







 本文介绍了Python正则表达式的用途,通过实例演示了如何使用正则表达式从文本中提取薪资信息。讲解了常见正则表达式语法,如点、星号、加号、问号、花括号等,并提供了在线验证工具。还介绍了贪婪模式和非贪婪模式、对元字符的转义、匹配某种字符类型等,并给出了一些实际应用,如字符串切割和替换。
本文介绍了Python正则表达式的用途,通过实例演示了如何使用正则表达式从文本中提取薪资信息。讲解了常见正则表达式语法,如点、星号、加号、问号、花括号等,并提供了在线验证工具。还介绍了贪婪模式和非贪婪模式、对元字符的转义、匹配某种字符类型等,并给出了一些实际应用,如字符串切割和替换。
Python正则表达式
有什么用?
大家看一个例子。
一个文本文件里面存储了 一些市场职位信息,格式如下所示
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
现在,我们需要写一个程序,从这些文本里面抓取 所有职位的薪资。
就是要获取这样的结果
2
2.5
1.3
1.1
2.8
2.5
怎么做?
大家先自己思考一下。
这是典型的字符串处理。
分析这里面的规律,可以发现,薪资的数字 后面 都有关键字 万/月 或者 万/每月
根据我们学过的知识,我们不难写出下面的代码
content = '''
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
'''
# 将文本内容按行放入列表
lines = content.splitlines()
for line in lines:
# 查找'万/月' 在 字符串中什么地方
pos2 = line.find('万/月')
if pos2 < 0:
# 查找'万/每月' 在 字符串中什么地方
pos2 = line.find('万/每月')
# 都找不到
if pos2 < 0:
continue
# 执行到这里,说明可以找到薪资关键字
# 接下来分析 薪资 数字的起始位置
# 方法是 找到 pos2 前面薪资数字开始的位置
idx = pos2-1
# 只要是数字或者小数点,就继续往前面找
while line[idx].isdigit() or line[idx]=='.':
idx -= 1
# 现在 idx 指向 薪资数字前面的那个字,
# 所以薪资开始的 索引 就是 idx+1
pos1 = idx + 1
print(line[pos1:pos2])
运行一下,发现完全可以。
在你高兴完之后,我们再看看写的代码。
怎么样?
太麻烦了,是不是。
为了从每行获取薪资对应的数字,我们 可是 写了不少行代码。
这种 从字符串中搜索出某种特征的子串 有没有更简单的方法呢?
解决方案就是我们今天要介绍的 正则表达式 。
如果我们使用正则表达式,代码可以这样
content = '''
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
'''
import re
for one in re.findall(r'([\d.]+)万/每{0,1}月', content):
print(one)
运行一下看看,结果是一样的。
但是代码却简单多了。
正则表达式,是一种语法,用来描述你想搜索的字符串的特征。
这里指定了一个正则表达式
re.findall(r'([\d.]+)万/每{0,1}月', content)
([\d.]+)万/每{0,1}月 ,就是正则表达式字符串,指定了 搜索子串的特征。
为什么这么写? 我们后面再介绍。
findall 函数返回所有匹配的子串,放在一个列表中。
从 上面的 例子可以看出, 用正则表达式关键的地方在于, 如何写出正确的表达式语法 。
正则表达式非常强大,语法非常复杂,如果你英文阅读能力还可以,那太好了,点击这里,参考Python官方文档里面的描述 。具体的使用细节包括语法都在里面。
本教程会给大家介绍一些常见的正则表达式语法。
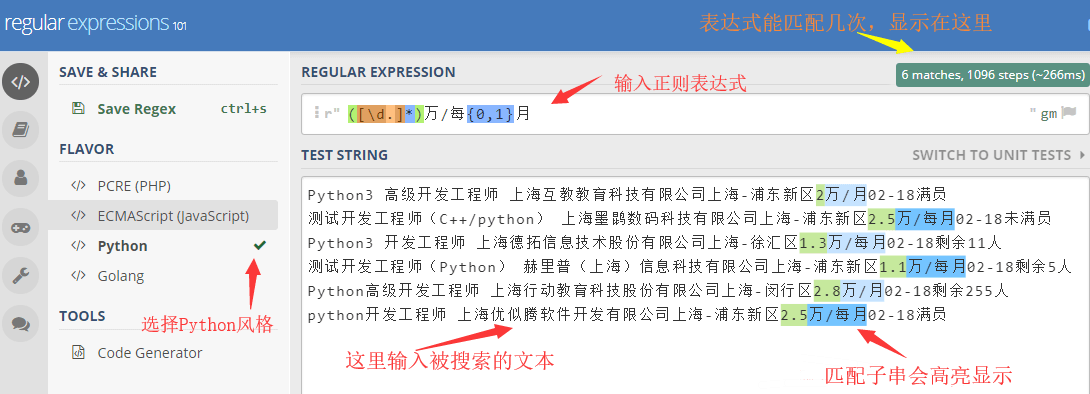
在线验证
怎么验证你写的表达式 是否能正确匹配到要搜索的字符串呢?
大家可以访问这个网址: https://regex101.com/
按照下面的示意图片输入 搜索文本 和 表达式,查看你的表达式是否能正确匹配到字符串。
常见语法
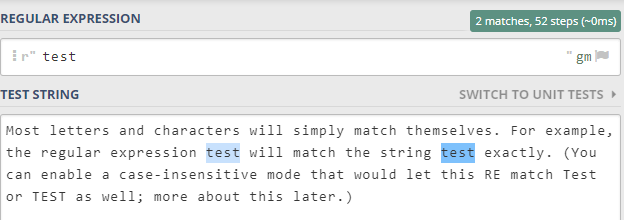
写在正则表达式里面的普通字符都是表示: 直接匹配它们。
比如 你下面的文本中,如果你要找所有的 test, 正则表达式就非常简单,直接输入 test 即可。
如下所示:
汉字也是一样,要寻找汉字,直接写在正则表达式里面就可以了。
但是有些特殊的字符,术语叫 metacharacters(元字符)。
它们出现在正则表达式字符串中,不是表示直接匹配他们, 而是表达一些特别的含义。
这些特殊的元字符包括下面这些:
. * + ? \ [ ] ^ $ { } | ( )
我们分别介绍一下它们的含义:
点-匹配所有字符
. 表示要匹配除了 换行符 之外的任何 单个 字符。
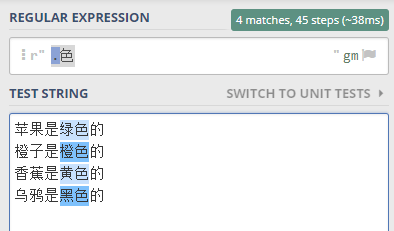
比如,你要从下面的文本中,选择出所有的颜色。
苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
也就是要找到所有 以 色 结尾,并且包括前面的一个字符的 词语。
就可以这样写正则表达式 .色 。
其中 点 代表了任意的一个字符, 注意是一个字符。
.色 合起来就表示 要找 任意一个字符 后面是 色 这个字, 合起来两个字的 字符串
验证一下,如下图所示
只要表达式正确,就可以写在Python代码中,如下所示
content = '''苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的'''
import re
p = re.compile(r'.色')
for one in p.findall(content):
print(one)
运行结果如下
绿色
橙色
黄色
黑色
星号-重复匹配任意次
* 表示匹配前面的子表达式任意次,包括0次。
比如,你要从下面的文本中,选择每行逗号后面的字符串内容,包括逗号本身。注意,这里
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









