







一、BP神经网络的概念
BP神经网络是一种多层的前馈神经网络,其主要的特点是:信号是前向传播的,而误差是反向传播的。具体来说,对于如下的只含一个隐层的神经网络模型:
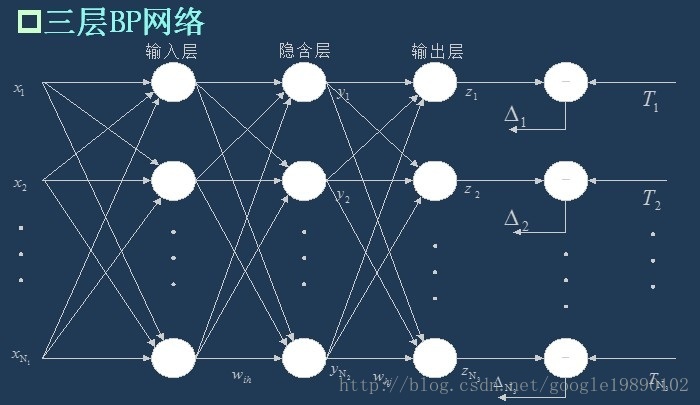
(三层BP神经网络模型)
BP神经网络的过程主要分为两个阶段,第一阶段是信号的前向传播,从输入层经过隐含层,最后到达输出层;第二阶段是误差的反向传播,从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。
二、BP神经网络的流程
在知道了BP神经网络的特点后,我们需要依据信号的前向传播和误差的反向传播来构建整个网络。
1、网络的初始化
假设输入层的节点个数为 ,隐含层的节点个数为
,隐含层的节点个数为 ,输出层的节点个数为
,输出层的节点个数为 。输入层到隐含层的权重
。输入层到隐含层的权重 ,隐含层到输出层的权重为
,隐含层到输出层的权重为 ,输入层到隐含层的偏置为
,输入层到隐含层的偏置为 ,隐含层到输出层的偏置为
,隐含层到输出层的偏置为 。学习速率为
。学习速率为 ,激励函数为
,激励函数为") 。其中激励函数为取Sigmoid函数。形式为:
。其中激励函数为取Sigmoid函数。形式为:
,隐含层的节点个数为,输出层的节点个数为。输入层到隐含层的权重,隐含层到输出层的权重为,输入层到隐含层的偏置为,隐含层到输出层的偏置为。学习速率为,激励函数为。其中激励函数为取Sigmoid函数。形式为:=\frac{1}{1+e^{-x}}")
2、隐含层的输出
如上面的三层BP网络所示,隐含层的输出 为
为
为
")
3、输出层的输出
4、误差的计算
我们取误差公式为:
^2")
其中 为期望输出。我们记
为期望输出。我们记 ,则
,则 可以表示为
可以表示为
为期望输出。我们记,则可以表示为

以上公式中, ,
, ,
, 。
。
,,。
5、权值的更新
权值的更新公式为:
这里需要解释一下公式的由来:
这是误差反向传播的过程,我们的目标是使得误差函数达到最小值,即 ,我们使用梯度下降法:
,我们使用梯度下降法:
- 隐含层到输出层的权重更新
\left ( -\frac{\partial O_k}{\partial w_{jk}} \right )=\left ( Y_k-O_k \right )\left ( -H_j \right )=-e_kH_j")
则权重的更新公式为:
- 输入层到隐含层的权重更新

其中
则权重的更新公式为:
6、偏置的更新
偏置的更新公式为:
- 隐含层到输出层的偏置更新
\left ( -\frac{\partial O_k}{\partial b_k} \right )=-e_k")
则偏置的更新公式为:

- 输入层到隐含层的偏置更新

其中
则偏置的更新公式为:
7、判断算法迭代是否结束
有很多的方法可以判断算法是否已经收敛,常见的有指定迭代的代数,判断相邻的两次误差之间的差别是否小于指定的值等等。
代码
主程序
//将三位二进制数转为一位十进制数
#include <stdio.h>
#include <iostream>
#include <cmath>
#include <cstdlib>
using namespace std;
#define innode 4 //输入结点数
#define hidenode 100 //隐含结点数
#define outnode 1 //输出结点数
#define trainsample 8 //BP训练样本数
class BpNet
{
public:
void train(double p[trainsample][innode], double t[trainsample][outnode]); //Bp训练
double p[trainsample][innode]; //输入的样本
double t[trainsample][outnode]; //样本要输出的
double *recognize(double *p); //Bp识别
void writetrain(); //写训练完的权值
void readtrain(); //读训练好的权值,这使的不用每次去训练了,只要把训练最好的权值存下来就OK
BpNet();
virtual ~BpNet();
public:
void init();
double w[innode][hidenode]; //隐含结点权值
double w1[hidenode][outnode]; //输出结点权值
double b1[hidenode]; //隐含结点阀值
double b2[outnode]; //输出结点阀值
double rate_w; //权值学习率(输入层-隐含层)
double rate_w1; //权值学习率 (隐含层-输出层)
double rate_b1; //隐含层阀值学习率
double rate_b2; //输出层阀值学习率
double e; //误差计算
double error; //允许的最大误差
double result[outnode]; // Bp输出
};
BpNet::BpNet()
{
error = 1.0;
e = 0.0;
rate_w = 0.9; //权值学习率(输入层--隐含层)
rate_w1 = 0.9; //权值学习率 (隐含层--输出层)
rate_b1 = 0.9; //隐含层阀值学习率
rate_b2 = 0.9; //输出层阀值学习率
}
BpNet::~BpNet()
{
}
void winit(double w[], int n) //权值初始化
{
for (int i = 0; i < n; i++)
w[i] = (2.0 * (double)rand() / RAND_MAX) - 1;
}
void BpNet::init()
{
winit((double *)w, innode * hidenode);
winit((double *)w1, hidenode * outnode);
winit(b1, hidenode);
winit(b2, outnode);
}
void BpNet::train(double p[trainsample][innode], double t[trainsample][outnode])
{
double pp[hidenode]; //隐含结点的校正误差
double qq[outnode]; //希望输出值与实际输出值的偏差
double yd[outnode]; //希望输出值
double x[innode]; //输入向量
double x1[hidenode]; //隐含结点状态值
double x2[outnode]; //输出结点状态值
double o1[hidenode]; //隐含层激活值
double o2[hidenode]; //输出层激活值
for (int isamp = 0; isamp < trainsample; isamp++) //循环训练一次样品
{
for (int i = 0; i < innode; i++)
x[i] = p[isamp][i]; //输入的样本
for (int i = 0; i < outnode; i++)
yd[i] = t[isamp][i]; //期望输出的样本
//构造每个样品的输入和输出标准
for (int j = 0; j < hidenode; j++)
{
o1[j] = 0.0;
for (int i = 0; i < innode; i++)
o1[j] = o1[j] + w[i][j] * x[i]; //隐含层各单元输入激活值
x1[j] = 1.0 / (1 + exp(-o1[j] - b1[j])); //隐含层各单元的输出
// if(o1[j]+b1[j]>0) x1[j]=1;
//else x1[j]=0;
}
for (int k = 0; k < outnode; k++)
{
o2[k] = 0.0;
for (int j = 0; j < hidenode; j++)
o2[k] = o2[k] + w1[j][k] * x1[j]; //输出层各单元输入激活值
x2[k] = 1.0 / (1.0 + exp(-o2[k] - b2[k])); //输出层各单元输出
// if(o2[k]+b2[k]>0) x2[k]=1;
// else x2[k]=0;
}
for (int k = 0; k < outnode; k++)
{
qq[k] = (yd[k] - x2[k]) * x2[k] * (1 - x2[k]); //希望输出与实际输出的偏差
for (int j = 0; j < hidenode; j++)
w1[j][k] += rate_w1 * qq[k] * x1[j]; //下一次的隐含层和输出层之间的新连接权
}
for (int j = 0; j < hidenode; j++)
{
pp[j] = 0.0;
for (int k = 0; k < outnode; k++)
pp[j] = pp[j] + qq[k] * w1[j][k];
pp[j] = pp[j] * x1[j] * (1 - x1[j]); //隐含层的校正误差
for (int i = 0; i < innode; i++)
w[i][j] += rate_w * pp[j] * x[i]; //下一次的输入层和隐含层之间的新连接权
}
for (int k = 0; k < outnode; k++)
{
e += fabs(yd[k] - x2[k]) * fabs(yd[k] - x2[k]); //计算均方差
}
error = e / 2.0;
for (int k = 0; k < outnode; k++)
b2[k] = b2[k] + rate_b2 * qq[k]; //下一次的隐含层和输出层之间的新阈值
for (int j = 0; j < hidenode; j++)
b1[j] = b1[j] + rate_b1 * pp[j]; //下一次的输入层和隐含层之间的新阈值
}
}
double *BpNet::recognize(double *p)
{
double x[innode]; //输入向量
double x1[hidenode]; //隐含结点状态值
double x2[outnode]; //输出结点状态值
double o1[hidenode]; //隐含层激活值
double o2[hidenode]; //输出层激活值
for (int i = 0; i < innode; i++)
x[i] = p[i];
for (int j = 0; j < hidenode; j++)
{
