






 本文详细探讨了文本相似度的三种方法:基于字符串、基于语料库和基于知识的相似性。介绍了包括最长公共子串、Damerau-Levenshtein、余弦相似度等在内的14种基于字符串的算法,以及HAL、LSA、WordNet等基于语料库和知识的相似度度量。这些方法广泛应用于信息检索、文档聚类等任务。
本文详细探讨了文本相似度的三种方法:基于字符串、基于语料库和基于知识的相似性。介绍了包括最长公共子串、Damerau-Levenshtein、余弦相似度等在内的14种基于字符串的算法,以及HAL、LSA、WordNet等基于语料库和知识的相似度度量。这些方法广泛应用于信息检索、文档聚类等任务。
文章地址:https://research.ijcaonline.org/volume68/number13/pxc3887118.pdf
文章标题:A Survey of Text Similarity Approaches(文本相似性方法的调查)2013
ABSTRACT
在信息检索、文档聚类、词义消歧、自动作文评分、简答题评分、机器翻译和文本摘要等各种任务中,测量单词、句子、段落和文档之间的相似性是一个重要的组成部分。本文将现有的文本相似度研究分为三种方法:基于字符串、基于语料库和基于知识的相似性。此外,还提供了这些相似性的组合样本。
一、INTRODUCTION
文本相似度指标在文本检索、文本分类、文档聚类、主题检测、主题跟踪、问题生成、问题回答、文章评分、简短回答评分、机器翻译、文本摘要等任务中的研究和应用越来越重要。词与词之间的相似性是文本相似性的重要组成部分,它是句子、段落和文档相似性的基础。词语在词汇和语义上有两种相似之处。如果单词具有相似的字符序列,那么它们在词汇上是相似的。如果它们有相同的事物,它们在语义上是相似的,它们是彼此相对的,以相同的方式使用,在相同的上下文中使用,一个是另一个的类型。本研究通过不同的基于字符串的算法引入词汇相似度,通过基于语料库和基于知识的算法引入语义相似度。基于字符串的度量操作在字符串序列和字符组合上。字符串度量是度量两个文本字符串之间的相似度或不相似度(距离)以进行近似字符串匹配或比较的度量。基于语料库的相似度是根据从大型语料库中获取的信息来确定词汇间相似度的一种语义相似度度量方法。基于知识的相似度是一种语义相似度度量方法,它利用来自语义网络的信息来确定单词之间的相似度。每种类型中最受欢迎的将简要介绍。
本文的组织结构如下:第二部分提出了基于字符串的算法,并将其分为基于字符和基于术语的两种度量方法。第三部分和第四部分分别介绍了基于语料库和基于知识的算法。第五部分介绍了相似算法的组合样本,第六部分给出了调查的结论。
二、String-Based Similarity(基于字符串的相似度)

图一:基于字符串的相似的度量
字符串相似性度量对字符串序列和字符组合进行操作。字符串度量是度量两个文本字符串之间的相似度或不相似度(距离)以进行近似字符串匹配或比较的度量。
这个调查代表了在SimMetrics包[1]中实现的最流行的字符串相似性度量。如图1所示,将简要介绍14种算法;其中七个是基于字符的,而其他是基于术语的距离测量。
2.1 Character-Based Similarity Measures(基于字符的相似方法)
最长公共子串(LCS) 算法考虑两个字符串之间的相似性是基于两个字符串中存在的连续字符链的长度。
Damerau-Levenshtein通过计算将一个字符串转换为另一个字符串所需的最少操作数来定义两个字符串之间的距离,其中一个操作被定义为单个字符的插入、删除或替换,或两个相邻字符的换位[2,3]。
Jaro是基于两个字符串之间的公共字符的数量和顺序;它考虑了典型的拼写偏差,主要用于记录链接区域。(4、5)。
Jaro-winkler是Jaro距离的延伸;它使用一个前缀标度,为从一开始就匹配的字符串提供更有利的评级,以确定前缀长度[6]。
