






Logistics回归:极大似然法
对数几率
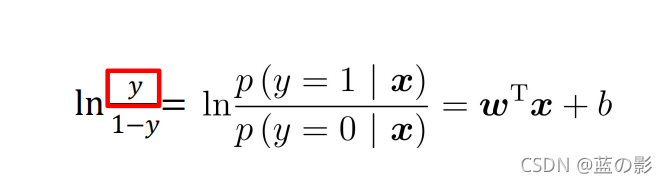
因此有:

Logisitics回归:极大似然法估计recap
确定待求解的未知参数θ1,θ2,……θn,如均值,方差或特定分布函数等
计算每个样本X1 , X2 , . . . , Xn的概率密度 f(Xi; θ1 , . . . , θm).
假定样本i.i.d,则可根据样本的概率密度累乘构造似然函数:
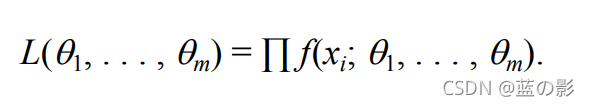
通过似然函数最大化(求导为零),求解未知参数 θ
为降低计算难度,通常可采用对数加法替换概率乘法,通 过导数为零/极大值来求解未知参数
UCI Machine Learning Repository: Breast Cancer Wisconsin (Original) Data Set
数据库借用的康威斯星州乳腺癌的数据集
我将其中的10与8改成了0,增加数据集数据错误率
1.改进的随机梯度上升算法
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
def colicTest():
frTrain = open('breast-cancer-wisconsin.txt'); frTest = open('breast-cancer-wisconsin-train.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split(',')
lineArr =[]
for i in range(10):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[10]))
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split(',')
lineArr =[]
for i in range(10):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[10]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print "the error rate of this test is: %f" % errorRate
return errorRate
def multiTest():
numTests = 10; errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print "after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))输出结果为
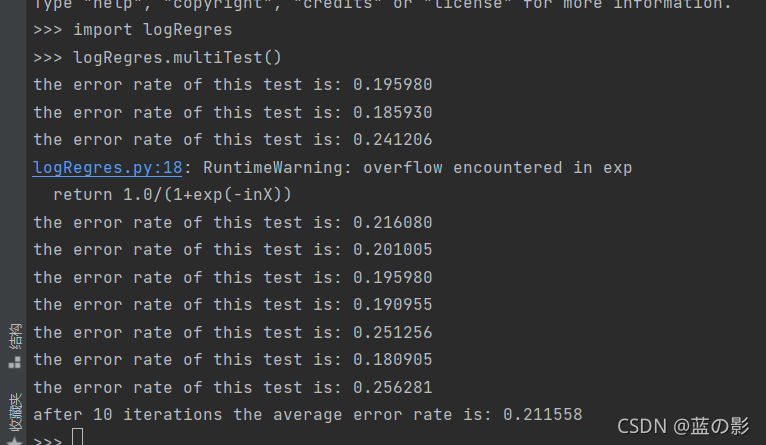
0(即未收集数据)占总数据的百分比约为13%,而利用改进的随机梯度算法错误率仅仅20%,可以说效率非常高
2.随机梯度上升算法
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
利用此算法计算的错误率结果为
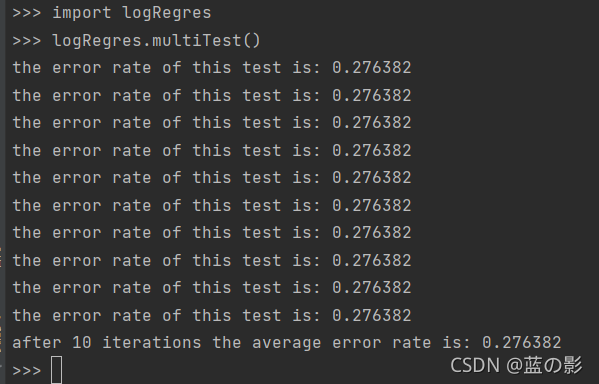
可以看出相比改进的随机梯度上升算法来看,错误率明显提高不少
所以改进的随机梯度上升算法更好















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