o1[j] = 0.0;
for (int i = 0; i < innode; i++)
o1[j] = o1[j] + w[i][j] * x[i]; //隐含层各单元激活值
x1[j] = 1.0 / (1.0 + exp(-o1[j] - b1[j])); //隐含层各单元输出
//if(o1[j]+b1[j]>0) x1[j]=1;
// else x1[j]=0;
}
for (int k = 0; k < outnode; k++)
{
o2[k] = 0.0;
for (int j = 0; j < hidenode; j++)
o2[k] = o2[k] + w1[j][k] * x1[j]; //输出层各单元激活值
x2[k] = 1.0 / (1.0 + exp(-o2[k] - b2[k])); //输出层各单元输出
//if(o2[k]+b2[k]>0) x2[k]=1;
//else x2[k]=0;
}
for (int k = 0; k < outnode; k++)
{
result[k] = x2[k];
}
return result;
}
void BpNet::writetrain()
{
FILE *stream0;
FILE *stream1;
FILE *stream2;
FILE *stream3;
int i, j;
//隐含结点权值写入
if ((stream0 = fopen("w.txt", "w+")) == NULL)
{
cout << "创建文件失败!";
exit(1);
}
for (i = 0; i < innode; i++)
{
for (j = 0; j < hidenode; j++)
{
fprintf(stream0, "%f\n", w[i][j]);
}
}
fclose(stream0);
//输出结点权值写入
if ((stream1 = fopen("w1.txt", "w+")) == NULL)
{
cout << "创建文件失败!";
exit(1);
}
for (i = 0; i < hidenode; i++)
{
for (j = 0; j < outnode; j++)
{
fprintf(stream1, "%f\n", w1[i][j]);
}
}
fclose(stream1);
//隐含结点阀值写入
if ((stream2 = fopen("b1.txt", "w+")) == NULL)
{
cout << "创建文件失败!";
exit(1);
}
for (i = 0; i < hidenode; i++)
fprintf(stream2, "%f\n", b1[i]);
fclose(stream2);
//输出结点阀值写入
if ((stream3 = fopen("b2.txt", "w+")) == NULL)
{
cout << "创建文件失败!";
exit(1);
}
for (i = 0; i < outnode; i++)
fprintf(stream3, "%f\n", b2[i]);
fclose(stream3);
}
void BpNet::readtrain()
{
FILE *stream0;
FILE *stream1;
FILE *stream2;
FILE *stream3;
int i, j;
//隐含结点权值读出
if ((stream0 = fopen("w.txt", "r")) == NULL)
{
cout << "打开文件失败!";
exit(1);
}
float wx[innode][hidenode];
for (i = 0; i < innode; i++)
{
for (j = 0; j < hidenode; j++)
{
fscanf(stream0, "%f", &wx[i][j]);
w[i][j] = wx[i][j];
}
}
fclose(stream0);
//输出结点权值读出
if ((stream1 = fopen("w1.txt", "r")) == NULL)
{
cout << "打开文件失败!";
exit(1);
}
float wx1[hidenode][outnode];
for (i = 0; i < hidenode; i++)
{
for (j = 0; j < outnode; j++)
{
fscanf(stream1, "%f", &wx1[i][j]);
w1[i][j] = wx1[i][j];
}
}
fclose(stream1);
//隐含结点阀值读出
if ((stream2 = fopen("b1.txt", "r")) == NULL)
{
cout << "打开文件失败!";
exit(1);
}
float xb1[hidenode];
for (i = 0; i < hidenode; i++)
{
fscanf(stream2, "%f", &xb1[i]);
b1[i] = xb1[i];
}
fclose(stream2);
//输出结点阀值读出
if ((stream3 = fopen("b2.txt", "r")) == NULL)
{
cout << "打开文件失败!";
exit(1);
}
float xb2[outnode];
for (i = 0; i < outnode; i++)
{
fscanf(stream3, "%f", &xb2[i]);
b2[i] = xb2[i];
}
fclose(stream3);
}
//输入样本
double X[trainsample][innode] = {
{0, 0, 6, 1}, {0, 0, 2, 1}, {1, 0, 1, 4}, {1, 2, 0, 1}, {1, 0, 20, 0}, {0, 0, 1, 5}, {1, 0, 1, 0}, {1, 0, 1, 1}};
//期望输出样本
double Y[trainsample][outnode] = {
{0}, {0.1}, {0.2}, {0.3}, {0.4}, {0.25}, {0.15}, {0.19}};
int main()
{
BpNet bp;
bp.init();
int times = 0;
while (bp.error > 0.00007)
{
bp.e = 0.0;
times++;
bp.train(X, Y);
cout << "Times=" << times << " error=" << bp.error << endl;
}
bp.writetrain();
cout << "trainning complete..." << endl;
double m[innode] = {1, 0, 1, 4};
double *r = bp.recognize(m);
for (int i = 0; i < outnode; ++i)
cout << bp.result[i] << " \nMax: \n";
double cha[trainsample][outnode];
double mi = 100;
double index;
for (int i = 0; i < trainsample; i++)
{
for (int j = 0; j < outnode; j++)
{
//找差值最小的那个样本
cha[i][j] = (double)(fabs(Y[i][j] - bp.result[j]));
if (cha[i][j] < mi)
{
mi = cha[i][j];
index = i;
}
}
}
for (int i = 0; i < innode; ++i)
cout << m[i];
cout << " is " << index << endl;
cout << endl;
return 0;
}















 2124
2124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









