







💥💥💞💞欢迎来到Matlab仿真科研站博客之家💞💞💥💥
✅博主简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,Matlab项目合作可私信。
🍎个人主页:Matlab仿真科研站博客之家
🏆代码获取方式:
💥扫描文章底部QQ二维码💥
⛳️座右铭:行百里者,半于九十;路漫漫其修远兮,吾将上下而求索。

⛄更多Matlab路径规划(仿真科研站版)仿真内容点击👇
Matlab路径规划(仿真科研站版)
⛄一、VRP简介
1 VRP基本原理
车辆路径规划问题(Vehicle Routing Problem,VRP)是运筹学里重要的研究问题之一。VRP关注有一个供货商与K个销售点的路径规划的情况,可以简述为:对一系列发货点和收货点,组织调用一定的车辆,安排适当的行车路线,使车辆有序地通过它们,在满足指定的约束条件下(例如:货物的需求量与发货量,交发货时间,车辆容量限制,行驶里程限制,行驶时间限制等),力争实现一定的目标(如车辆空驶总里程最短,运输总费用最低,车辆按一定时间到达,使用的车辆数最小等)。
VRP的图例如下所示:
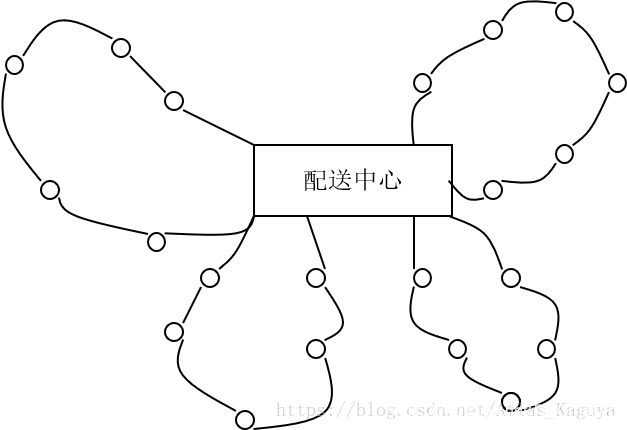
2 问题属性与常见问题
车辆路径问题的特性比较复杂,总的来说包含四个方面的属性:
(1)地址特性包括:车场数目、需求类型、作业要求。
(2)车辆特性包括:车辆数量、载重量约束、可运载品种约束、运行路线约束、工作时间约束。
(3)问题的其他特性。
(4)目标函数可能是总成本极小化,或者极小化最大作业成本,或者最大化准时作业。
3 常见问题有以下几类:
(1)旅行商问题
(2)带容量约束的车辆路线问题(CVRP)



该模型很难拓展到VRP的其他场景,并且不知道具体车辆的执行路径,因此对其模型继续改进。



(3)带时间窗的车辆路线问题
由于VRP问题的持续发展,考虑需求点对于车辆到达的时间有所要求之下,在车辆途程问题之中加入时窗的限制,便成为带时间窗车辆路径问题(VRP with Time Windows, VRPTW)。带时间窗车辆路径问题(VRPTW)是在VRP上加上了客户的被访问的时间窗约束。在VRPTW问题中,除了行驶成本之外, 成本函数还要包括由于早到某个客户而引起的等待时间和客户需要的服务时间。在VRPTW中,车辆除了要满足VRP问题的限制之外,还必须要满足需求点的时窗限制,而需求点的时窗限制可以分为两种,一种是硬时窗(Hard Time Window),硬时窗要求车辆必须要在时窗内到达,早到必须等待,而迟到则拒收;另一种是软时窗(Soft Time Window),不一定要在时窗内到达,但是在时窗之外到达必须要处罚,以处罚替代等待与拒收是软时窗与硬时窗最大的不同。


模型2(参考2017 A generalized formulation for vehicle routing problems):
该模型为2维决策变量

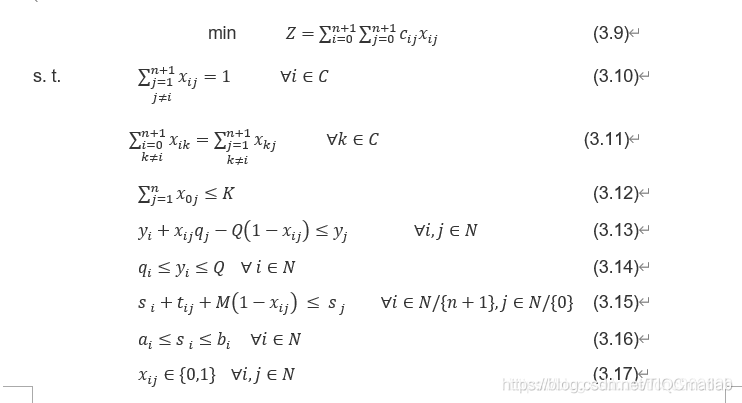

(4)收集和分发问题
(5)多车场车辆路线问题
参考(2005 lim,多车场车辆路径问题的遗传算法_邹彤, 1996 renaud)
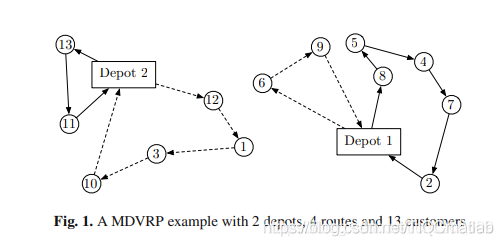
由于车辆是同质的,这里的建模在变量中没有加入车辆的维度。


(6)优先约束车辆路线问题
(7)相容性约束车辆路线问题
(8)随机需求车辆路线问题
4 解决方案
(1)数学解析法
(2)人机交互法
(3)先分组再排路线法
(4)先排路线再分组法
(5)节省或插入法
(6)改善或交换法
(7)数学规划近似法
(8)启发式算法
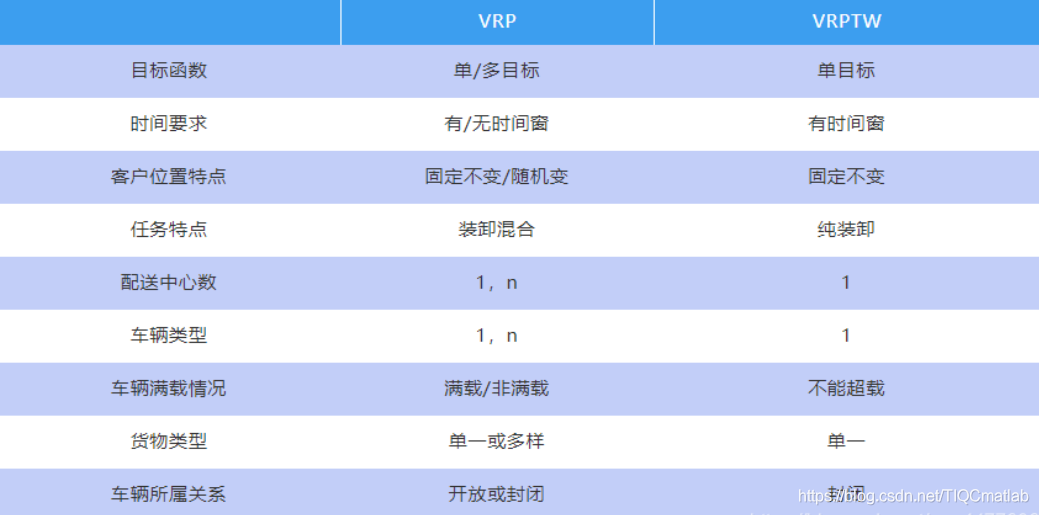
5 VRP与VRPTW对比
⛄二、禁忌搜索算法简介
1 引言
一个问题的求解过程就是搜索,它是人工智能的一个基本问题,而人工智能在各应用领域中被广泛地使用。现在搜索技术渗透在各种人工智能系统中,可以说没有哪一种人工智能的应用不用搜索方法。
禁忌搜索算法(Tabu Search or Taboo Search, TS) 的思想最早由美国工程院院士Glover教授于1986年提出[] , 并在1989年和1990年对该方法做出了进一步的定义和发展[2-4]。在自然计算的研究领域
中,禁忌搜索算法以其灵活的存储结构和相应的禁忌准则来避免迂回搜索,在智能算法中独树一帜,成为一个研究热点,受到了国内外学者的广泛关注。迄今为止,禁忌搜索算法在组合优化、生产调度、机器学习、电路设计和神经网络等领域取得了很大的成功,近年来又在函数全局优化方面得到较多的研究,并有迅速发展的趋势[5-8].
所谓禁忌,就是禁止重复前面的操作。为了改进局部邻域搜索容易陷入局部最优点的不足,禁忌搜索算法引入一个禁忌表,记录下已经搜索过的局部最优点,在下一次搜索中,对禁忌表中的信息不再搜索或有选择地搜索,以此来跳出局部最优点,从而最终实现全局优化。禁忌搜索算法是对局部邻域搜索的一种扩展,是一种全局邻域搜索、逐步寻优的算法。
禁忌搜索算法是一种迭代搜索算法,它区别于其他现代启发式算法的显著特点,是利用记忆来引导算法的搜索过程;它是对人类智力过程的一种模拟,是人工智能的一种体现。禁忌搜索算法涉及邻域、
