Otherwise => reject : 如果输入的字符串在读取结束后,最后的状态不属于可接受的状态,或者说在读取的中途发现没有可用的transition进行状态转化,那么都会被拒绝,表示则个字符串是非法的。
自动机常见图形表示方法

自动机语言
Language of a FA set of accepted strings
有一个比较常见的词,自动机语言,其实自动机语言就是指那些能够被该自动机接受的字符串的集合。
NFA和DFA
 -move(空跳)
-move(空跳)

这是这种特殊的状态转化,表示从状态A可以什么都不接受直接转化为状态B
DFA
One transition per input per state
No -move
DFA中要求一个状态接受一个输入,只可能转化为另一个确定的状态。每个输入在DFA中有一条已经确定的转换路径,当这条路径的转换结果决定了这个输入是accepted还是reject。
因此DFA中就不允许有-move转换存在
NFA
Can have multiple transitions for one input in a given state
Can have -move
NFA允许一个状态接受一个输入时,可能转化为多种不同的状态。每个输入在NFA就有多种转换路径可以选择,部分可能是accepted,部分是reject,只要有一条路径是accepted,那这个输入就是accepted的。
因此NFA中就允许有-move转换存在
NFA和DFA均能表示正则表达式
因此DFA和NFA的最大差别就在于没有空跳的存在
DFA执行的效率更高,因为无需做选择,NFA有多种可能性
NFA的优势在于通常情况会更小,一般规模是成指数级别的缩小
Regular Expressions to NFAs

一般来说,正则表达式中可以有以下常见的NFA转化方法
AB,两个正则表达式的级联
A+B,两个正则表达式的并集

A^*,A的Iteration

我们可以利用上述的3个公式来将一个复杂的正则表达式来分步骤绘画出NFA
NFA to DFA
-closure

某个状态S的eplison闭包,举例说明:closure(B) = {B 、C、D},我们看到闭包中的状态集合就是这个状态可以通过空跳到达的状态的集合
下面我们来思考一个问题
NFA读取一个字符串进行处理的时候,处理过程中由于每次状态都有多种选择,因此可能处于多种状态,那么这个多种状态的可能性有几种?
假设一个NFA的状态数量为N,那么这个NFA在执行过程中就有2^n-1种不同非空状态的组合,我们可以看到NFA执行过程中状态的组合数量是有限的, 虽然这个数字可能会很大。
finit set of possible configurations:状态组合的数量有限的特点给NFA->DFA的转化提供了灵感

上图是给出NFA和DFA转化关系
NFA中状态集合S,开始状态s,接受状态集合F,以及一系列转化公式和空跳转换
那么如何将这个NFA转换为DFA呢?
我们将NFA中每个可能的状态组合都作为一种新的状态来看待
DFA中的状态集合S'=S的子集
开始状态s'=s的epsilon的闭包
接受状态集合:
转换公式相比NFA中将空跳删除,并将其余的转换公式中的目标状态改为epsilon的闭包
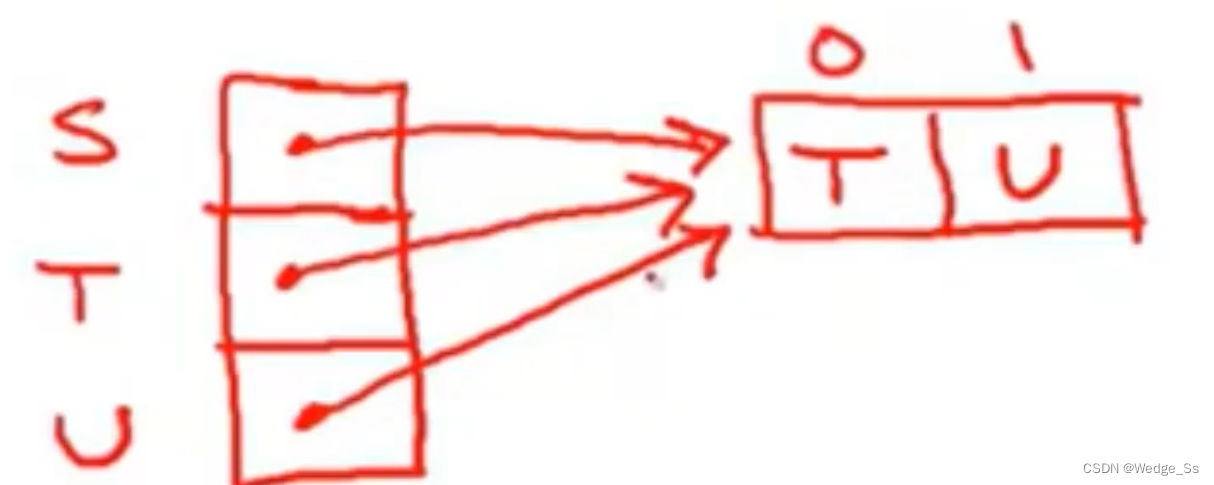
如何表示DFA
DFA可以使用一个二维数组来进行表示
一维是状态,另一维是字符
对于一个转换公式S_i\rightarrow^aS_j,在这个二维数组中表示方式为T[i,a] = j
// 对于DFA而言,代码实现非常简单紧凑
int i = 0;
int state = 0;
while (input[i])
{
s = T[s][input[i++]];
}
对于一个有N个状态的NFA而言,转换成为一个DFA,可能DFA的状态数量会非常多,我们在上面已经计算过DFA的状态可能有2^N - 1个,这就会导致DFA的这个二维数组变得非常大。
如何解决二维数组过大的问题?如何进行优化?
这个二维数组可能存在很多重复行,避免重复数据的存储,我们可以改用指针的形式来实现更加紧凑的存储。
NFA->DFA的转换并非必要
NFA的状态数量很少,但是转换过程中由于存在多种状态的可能性,我们需要实时保存当前可能所处的状态,然后对遍历这些可能的状态进行状态的转换。
NFA的特点就在于,内存开销小,但是计算开销会大大增加,速度慢
DFA的状态数量很多,但是转换过程每次只可能从一个确定状态转化到另个确定的状态
DFA的特点在于,内存开销大,但是计算开销小,性能很高
因此,NFA和DFA之间的选择其实就是计算开销和内存开销之间的trade off,并非任何时候都是DFA适用。















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