Needleman-Wunsch算法是动态规划的一个例子,是动态规划在生物序列比较中的第一个应用。它执行全局比对,以找到两个序列的最佳比对。当两个序列长度相似,且整个[7]具有显著的相似度时,该方法是适用的。
Smith-Waterman是动态编程的另一个例子。通过局部比对,找出两个序列保守域上的最佳比对。它对于不相似的序列是有用的,这些序列被怀疑在较大的序列上下文[8]中包含相似区域或相似的序列基序。
n-gram是给定文本序列中n个项目的子序列。n-gram相似算法比较两个字符串中每个字符或单词的n-gram。计算距离的方法是用相似的n-gram数除以最大的n-gram[9]。
2.2 Term-based Similarity Measures(基于词汇的相似的措施)
Block Distance又称曼哈顿距离、车厢距离、绝对值距离、L1距离、街区距离、曼哈顿距离。它计算如果遵循类似网格的路径,从一个数据点到另一个数据点所需走过的距离。两项之间的块距离为其对应分量[10]的差值之和。
余弦相似度是内积空间中两个向量之间的相似度的度量,度量的是它们夹角的余弦值。
Dice的系数定义为比较字符串中通用项数的两倍除以两个字符串[11]中的总项数。
欧氏距离或L2距离是两个向量对应元素差的平方和的平方根。
Jaccard相似度的计算方法是:两个字符串[12]中共享项的数量除以所有唯一项的数量。
匹配系数是一种非常简单的基于向量的方法,它简单地计算相似项(维数)的数量,在这些项上两个向量都是非零的。
重叠系数类似于骰子的系数,但如果一个字符串是另一个字符串的子集,则认为两个字符串完全匹配。
三、Corpus-Based Similarity(基于语料库的相似性)
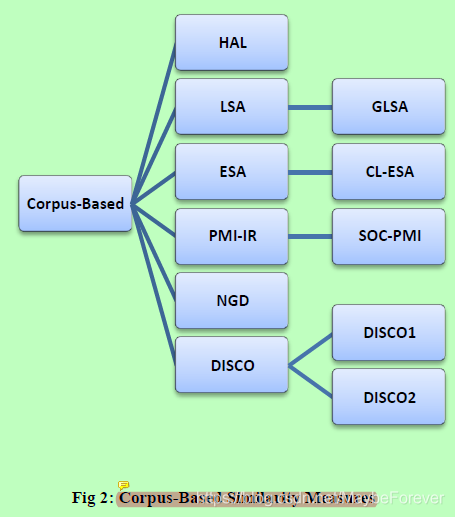
图二:基于语料库的相似性措施
基于语料库的相似度是根据从大型语料库中获取的信息来确定词汇间相似度的一种语义相似度度量方法。语料库是用于语言研究的大量书面或口头文本的集合。图2显示了基于语料库的相似性度量。
超空间模拟语言(HAL)[13,14]通过单词的共现创造了一个语义空间。每个矩阵元素是由行表示的单词与列表示的单词之间的关联强度组成的逐词矩阵。然后,算法的用户可以选择从矩阵中删除低熵列。当文本被分析时,一个焦点词被放置在一个10个单词的窗口的开头,该窗口记录哪些相邻的单词被统计为共现词。矩阵值是通过对与焦点词的距离成反比的共现矩阵加权来累积的;相邻词被认为更能反映焦点词的语义,因此权重更高。HAL还通过根据相邻词出现在焦点词之前还是之后而对同现词进行不同处理来记录单词排序信息。
潜在语义分析(LSA)[15]是目前最流行的基于语料库的相似性分析技术。LSA假设意思相近的单词会出现在相似的文本中。一个包含每个段落字数的矩阵(行表示唯一的单词,列表示每个段落)是由一大段文本构成的,并且使用一种称为奇异值分解(SVD)的数学技术来减少列的数量,同时保持行之间的相似性结构。然后通过取任意两行向量夹角的余弦值来比较单词。
广义潜在语义分析(GLSA)[16]是一种基于语义的术语和文档向量计算框架。它通过关注术语向量而不是双文档术语表示来扩展LSA方法。GLSA要求对术语之间的语义关联进行度量,并采用降维方法。GLSA方法可以将任何项空间上的相似度度量与任何合适的降维方法相结合。最后一步使用传统的term文档矩阵来提供term向量的线性组合中的权值。
显式语义分析(ESA)[17]是一种计算任意文本之间语义关联的方法。基于维基百科的技术将术语(或文本)表示为高维向量;每个向量条目表示该术语和一篇Wikipedia文章之间的TF-IDF权重。两个术语(或文本)之间的语义关联通过对应向量之间的余弦测度来表示。
跨语言显式语义分析(CL-ESA)[18]是ESA的多语言泛化。CL-ESA利用文档对齐的多语言引用集合(如Wikipedia)将文档表示为与语言无关的概念向量。通过对应向量表示之间的余弦相似度来评估不同语言中两个文档的相关性。