禁忌表、禁忌长度、候选解、藐视准则等概念,在邻域搜索的基础上,通过禁忌准则来避免重复搜索,并通过藐视准则来赦免一些被禁忌的优良状态,进而保证多样化的有效搜索来最终实现全局优化。
2禁忌搜索算法理论
2.1局部邻域搜索
局部邻域搜索是基于贪婪准则持续地在当前的邻域中进行搜索,虽然其算法通用,易于实现,且容易理解,但其搜索性能完全依赖于邻域结构和初始解,尤其容易陷入局部极小值而无法保证全局优化。
局部搜索的算法可以描述为:


这种邻域搜索方法易于理解,易于实现,而且具有很好的通用性,但是搜索结果的好坏完全依赖于初始解和邻域的结构。若邻域结构设置不当,或初始解选择不合适,则搜索结果会很差,可能只会搜
索到局部最优解,即算法在搜索过程中容易陷入局部极小值。因此,若不在搜索策略上进行改进,要实现全局优化,局部邻域搜索算法采用的邻域函数就必须是“完全”的,即邻域函数将导致解的完全枚
举。而这在大多数情况下是无法实现的,而且穷举的方法对于大规模问题在搜索时间上也是不允许的。为了实现全局搜索,禁忌搜索采用允许接受劣质解的策略来避免局部最优解。
2.2禁忌搜索
禁忌搜索算法是模拟人的思维的一种智能搜索算法,即人们对已搜索的地方不会再立即去搜索,而是去对其他地方进行搜索,若没有找到,可再搜索已去过的地方。禁忌搜索算法从一个初始可行解出
发,选择一系列的特定搜索方向(或称为“移动”)作为试探,选择使目标函数值减小最多的移动。为了避免陷入局部最优解,禁忌搜索中采用了一种灵活的“记忆”技术,即对已经进行的优化过程进行记录,指导下一步的搜索方向,这就是禁忌表的建立。禁忌表中保存了最近若干次迭代过程中所实现的移动,凡是处于禁忌表中的移动,在当前迭代过程中是禁忌进行的,这样可以避免算法重新访问在最近若
干次迭代过程中已经访问过的解,从而防止了循环,帮助算法摆脱局部最优解。另外,为了尽可能不错过产生最优解的“移动”,禁忌搜索还采用“特赦准则”的策略。
对一个初始解,在一种邻域范围内对其进行一系列变化,从而得到许多候选解。从这些候选解中选出最优候选解,将候选解对应的目标值与“best so far”状态进行比较。若其目标值优于“best sofar”状态, 就将该候选解解禁, 用来替代当前最优解及其“best sofar”状态, 然后将其加入禁忌表, 再将禁忌表中相应对象的禁忌长度改变:如果所有的候选解中所对应的目标值都不存在优于“best sofar”状态, 就从这些候选解中选出不属于禁忌对象的最佳状态, 并将其作为新的当前解,不用与当前最优解进行比较,直接将其所对应的对象作为禁忌对象,并将禁忌表中相应对象的禁忌长度进行修改。
2.3禁忌搜索算法的特点
禁忌搜索算法是在邻域搜索的基础上,通过设置禁忌表来禁忌一些已经进行过的操作,并利用藐视准则来奖励一些优良状态,其中邻域结构、候选解、禁忌长度、禁忌对象、藐视准则、终止准则等是影
响禁忌搜索算法性能的关键。邻域函数沿用局部邻域搜索的思想,用于实现邻域搜索;禁忌表和禁忌对象的设置,体现了算法避免迂回搜索的特点:藐视准则,则是对优良状态的奖励,它是对禁忌策略的一种放松。
与传统的优化算法相比,禁忌搜索算法的主要特点是:
(1)禁忌搜索算法的新解不是在当前解的邻域中随机产生,它要么是优于“best so far”的解, 要么是非禁忌的最佳解, 因此选取优良解的概率远远大于其他劣质解的概率。
(2)由于禁忌搜索算法具有灵活的记忆功能和藐视准则,并且在搜索过程中可以接受劣质解,所以具有较强的“爬山”能力,搜索时能够跳出局部最优解,转向解空间的其他区域,从而增大获得更好的全局最优解的概率。因此,禁忌搜索算法是一种局部搜索能力很强的全局迭代寻优算法。
2.4禁忌搜索算法的改进方向
禁忌搜索是著名的启发式搜索算法,但是禁忌搜索也有明显的不足,即在以下方面需要改进:
(1)对初始解有较强的依赖性,好的初始解可使禁忌搜索算法在解空间中搜索到好的解,而较差的初始解则会降低禁忌搜索的收敛速度。因此可以与遗传算法、模拟退火算法等优化算法结合,先产生较好的初始解,再用禁忌搜索算法进行搜索优化。
(2)迭代搜索过程是串行的,仅是单一状态的移动,而非并行搜索。为了进一步改善禁忌搜索的性能,一方面可以对禁忌搜索算法本身的操作和参数选取进行改进,对算法的初始化、参数设置等方面实
施并行策略,得到各种不同类型的并行禁忌搜索算法[9]:另一方面则可以与遗传算法、神经网络算法以及基于问题信息的局部搜索相结合。
(3)在集中性与多样性搜索并重的情况下,多样性不足。集中性搜索策略用于加强对当前搜索的优良解的邻域做进一步更为充分的搜索,以期找到全局最优解。多样性搜索策略则用于拓宽搜索区域,尤
其是未知区域,当搜索陷入局部最优时,多样性搜索可改变搜索方向,跳出局部最优,从而实现全局最优。增加多样性策略的简单处理手段是对算法的重新随机初始化,或者根据频率信息对一些已知对象进行惩罚。
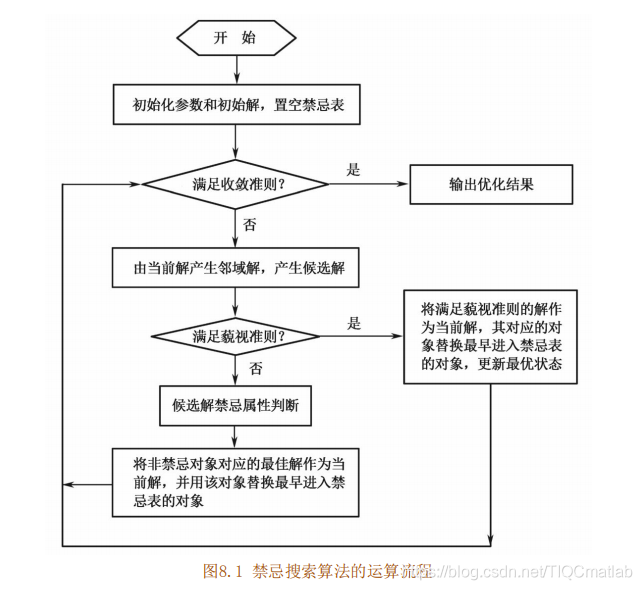
3 禁忌搜索算法流程
简单禁忌搜索算法的基本思想是:给定一个当前解(初始解)和一种邻域,然后在当前解的邻域中确定若干候选解;若最佳候选解对应的目标值优于“best so far”状态, 则忽视其禁忌特性, 用它替代当前解和“best so far”状态, 并将相应的对象加入禁忌表, 同时修改禁忌表中各对象的任期:若不存在上述候选解,则在候选解中选择非禁忌的最佳状态为新的当前解,而无视它与当前解的优劣,同时将相应的对象加入禁忌表,并修改禁忌表中各对象的任期。如此重复上述迭代搜索过程,直至满足停止准则。其算法步骤可描述如下:
(1)给定禁忌搜索算法参数,随机产生初始解x,置禁忌表为空。
(2)判断算法终止条件是否满足:若是,则结束算法并输出优化结果:否则,继续以下步骤。
(3)利用当前解的邻域函数产生其所有(或若干)邻域解,并从中确定若干候选解。
(4)对候选解判断藐视准则是否满足:若满足,则用满足藐视准则的最佳状态y替代x成为新的当前解,即x=y,并用与y对应的禁忌对象替换最早进入禁忌表的禁忌对象, 同时用y替换“best so far”状态,然后转步骤(6):否则,继续以下步骤。
(5)判断候选解对应的各对象的禁忌属性,选择候选解集中非禁忌对象对应的最佳状态为新的当前解,同时用与之对应的禁忌对象替换最早进入禁忌表的禁忌对象。
(6)判断算法终止条件是否满足:若是,则结束算法并输出优化结果:否则,转步骤(3)。
禁忌搜索算法的运算流程如图8.1所示。
4 关键参数说明
一般而言,要设计一个禁忌搜索算法,需要确定算法的以下环节:初始解、适配值函数、邻域结构、禁忌对象、候选解选择、禁忌表、禁忌长度、藐视准则、搜索策略、终止准则[10,11]。面对如此众
多的参数,针对不同邻域的具体问题,很难有一套比较完善的或非常严格的步骤来确定这些参数。
初始解
禁忌搜索算法可以随机给出初始解,也可以事先使用其他启发式算法等给出一个较好的初始解。由于禁忌搜索算法主要是基于邻域搜索的,初始解的好坏对搜索的性能影响很大。尤其是一些带有很复杂
约束的优化问题,如果随机给出的初始解很差,甚至通过多步搜索也很难找到一个可行解,这时应该针对特定的复杂约束,采用启发式方法或其他方法找出一个可行解作为初始解;再用禁忌搜索算法求解,以提高搜索的质量和效率。也可以采用一定的策略来降低禁忌搜索对初始解的敏感性。
适配值函数
禁忌搜索的适配值函数用于对搜索进行评价,进而结合禁忌准则和特赦准则来选取新的当前状态。目标函数值和它的任何变形都可以作为适配值函数。若目标函数的计算比较困难或耗时较长,此时可采
用反映问题目标的某些特征值来作为适配值,进而改善算法的时间性能。选取何种特征值要视具体问题而定,但必须保证特征值的最佳性与目标函数的最优性一致。适配值函数的选择主要考虑提高算法的效率、便于搜索的进行等因素。
邻域结构
所谓邻域结构,是指从一个解(当前解)通过“移动”产生另一个解(新解)的途径,它是保证搜索产生优良解和影响算法搜索速度的重要因素之一。邻域结构的设计通常与问题相关。邻域结构的设计方法很多,对不同的问题应采用不同的设计方法,常用设计方法包括互换、插值、逆序等。不同的“移动”方式将导致邻域解个数及其变化情况的不同,对搜索质量和效率有一定影响。
通过移动,目标函数值将产生变化,移动前后的目标函数值之差,称之为移动值。如果移动值是非负的,则称此移动为改进移动:否则,称之为非改进移动。最好的移动不一定是改进移动,也可能是
非改进移动,这一点能保证在搜索陷入局部最优时,禁忌搜索算法能自动把它跳出局部最优。
禁忌对象
所谓禁忌对象,就是被置入禁忌表中的那些变化元素。禁忌的目的则是为了尽量避免迂回搜索而多搜索一些解空间中的其他地方。归纳而言,禁忌对象通常可选取状态本身或状态分量等。
候选解选择
候选解通常在当前状态的邻域中择优选取,若选取过多将造成较大的计算量,而选取较少则容易“早熟”收敛,但要做到整个邻域的择优往往需要大量的计算,因此可以确定性地或随机性地在部分邻域中选取候选解,具体数据大小则可视问题特征和对算法的要求而定。
禁忌表
不允许恢复(即被禁止) 的性质称作禁忌(Tabu) 。禁忌表的主要目的是阻止搜索过程中出现循环和避免陷入局部最优,它通常记录前若干次的移动,禁止这些移动在近期内返回。在迭代固定次数后,
禁忌表释放这些移动,重新参加运算,因此它是一个循环表,每迭代一次,就将最近的一次移动放在禁忌表的末端,而它的最早的一个移动就从禁忌表中释放出来。
从数据结构上讲,禁忌表是具有一定长度的先进先出的队列。禁忌搜索算法使用禁忌表禁止搜索曾经访问过的解,从而禁止搜索中的局部循环。禁忌表可以使用两种记忆方式:明晰记忆和属性记忆。明
晰记忆是指禁忌表中的元素是一个完整的解,消耗较多的内存和时间:属性记忆是指禁忌表中的元素记录当前解移动的信息,如当前解移动的方向等。
禁忌长度
所谓禁忌长度,是指禁忌对象在不考虑特赦准则的情况下不允许被选取的最大次数。通俗地讲,禁忌长度可视为禁忌对象在禁忌表中的任期。禁忌对象只有当其任期为0时才能被解禁。在算法的设计和构
造过程中,一般要求计算量和存储量尽量小,这就要求禁忌长度尽量小。但是,禁忌长度过小将造成搜索的循环。禁忌长度的选取与问题特征相关,它在很大程度上决定了算法的计算复杂性。
一方面,禁忌长度可以是一个固定常数(如t=c,c为一常数),或者固定为与问题规模相关的一个量(如t=√n,n为问题维数或规模),如此实现起来方便、简单,也很有效:另一方面,禁忌长度也可以是动态变化的,如根据搜索性能和问题特征设定禁忌长度的变化区间,而禁忌长度则可按某种规则或公式在这个区间内变化。
藐视准则
在禁忌搜索算法中,可能会出现候选解全部被禁忌,或者存在一个优于“best so far”状态的禁忌候选解, 此时特赦准则将某些状态解禁,以实现更高效的优化性能。特赦准则的常用方式有:
(1) 基于适配值的原则:某个禁忌候选解的适配值优于“bestso far”状态, 则解禁此候选解为当前状态和新的“best so far”状态。
