一、自定义频率类
方式一:
from rest_framework.throttling import BaseThrottle, SimpleRateThrottle
class MyThrottling(SimpleRateThrottle):
scope = 'luffy'
def get_cache_key(self, request, view):
return request.META.get('REMOTE_ADDR')
'''
返回什么 频率就可以做什么限制
通过用户IP地址进行限制 REMOTE_ADDR
'''
方式二:
class MyThrottling(BaseThrottle):
data_IP = {}
ip = None
def allow_request(self, request, view):
ip = request.META.get('REMOTE_ADDR')
self.ip = ip
if ip not in self.data_IP:
self.data_IP[ip] = []
self.data_IP[ip].append(time.time())
return True
print(self.data_IP)
while True:
if time.time() - self.data_IP[ip][-1] > 60:
self.data_IP[ip].pop()
break
print(self.data_IP)
if len(self.data_IP[ip]) > 3:
return False
else:
self.data_IP[ip].insert(0, time.time())
return True
方式三:
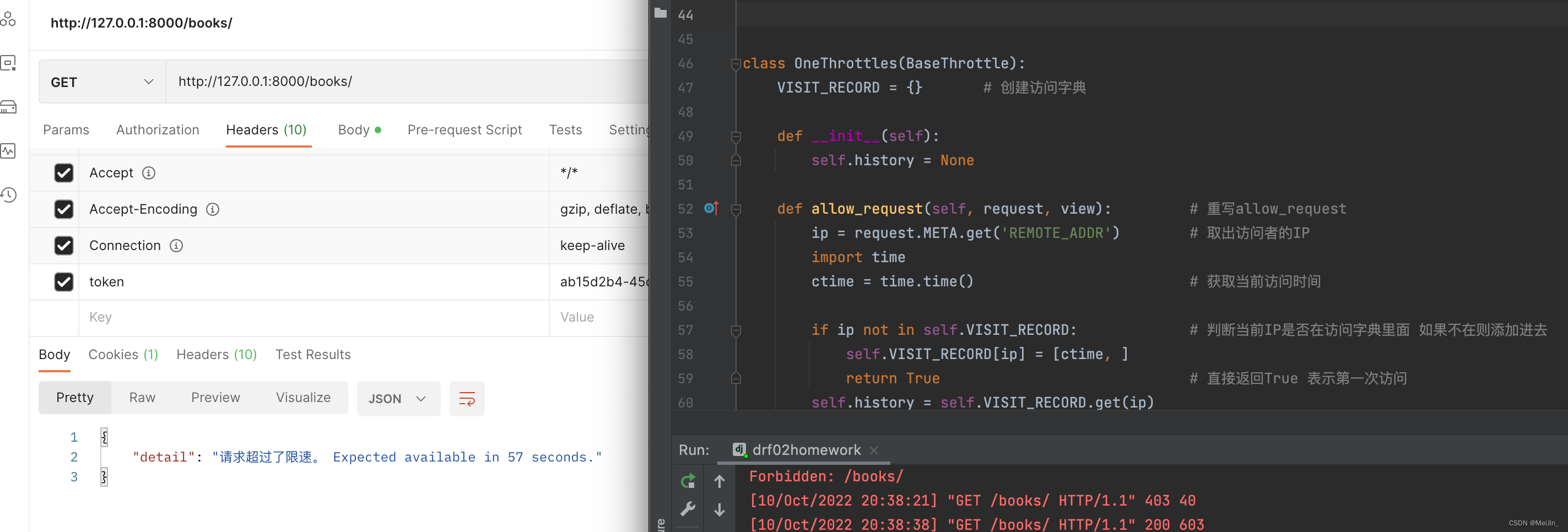
class OneThrottles(BaseThrottle):
VISIT_RECORD = {}
def __init__(self):
self.history = None
def allow_request(self, request, view):
ip = request.META.get('REMOTE_ADDR')
import time
ctime = time.time()