点对点互信息检索(PMI-IR)[19]是一种计算单词对之间相似性的方法,它使用AltaVista的高级搜索查询语法来计算概率。两个单词在网页上同时出现的频率越高,它们的PMI-IR相似度得分就越高。
二阶共现点对点互信息(sco-pmi)[20,21]是一种语义相似度度量方法,利用点对点互信息对一个大型语料库中两个目标词的重要相邻词进行排序。使用soci - pmi的优点是,它可以计算两个不经常同时出现的单词之间的相似性,因为它们与相同的相邻单词同时出现。
归一化谷歌距离(NGD)[22]是一种语义相似度度量,由谷歌搜索引擎对给定的一组关键字返回的命中次数得出。在自然语义学意义上相同或相近的关键字。具体而言,两个搜索项x和y之间的归一化谷歌距离为:
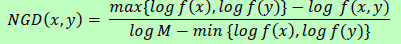
其中M为谷歌所搜索的网页总数;f(x)和f(y)分别是搜索项x和y的搜索次数;f(x, y)是同时出现x和y的网页数量。如果两个搜索项x和y从未同时出现在同一个web页面上,而是单独出现,那么它们之间的规范化谷歌距离是无限的。如果这两项总是同时出现,它们的NGD等于0,或者等于x²和y²之间的系数。
使用单词间的共现(DISCO)提取分布相似的单词[23,24]。对大量的文本集合进行统计分析,得到分布相似度。DISCO是一种通过使用大小±3个单词的简单上下文窗口计算单词间分布相似性的方法。当对两个词进行精确相似度检索时,只从索引数据中检索它们的词向量,并根据Lin度量[25]计算相似度。如果需要分布最相似的单词;DISCO返回给定单词的二阶单词向量。迪斯科有两个主要的相似度测量指标:迪斯科1和迪斯科2;根据两个输入词的搭配集计算它们之间的一阶相似度。根据两个输入词的分布相似词集计算它们之间的二阶相似度。
四、Knowledge-Based Similarity(基于知识的相似度)
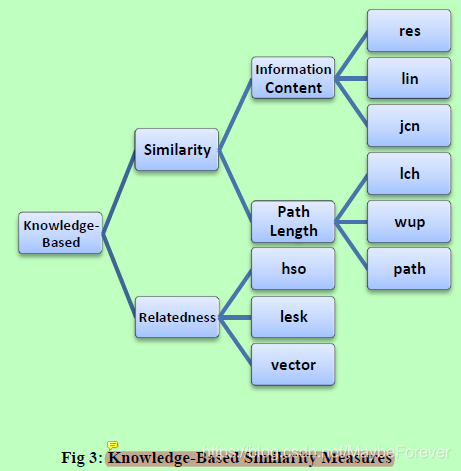
图三:基于知识的相似度度量
基于知识的相似度是基于从语义网络[26]中提取的信息来识别词间相似度的一种语义相似度度量方法。WordNet[27]是目前最流行的基于知识的词间相似性度量语义网络;WordNet是一个大型的英语词汇数据库。名词、动词、形容词和副词被分成一系列认知同义词(synsets),每一个都表示一个不同的概念。Synsets通过概念-语义和词汇关系相互联系。
如图3所示,基于知识的相似性度量可以大致分为两组:语义相似性度量和语义关联度量。语义上相似的概念被认为是基于它们的相似性而联系在一起的。另一方面,语义关联是一个更普遍的概念,与概念的形状或形式无关。换句话说,语义相似是两个词之间的一种联系,它涵盖了概念之间更广泛的关系,包括额外的相似关系,如“是”、“是”、“是”、“不是”。
有六个衡量语义相似度的标准;其中三个是基于信息内容:Resnik (res)[29]、Lin (Lin)[25]和Jiang & Conrath (jcn)[30]。其他三个测量是基于路径长度:Leacock & Chodorow (lch) [31], Wu & Palmer (wup)[32]和路径长度(path)。
res测度 的相关值等于最小公共包容(信息最丰富的包容)的信息含量(IC)。这意味着该值总是大于或等于零。该值的上限通常非常大,并随用于确定信息内容值的语料库的大小而变化。lin和jcn度量用概念A和概念B本身的信息内容之和来增加最不常见包含者的信息内容。lin测度用这个和来衡量最小公共包容者的信息含量,而jcn用这个和和最小公共包容者的信息含量之差。
lch测度 返回一个分数,表示两个词的感觉有多相似,这个分数基于连接感觉的最短路径和感觉出现的分类的最大深度。wup测量返回一个分数,该分数表示两个词的感觉有多相似,这个分数是基于这两个词在分类法中的深度和它们最不常见的归属者的深度。
path测度 根据连接is-a (hypernym/hypnoym)分类法中各义项的最短路径,返回一个表示两个词的义项相似程度的分数。