(2)基于搜索方向的准则:若禁忌对象上次被禁忌时使得适配值有所改善,并且目前该禁忌对象对应的候选解的适配值优于当前解,则对该禁忌对象解禁。
搜索策略
搜索策略分为集中性搜索策略和多样性搜索策略。集中性搜索策略用于加强对优良解的邻域的进一步搜索。其简单的处理手段可以是在一定步数的迭代后基于最佳状态重新进行初始化,并对其邻域进行再次搜索。在大多数情况下,重新初始化后的邻域空间与上一次的邻域空间是不一样的,当然也就有一部分邻域空间可能是重叠的。多样性搜索策略则用于拓宽搜索区域,尤其是未知区域。其简单的处理手段可以是对算法的重新随机初始化,或者根据频率信息对一些已知对象进行惩罚。
终止准则
禁忌搜索算法需要一个终止准则来结束算法的搜索进程,而严格理论意义上的收敛条件,即在禁忌长度充分大的条件下实现状态空间的遍历,这显然是不可能实现的。因此,在实际设计算法时通常采用
近似的收敛准则。常用的方法有:
(1)给定最大迭代步数。当禁忌搜索算法运行到指定的迭代步数之后,则终止搜索。
(2)设定某个对象的最大禁忌频率。若某个状态、适配值或对换等对象的禁忌频率超过某一阈值,或最佳适配值连续若干步保持不变,则终止算法。
(3)设定适配值的偏离阈值。首先估计问题的下界,一旦算法中最佳适配值与下界的偏离值小于某规定阈值,则终止搜索。
⛄三、部分源代码
%Ini adalah implementasi Tabu Search untuk Traveling Salesman
%Problem
%untuk merekam waktu komputasi yang dibutuhkan
tic;
clear
clc
%输入数据
N = 31;
TT=[1 82 76
2 96 44
3 50 5
4 49 8
5 13 7
6 29 89
7 58 30
8 84 39
9 14 24
10 2 39
11 3 82
12 5 10
13 98 52
14 84 25
15 61 59
16 1 65
17 88 51
18 91 2
19 19 32
20 93 3
21 50 93
22 98 14
23 5 42
24 42 9
25 61 62
26 9 97
27 80 55
28 57 69
29 23 15
30 20 70
31 85 60
32 98 5];
X = TT(:,2);
Y = TT(:,3);
ZZ=[1 0
2 19
3 21
4 6
5 19
6 7
7 12
8 16
9 6
10 16
11 8
12 14
13 21
14 16
15 3
16 22
17 18
18 19
19 1
20 24
21 8
22 12
23 4
24 8
25 24
26 24
27 2
28 20
29 15
30 2
31 14
32 9];
Demand =ZZ(:,2);
Vehicle_load = 100; %车辆载重限制
% Parameter TS
runcount= 500;
Solution_count = 200;
% 计算出城市之间的距离矩阵
Distancematrix = generatedistancematrix(X, Y);
JaarakSolusiMaksimum = sum(sum(Distancematrix));
%生成初始解
%Candidate_TSP_xulie = GenerateSolusiNearestNeighbour(Distancematrix);
Candidate_TSP_xulie = generatesolusirandom(N); %初始序列(随机生成一个n的序列)
Candidate_VRP_xulie = converttovrpsolution(Candidate_TSP_xulie, Demand, Vehicle_load); %初始解
Candidate_VRP_value = calculatetotaldistance(Candidate_VRP_xulie, Distancematrix); %车辆行驶距离Candidate_VRP_value
% 禁忌表初始化
tabulength = 10;
TabuList = ones(tabulength, 3);
%Catat kondisi awal
%Tsekarang = Tawal;
SolusiTerbaik = Candidate_TSP_xulie; %全局序列
best_so_far.VRP = Candidate_VRP_xulie; %全局解
best_so_far.value = Candidate_VRP_value; % 全局目标值
SolusiSaatIni = Candidate_TSP_xulie; %solusi iterasi %全局序列
SolusiVRPSaatIni = Candidate_VRP_xulie; %solusi iterasi %全局解
JarakSolusiSaatIni = Candidate_VRP_value; % Jarak solusi iterasi %全局目标值
Neighborhood_TSP_xulie = zeros(Solution_count, N + 2); %生成一个10012的矩阵,用于存放变异后的解
Neighborhood_VRP_xulie = zeros(Solution_count, N * 2 + 1); %生成一个10021的矩阵