if ip not in self.VISIT_RECORD:
self.VISIT_RECORD[ip] = [ctime, ]
return True
self.history = self.VISIT_RECORD.get(ip)
while self.history and ctime-self.history[-1] > 60:
self.history.pop()
if len(self.history) < 3:
self.history.insert(0, ctime)
return True
else:
return False
def wait(self):
ctime = time.time()
return 60-(ctime-self.history[-1])
二、频率功能源码分析
-源码里执行的频率类的allow_request,读SimpleRateThrottle的allow_request
class SimpleRateThrottle(BaseThrottle):
cache = default_cache
timer = time.time
cache_format = 'throttle_%(scope)s_%(ident)s'
scope = None
THROTTLE_RATES = api_settings.DEFAULT_THROTTLE_RATES
def __init__(self):
if not getattr(self, 'rate', None):
self.rate = self.get_rate()
self.num_requests, self.duration = self.parse_rate(self.rate)
def get_rate(self):
return self.THROTTLE_RATES[self.scope]
def parse_rate(self, rate):
if rate is None:
return (None, None)
num, period = rate.split('/')
num_requests = int(num)
duration = {'s': 1, 'm': 60, 'h': 3600, 'd': 86400}[period[0]]
return (num_requests, duration)
def allow_request(self, request, view):
if self.rate is None:
return True
self.key = self.get_cache_key(request, view)
if self.key is None:
return True
self.history = self.cache.get(self.key, [])
self.now = self.timer()
while self.history and self.history[-1] <= self.now - self.duration:
self.history.pop()
if len(self.history) >= self.num_requests:
return self.throttle_failure()
return self.throttle_success()
三、分页功能
'''
分页功能 首先是查询多条数据一页展示太多 用分页来真是较为美观
分页类型总共有三种 PageNumberPagination, LimitOffsetPagination, CursorPagination
分页的模型类需要继承GenericAPIView+ListModelMixin的子视图类上 否则不能使用
如果继承的是APIView,需要自己写
page = MyPageNumberPagination()
res = page.paginate_queryset(qs, request)
'''
models.py
class Movie(models.Model):
name = models.CharField(max_length=32)
price = models.IntegerField(max_length=32)
author = models.CharField(max_length=32)
page.py
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
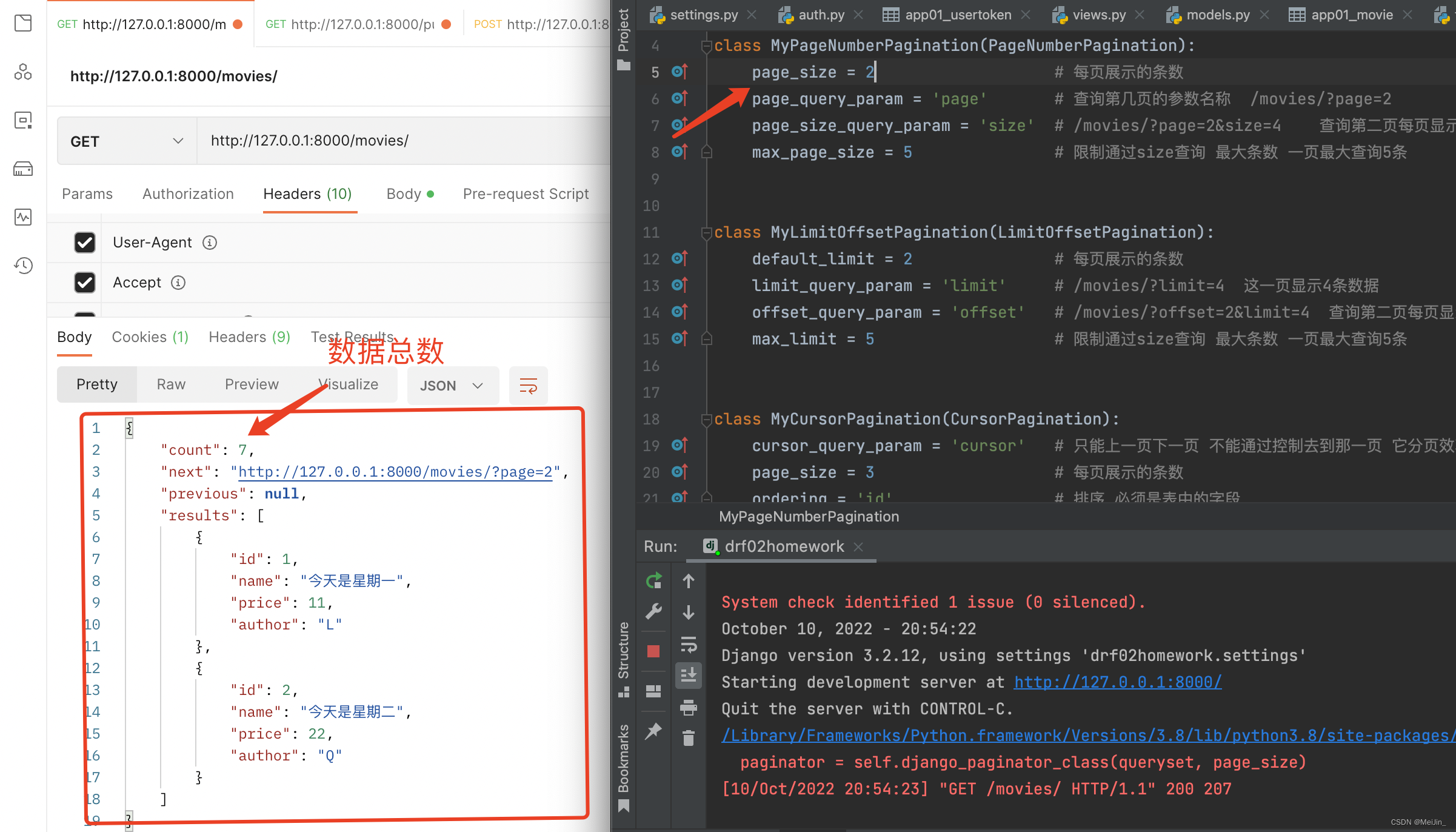
class MyPageNumberPagination(PageNumberPagination):