此外,还有三种测量语义关联的方法:St.Onge (hso)[33]、Lesk (Lesk)[34]和vector pair (vector)[35]。hso测量的工作原理是找到连接两个词的词义的词汇链。可以考虑三类关系:特强、强和中等强。最大亲缘关系得分为16分。lesk通过在两个synset的注释中找到重叠部分来进行测量。相关度分数是重叠长度的平方和。vector measure为给定文集中WordNet注释中使用的每个单词创建一个共现矩阵,然后用这些共现向量的平均值向量表示每个注释/概念。
最流行的基于知识的相似性度量包是WordNet::Similarity1和Natural Language Toolkit (NLTK)2。
五、Hybrid Similarity Measures(混合相似性度量)
混合方法使用多个相似度度量。在[26]中测试了8个语义相似度度量。其中两项是基于语料库的测试,另外六项是基于知识的测试。首先分别对这八种算法进行评价,然后将它们结合起来。最佳性能是通过将多个相似度指标组合为一个指标的方法实现的。
摘要提出了一种基于语义和词序信息的句子或极短文本语义相似度的度量方法。首先,语义相似是从词汇知识库和语料库中派生出来的。其次,该方法考虑了词序对句子意义的影响。派生的词序相似度度量不同单词的数量以及不同顺序的单词对数量。
[37]的作者提出了一种方法,并将其命名为语义文本相似度(STS)。这种方法通过语义和句法信息的组合来确定两个文本的相似性。他们考虑了两个强制函数(字符串相似度和语义词相似度)和一个可选函数(共同词序相似度)。STS方法对30组句子对数据集的Pearson相关系数很好,优于[36]的结果。
[38]的作者提出了一种方法,该方法将基于语料库的整个句子的语义相关度测量和基于知识的语义相似度评分结合起来,这些语义相似度评分是针对两个句子中属于相同语法角色的单词获得的。所有作为特征的分数被输入到机器学习模型中,如线性回归和bagging模型,以获得单个分数,给出句子之间的相似度。该方法将基于知识的相似性测度与基于语料库的关联测度相结合,在计算句子间的语义相似度方面取得了显著的进步。
通过结合两个模块,在[39]中实现了人工和自动相似性结果之间的良好相关性。第一个模块使用基于n字图的相似度计算句子之间的相似度,第二个模块使用概念相似度测度和WordNet计算两个句子中概念之间的相似度。
[40]中引入了一个具有合理相关结果的UKP系统,该系统采用基于训练数据的简单对数线性回归模型,将多个文本相似度度量值结合起来。这些度量包括字符串相似度、语义相似度、文本扩展机制以及与结构和风格相关的度量。UKP最终的模型由一个大约20个特征的对数线性组合组成,而这是可能实现的300个特征中的一个。
六、Conclusion
本文讨论了三种文本相似性方法:基于字符串、基于语料库和基于知识的相似性。基于字符串的度量操作在字符串序列和字符组合上。介绍了14种算法:其中七项是基于字符的,而另一项是基于术语的距离测量。基于语料库的相似度是根据从大型语料库中获取的信息来确定词汇间相似度的一种语义相似度度量方法。解释了九种算法:HAL, LSA, GLSA, ESA, CL-ESA, PMI-IR, sc - pmi, NGD和DISCO。基于知识的相似度是一种基于语义网络信息的语义相似度度量方法。介绍了九种算法:其中6个基于语义相似度-res、lin、jcn、lch、wup和path,其他3个基于语义相似度-hso、lesk和vector-。其中一些算法在许多研究中被结合在一起。最后提出了有用的相似度包,如SimMetrics、WordNet:: similarity和NLTK。

















 5688
5688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