Neighborhood_VRP_value = zeros(1, Solution_count);%生成一个1100的矩阵
Variation_list = zeros(Solution_count, 3); %生成一个1003的矩阵,用于存放每个解的变异的种类和变异的两个位置
better_so_far_TSP.xulie = Candidate_TSP_xulie ;
better_so_far_VRP.xulie = Candidate_VRP_xulie;
best_so_far.value =Candidate_VRP_value;
better_so_far_TSP_Tabu.xulie = zeros(1, N + 2);
better_so_far_VRP_Tabu.xulie = zeros(1, N * 2 + 1);
better_so_far_Tabu.value = 0;
preObjV=best_so_far.value;
figure;
hold on;box on
xlim([0,runcount])
title(‘优化过程’)
xlabel(‘代数’)
ylabel(‘最优值’)
% Mulai iterasi TS
for i = 1 : runcount%1000
line([i-1,i],[preObjV,best_so_far.value]);pause(0.0001)
preObjV=best_so_far.value;
%generate solusi tetangga
for j = 1 : Solution_count %100
Pilihan = randi(3); %randi 生成均匀分布的伪随机整数,用于判断使用哪一种变异
switch (Pilihan)
case 1 % 1-insert
[Neighborhood_TSP_xulie(j, :) Index_1 Index_2 ] = PerformInsert(SolusiSaatIni); %变异,返回变异后序列,变异的客户点
Neighborhood_VRP_xulie(j, :) = converttovrpsolution(Neighborhood_TSP_xulie(j, :), Demand, Vehicle_load);
Neighborhood_VRP_value(j) = calculatetotaldistance(Neighborhood_VRP_xulie(j, :), Distancematrix);
case 2 % 1-swap
[Neighborhood_TSP_xulie(j, :) Index_1 Index_2 ] = PerformSwap(SolusiSaatIni); %变异,两个位置的客户点对调
Neighborhood_VRP_xulie(j, :) = converttovrpsolution(Neighborhood_TSP_xulie(j, :), Demand, Vehicle_load);
Neighborhood_VRP_value(j) = calculatetotaldistance(Neighborhood_VRP_xulie(j, :), Distancematrix);
case 3 % 2-opt
[Neighborhood_TSP_xulie(j, :) Index_1 Index_2 ] = Perform2Opt(SolusiSaatIni); %变异,两个位置之间的客户点完全颠倒
Neighborhood_VRP_xulie(j, :) = converttovrpsolution(Neighborhood_TSP_xulie(j, :), Demand, Vehicle_load);
Neighborhood_VRP_value(j) = calculatetotaldistance(Neighborhood_VRP_xulie(j, :), Distancematrix);
end
Variation_list(j, :) = [Pilihan Index_1 Index_2];
end
%bedakan antara yg tabu maupun yg tidak tabu
ApakahTabu = zeros(1, Solution_count); %Solution_count=100控制每一代解的个数,100*1的矩阵
for j = 1 : Solution_count
for k = 1 : tabulength %tabulength=10
if Variation_list(j, :) == TabuList(k, :) %判断每一代当中的100个解的变异种类和变异的位置是否在禁忌表中
ApakahTabu(j) = 1; %ApakahTabu是一个100*1的矩阵用于判断100个解的变异类别是否已经在禁忌表中
end
end
end
%寻找每代100个候选解中在禁忌表中和不在禁忌表中的最佳解,并记录其位置
better_so_far_Tabu_ord = 1;
better_so_far_ord = 1;
better_so_far.value = JaarakSolusiMaksimum; %存放到目前为止不在禁忌表中的最小值,一开始用一个比较大的值表示