page_size = 3
page_query_param = 'page'
page_size_query_param = 'size'
max_page_size = 5
class MyLimitOffsetPagination(LimitOffsetPagination):
default_limit = 2
limit_query_param = 'limit'
offset_query_param = 'offset'
max_limit = 5
class MyCursorPagination(CursorPagination):
cursor_query_param = 'cursor'
page_size = 3
ordering = 'id'
view.py
from .page import MyPageNumberPagination, LimitOffsetPagination, CursorPagination
class MovieView(ViewSetMixin, ListAPIView, CreateModelMixin):
pagination_class = MyPageNumberPagination
queryset = Movie.objects.all()
serializer_class = MovieSerializer
四、排序功能
'''
跟分页功能一样 涉及到查询所有才有排序 其他接口都不需要
想使用到排序功能需要导入rest_framework.filter中的 OrderingFilter
排序的模型类需要继承GenericAPIView+ListModelMixin的子视图类上 否则不能使用
如果继承的是APIView,需要自己写 需要自己从请求地址中取出排序规则,自己排序
-'price','-id'=reqeust.query_params.get('ordering').split(',')
-qs = Book.objects.all().order_by('price','-id')
分页和排序可以一起使用 但是是先排序后分页的
'''
views.py
from rest_framework.filters import OrderingFilter, SearchFilter
