研究点:硬件加速FPGA版 针对网络: MobileNet 并行设计: ①标准卷积层:仅在MobileNet网络第一层,受限于AXI总线(64/16)传输数据给深度卷积运算, 输入通道展开 卷积核展开 输出通道展开 输出特征图展开 并行度 3 9 4 1 108 ②深度可分离卷积层: ②.1:深度卷积并行设计 输入INPUT: 由表2-2可知,来自两个部分,①标准卷积的输出;②点卷积的输出。 采用多路选择器M








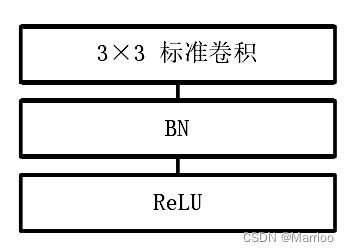
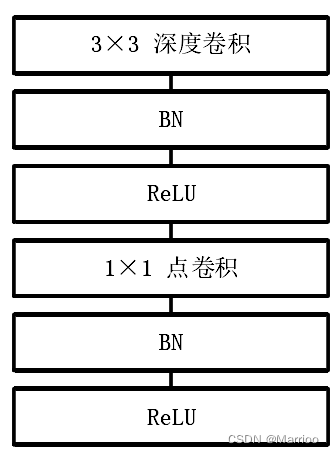
 该博客详细介绍了基于FPGA的MobileNet硬件加速器设计,探讨了标准卷积和深度可分离卷积的并行策略,包括层间融合的BN处理,并展示了硬件加速模块的设计,包括标准卷积、深度卷积和点卷积模块,以及整体系统框架的构建。针对AXI总线限制和DDR交互进行了讨论。
该博客详细介绍了基于FPGA的MobileNet硬件加速器设计,探讨了标准卷积和深度可分离卷积的并行策略,包括层间融合的BN处理,并展示了硬件加速模块的设计,包括标准卷积、深度卷积和点卷积模块,以及整体系统框架的构建。针对AXI总线限制和DDR交互进行了讨论。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