better_so_far_Tabu.value = JaarakSolusiMaksimum; %存放禁忌表中的最小值,一开始用一个比较大的值表示
for j = 1 : Solution_count %
if ApakahTabu(j) == 0 % 判断第i代100个解的变异类型是否在禁忌表中,0表示不在
if Neighborhood_VRP_value(j) < better_so_far.value %判断Neighborhood_VRP_value(100个解的车辆行驶距离)
better_so_far_TSP.xulie = Neighborhood_TSP_xulie(j, :); %存放不在禁忌表中的到当前为止的最佳TSP
better_so_far_VRP.xulie = Neighborhood_VRP_xulie(j, :); %存放不在禁忌表中的到目前为止的最佳VRP
better_so_far.value = Neighborhood_VRP_value(j); %存放不在禁忌表中的目前为止的最佳车辆行驶距离
better_so_far_ord = j; %存放不在禁忌表中的到目前为止的最佳解的位置,即每代第几个解,100个解都查看过去后就变成每代最佳解
end
else
if Neighborhood_VRP_value(j) <better_so_far_Tabu.value
better_so_far_TSP_Tabu.xulie = Neighborhood_TSP_xulie(j, :);
better_so_far_VRP_Tabu.xulie = Neighborhood_VRP_xulie(j, :);
better_so_far_Tabu.value = Neighborhood_VRP_value(j);
better_so_far_Tabu_ord = j;
end
end
end
% 比较每代100个不在禁忌表和在禁忌表中的最佳候选解的大小,并根据是否满足藐视规则更新禁忌表,最佳值
if better_so_far_Tabu.value < best_so_far.value %表示不满足藐视规则,因为禁忌表的最小值小于不在禁忌表的最小值,说明这一代100个候选解的最佳解小于全局最佳解
SolusiTerbaik = better_so_far_TSP_Tabu.xulie; %solusi global
best_so_far.VRP = better_so_far_VRP_Tabu.xulie; %solusi global
best_so_far.value = better_so_far_Tabu.value; % Jarak solusi global
SolusiSaatIni = better_so_far_TSP_Tabu.xulie; %solusi iterasi
SolusiVRPSaatIni = better_so_far_VRP_Tabu.xulie; %solusi iterasi
JarakSolusiSaatIni = better_so_far_Tabu.value; % Jarak solusi iterasi
%更新禁忌表
IndeksTabuList = mod(i, tabulength) + 1; %tabulength=10
TabuList(IndeksTabuList, 😃 = Variation_list(better_so_far_Tabu_ord, 😃;
else %满足藐视规则
SolusiSaatIni = better_so_far_TSP.xulie; %solusi iterasi
SolusiVRPSaatIni = better_so_far_VRP.xulie; %solusi iterasi
JarakSolusiSaatIni = better_so_far.value; % Jarak solusi iterasi
if better_so_far.value < best_so_far.value
SolusiTerbaik = better_so_far_TSP.xulie; %solusi global
best_so_far.VRP = better_so_far_VRP.xulie; %solusi global
best_so_far.value = better_so_far.value; % Jarak solusi global
end
%update tabu list
IndeksTabuList = mod(i, tabulength) + 1;
TabuList(IndeksTabuList, 😃 = Variation_list(better_so_far_ord, 😃;
end
end
% disp(‘berapa kali PP’);
% berapakalipp = hitungberapakalipp (sol2);
% disp(berapakalipp);
disp (‘Jarak Terbaik’);
disp (best_so_far.value);
disp (best_so_far.VRP);
toc
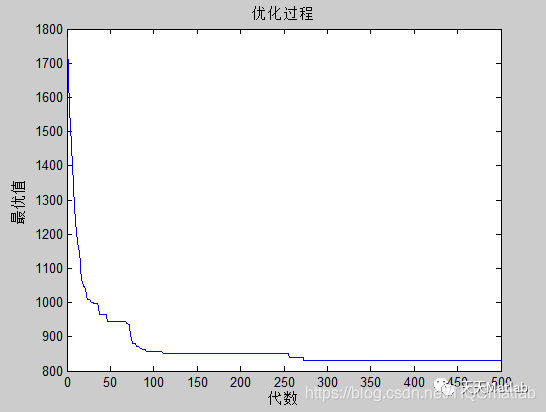
⛄四、运行结果