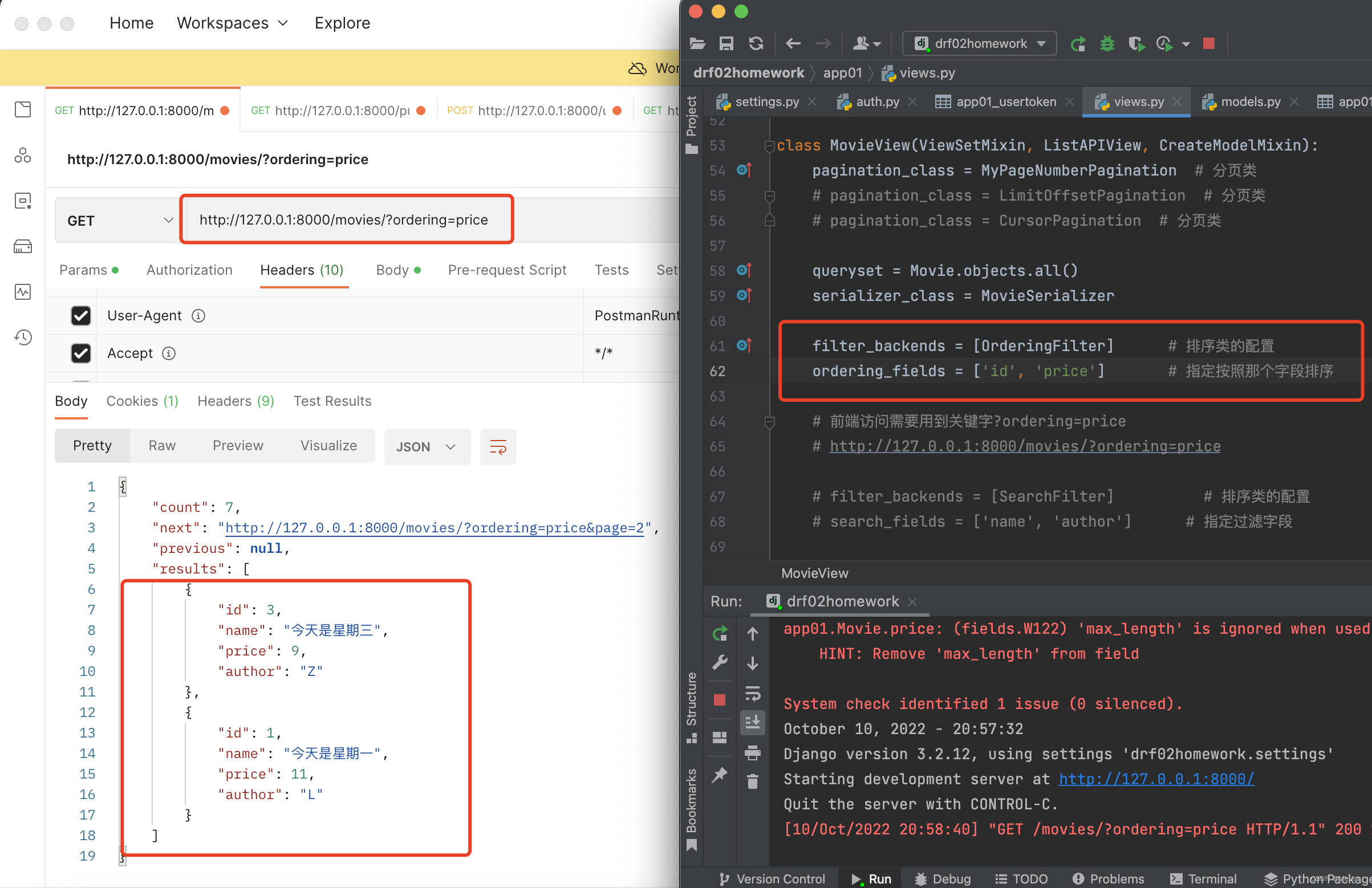
class MovieView(ViewSetMixin, ListAPIView, CreateModelMixin):
pagination_class = MyPageNumberPagination
queryset = Movie.objects.all()
serializer_class = MovieSerializer
filter_backends = [OrderingFilter]
ordering_fields = ['id', 'price']
'''
前端访问需要用到关键字?ordering=price
http://127.0.0.1:8000/movies/?ordering=price
'''
五、过滤功能
'''
跟分页功能一样 涉及到查询所有才有排序 其他接口都不需要
restful规范中有一条 请求地址中带过滤条件:分页、排序、过滤统称为过滤
过滤的模型类需要继承GenericAPIView+ListModelMixin的子视图类上 否则不能使用
'''
views.py
from rest_framework.filters import OrderingFilter, SearchFilter
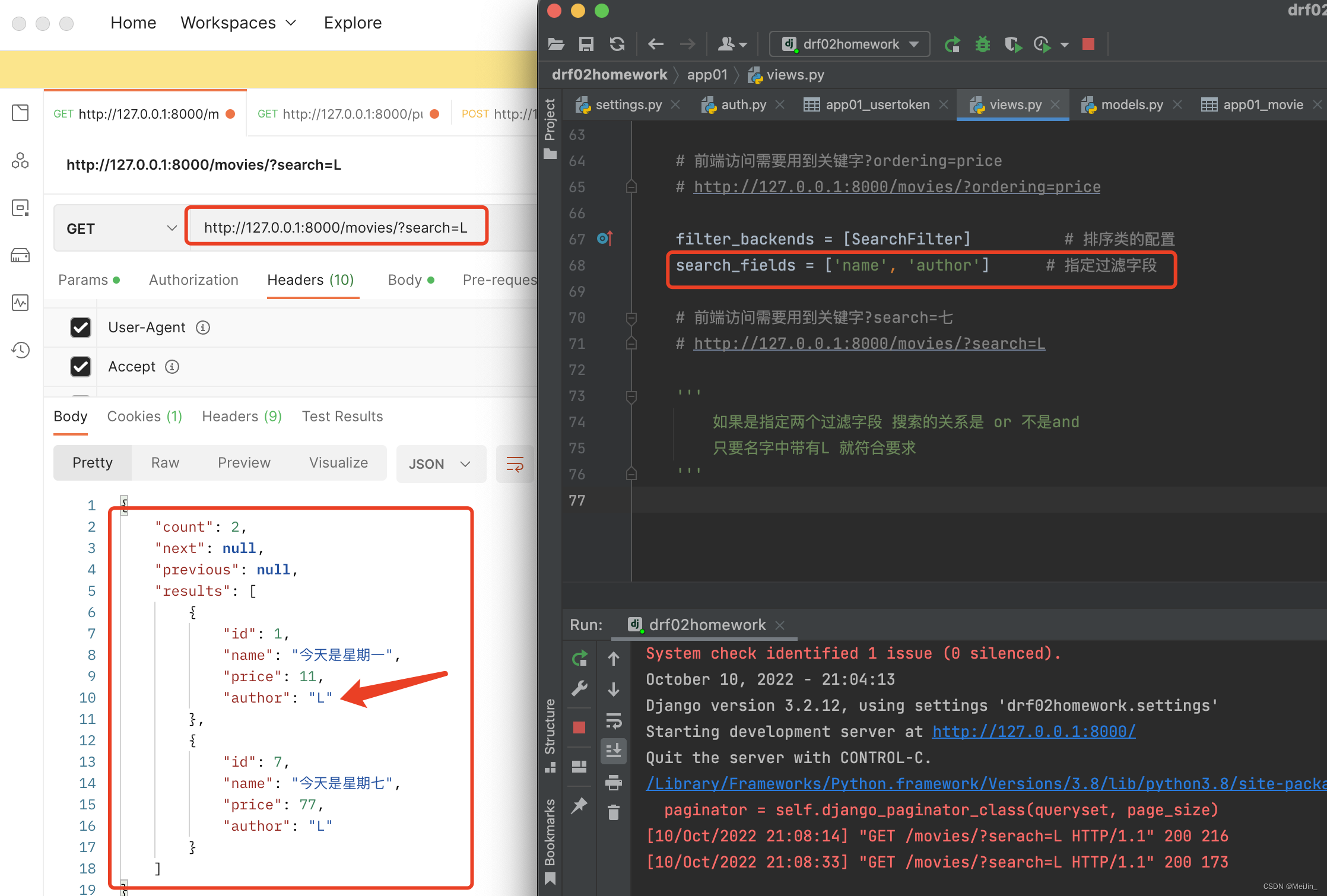
class MovieView(ViewSetMixin, ListAPIView, CreateModelMixin):
pagination_class = MyPageNumberPagination
queryset = Movie.objects.all()
serializer_class = MovieSerializer
filter_backends = [SearchFilter]
search_fields = ['name', 'author']
'''
如果是指定两个过滤字段 搜索的关系是 or 不是and
只要名字中带有L 就符合要求
'''
























 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