⛄五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]苏欣欣,秦虎,王恺.禁忌搜索算法求解带时间窗和多配送人员的车辆路径问题[J].重庆师范大学学报(自然科学版). 2020,37(01)
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
🍅 仿真咨询
1 各类智能优化算法改进及应用
1.1 PID优化
1.2 VMD优化
1.3 配电网重构
1.4 三维装箱
1.5 微电网优化
1.6 优化布局
1.7 优化参数
1.8 优化成本
1.9 优化充电
1.10 优化调度
1.11 优化电价
1.12 优化发车
1.13 优化分配
1.14 优化覆盖
1.15 优化控制
1.16 优化库存
1.17 优化路由
1.18 优化设计
1.19 优化位置
1.20 优化吸波
1.21 优化选址
1.22 优化运行
1.23 优化指派
1.24 优化组合
1.25 车间调度
1.26 生产调度
1.27 经济调度
1.28 装配线调度
1.29 水库调度
1.30 货位优化
1.31 公交排班优化
1.32 集装箱船配载优化
1.33 水泵组合优化
1.34 医疗资源分配优化
1.35 可视域基站和无人机选址优化
2 机器学习和深度学习分类与预测
2.1 机器学习和深度学习分类
2.1.1 BiLSTM双向长短时记忆神经网络分类
2.1.2 BP神经网络分类
2.1.3 CNN卷积神经网络分类
2.1.4 DBN深度置信网络分类
2.1.5 DELM深度学习极限学习机分类
2.1.6 ELMAN递归神经网络分类
2.1.7 ELM极限学习机分类
2.1.8 GRNN广义回归神经网络分类
2.1.9 GRU门控循环单元分类
2.1.10 KELM混合核极限学习机分类
2.1.11 KNN分类
2.1.12 LSSVM最小二乘法支持向量机分类
2.1.13 LSTM长短时记忆网络分类
2.1.14 MLP全连接神经网络分类
2.1.15 PNN概率神经网络分类
2.1.16 RELM鲁棒极限学习机分类
2.1.17 RF随机森林分类
2.1.18 SCN随机配置网络模型分类
2.1.19 SVM支持向量机分类
2.1.20 XGBOOST分类
2.2 机器学习和深度学习预测
2.2.1 ANFIS自适应模糊神经网络预测
2.2.2 ANN人工神经网络预测
2.2.3 ARMA自回归滑动平均模型预测
2.2.4 BF粒子滤波预测
2.2.5 BiLSTM双向长短时记忆神经网络预测
2.2.6 BLS宽度学习神经网络预测
2.2.7 BP神经网络预测
2.2.8 CNN卷积神经网络预测
2.2.9 DBN深度置信网络预测
2.2.10 DELM深度学习极限学习机预测
2.2.11 DKELM回归预测
2.2.12 ELMAN递归神经网络预测
2.2.13 ELM极限学习机预测
2.2.14 ESN回声状态网络预测
2.2.15 FNN前馈神经网络预测
2.2.16 GMDN预测
2.2.17 GMM高斯混合模型预测
2.2.18 GRNN广义回归神经网络预测
2.2.19 GRU门控循环单元预测
2.2.20 KELM混合核极限学习机预测
2.2.21 LMS最小均方算法预测
2.2.22 LSSVM最小二乘法支持向量机预测
2.2.23 LSTM长短时记忆网络预测
2.2.24 RBF径向基函数神经网络预测
2.2.25 RELM鲁棒极限学习机预测
2.2.26 RF随机森林预测
2.2.27 RNN循环神经网络预测
2.2.28 RVM相关向量机预测
2.2.29 SVM支持向量机预测
2.2.30 TCN时间卷积神经网络预测
2.2.31 XGBoost回归预测
2.2.32 模糊预测
2.2.33 奇异谱分析方法SSA时间序列预测
2.3 机器学习和深度学习实际应用预测
CPI指数预测、PM2.5浓度预测、SOC预测、财务预警预测、产量预测、车位预测、虫情预测、带钢厚度预测、电池健康状态预测、电力负荷预测、房价预测、腐蚀率预测、故障诊断预测、光伏功率预测、轨迹预测、航空发动机寿命预测、汇率预测、混凝土强度预测、加热炉炉温预测、价格预测、交通流预测、居民消费指数预测、空气质量预测、粮食温度预测、气温预测、清水值预测、失业率预测、用电量预测、运输量预测、制造业采购经理指数预测
3 图像处理方面
3.1 图像边缘检测
3.2 图像处理
3.3 图像分割
3.4 图像分类
3.5 图像跟踪
3.6 图像加密解密
3.7 图像检索
3.8 图像配准
3.9 图像拼接
3.10 图像评价
3.11 图像去噪
3.12 图像融合
3.13 图像识别
3.13.1 表盘识别
3.13.2 车道线识别
3.13.3 车辆计数
3.13.4 车辆识别
3.13.5 车牌识别
3.13.6 车位识别
3.13.7 尺寸检测
3.13.8 答题卡识别
3.13.9 电器识别
3.13.10 跌倒检测
3.13.11 动物识别
3.13.12 二维码识别
3.13.13 发票识别
3.13.14 服装识别
3.13.15 汉字识别
3.13.16 红绿灯识别
3.13.17 虹膜识别
3.13.18 火灾检测
3.13.19 疾病分类
3.13.20 交通标志识别
3.13.21 卡号识别
3.13.22 口罩识别
3.13.23 裂缝识别
3.13.24 目标跟踪
3.13.25 疲劳检测
3.13.26 旗帜识别
3.13.27 青草识别
3.13.28 人脸识别
3.13.29 人民币识别
3.13.30 身份证识别
3.13.31 手势识别
3.13.32 数字字母识别
3.13.33 手掌识别
3.13.34 树叶识别
3.13.35 水果识别
3.13.36 条形码识别
3.13.37 温度检测
3.13.38 瑕疵检测
3.13.39 芯片检测
3.13.40 行为识别
3.13.41 验证码识别
3.13.42 药材识别
3.13.43 硬币识别
3.13.44 邮政编码识别
3.13.45 纸牌识别
3.13.46 指纹识别
3.14 图像修复
3.15 图像压缩
3.16 图像隐写
3.17 图像增强
3.18 图像重建
4 路径规划方面
4.1 旅行商问题(TSP)
4.1.1 单旅行商问题(TSP)
4.1.2 多旅行商问题(MTSP)
4.2 车辆路径问题(VRP)
4.2.1 车辆路径问题(VRP)
4.2.2 带容量的车辆路径问题(CVRP)
4.2.3 带容量+时间窗+距离车辆路径问题(DCTWVRP)
4.2.4 带容量+距离车辆路径问题(DCVRP)
4.2.5 带距离的车辆路径问题(DVRP)
4.2.6 带充电站+时间窗车辆路径问题(ETWVRP)
4.2.3 带多种容量的车辆路径问题(MCVRP)
4.2.4 带距离的多车辆路径问题(MDVRP)
4.2.5 同时取送货的车辆路径问题(SDVRP)
4.2.6 带时间窗+容量的车辆路径问题(TWCVRP)
4.2.6 带时间窗的车辆路径问题(TWVRP)
4.3 多式联运运输问题
4.4 机器人路径规划
4.4.1 避障路径规划
4.4.2 迷宫路径规划
4.4.3 栅格地图路径规划
4.5 配送路径规划
4.5.1 冷链配送路径规划
4.5.2 外卖配送路径规划
4.5.3 口罩配送路径规划
4.5.4 药品配送路径规划
4.5.5 含充电站配送路径规划
4.5.6 连锁超市配送路径规划
4.5.7 车辆协同无人机配送路径规划
4.6 无人机路径规划
4.6.1 飞行器仿真
4.6.2 无人机飞行作业
4.6.3 无人机轨迹跟踪
4.6.4 无人机集群仿真
4.6.5 无人机三维路径规划
4.6.6 无人机编队
4.6.7 无人机协同任务
4.6.8 无人机任务分配
5 语音处理
5.1 语音情感识别
5.2 声源定位
5.3 特征提取
5.4 语音编码
5.5 语音处理
5.6 语音分离
5.7 语音分析
5.8 语音合成
5.9 语音加密
5.10 语音去噪
5.11 语音识别
5.12 语音压缩
5.13 语音隐藏
6 元胞自动机方面
6.1 元胞自动机病毒仿真
6.2 元胞自动机城市规划
6.3 元胞自动机交通流
6.4 元胞自动机气体
6.5 元胞自动机人员疏散
6.6 元胞自动机森林火灾
6.7 元胞自动机生命游戏
7 信号处理方面
7.1 故障信号诊断分析
7.1.1 齿轮损伤识别
7.1.2 异步电机转子断条故障诊断
7.1.3 滚动体内外圈故障诊断分析
7.1.4 电机故障诊断分析
7.1.5 轴承故障诊断分析
7.1.6 齿轮箱故障诊断分析
7.1.7 三相逆变器故障诊断分析
7.1.8 柴油机故障诊断
7.2 雷达通信
7.2.1 FMCW仿真
7.2.2 GPS抗干扰
7.2.3 雷达LFM
7.2.4 雷达MIMO
7.2.5 雷达测角
7.2.6 雷达成像
7.2.7 雷达定位
7.2.8 雷达回波
7.2.9 雷达检测
7.2.10 雷达数字信号处理
7.2.11 雷达通信
7.2.12 雷达相控阵
7.2.13 雷达信号分析
7.2.14 雷达预警
7.2.15 雷达脉冲压缩
7.2.16 天线方向图
7.2.17 雷达杂波仿真
7.3 生物电信号
7.3.1 肌电信号EMG
7.3.2 脑电信号EEG
7.3.3 心电信号ECG
7.3.4 心脏仿真
7.4 通信系统
7.4.1 DOA估计
7.4.2 LEACH协议
7.4.3 编码译码
7.4.4 变分模态分解
7.4.5 超宽带仿真
7.4.6 多径衰落仿真
7.4.7 蜂窝网络
7.4.8 管道泄漏
7.4.9 经验模态分解
7.4.10 滤波器设计
7.4.11 模拟信号传输
7.4.12 模拟信号调制
7.4.13 数字基带信号
7.4.14 数字信道
7.4.15 数字信号处理
7.4.16 数字信号传输
7.4.17 数字信号去噪
7.4.18 水声通信
7.4.19 通信仿真
7.4.20 无线传输
7.4.21 误码率仿真
7.4.22 现代通信
7.4.23 信道估计
7.4.24 信号检测
7.4.25 信号融合
7.4.26 信号识别
7.4.27 压缩感知
7.4.28 噪声仿真
7.4.29 噪声干扰
7.5 无人机通信
7.6 无线传感器定位及布局方面
7.6.1 WSN定位
7.6.2 高度预估
7.6.3 滤波跟踪
7.6.4 目标定位
7.6.4.1 Dv-Hop定位
7.6.4.2 RSSI定位
7.6.4.3 智能算法优化定位
7.6.5 组合导航
8 电力系统方面
微电网优化、无功优化、配电网重构、储能配置















 2948
2948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









