






本文精选了美团技术团队被ACL 2024收录的4篇论文进行解读,论文内容覆盖了训练成本优化、投机解码、代码生成优化、指令微调(IFT)等技术领域。这些论文是美团技术团队跟高校、科研机构合作的成果。希望能给从事相关研究工作的同学带来一些帮助或启发。
ACL是计算语言学和自然语言处理领域最重要的顶级国际会议,由国际计算语言学协会组织,每年举办一次。据谷歌学术计算语言学刊物指标显示,ACL影响力位列第一,是CCF-A类推荐会议。ACL成立于1962年,世界上影响力最大、最具活力的国际学术组织之一,它每年夏天都会召开大会,供学者发布论文,分享最新成果,它的会员来自全球60多个国家和地区,是NLP领域最高级别的国际学术组织,代表了国际计算语言学的最高水平。

活动预告:美团在ACL 2024会场内设有展位(11号),欢迎大家来我们的展位跟论文作者、技术专家进行交流。我们将在8月12日(周一)17: 00进行线上直播和论文分享,欢迎大家预约。
以下内容是4篇论文的解读:
01
Speculative Decoding via Early-exiting for Faster LLM Inference with Thompson Sampling Control Mechanism
论文类型:Long Paper
论文下载:PDF
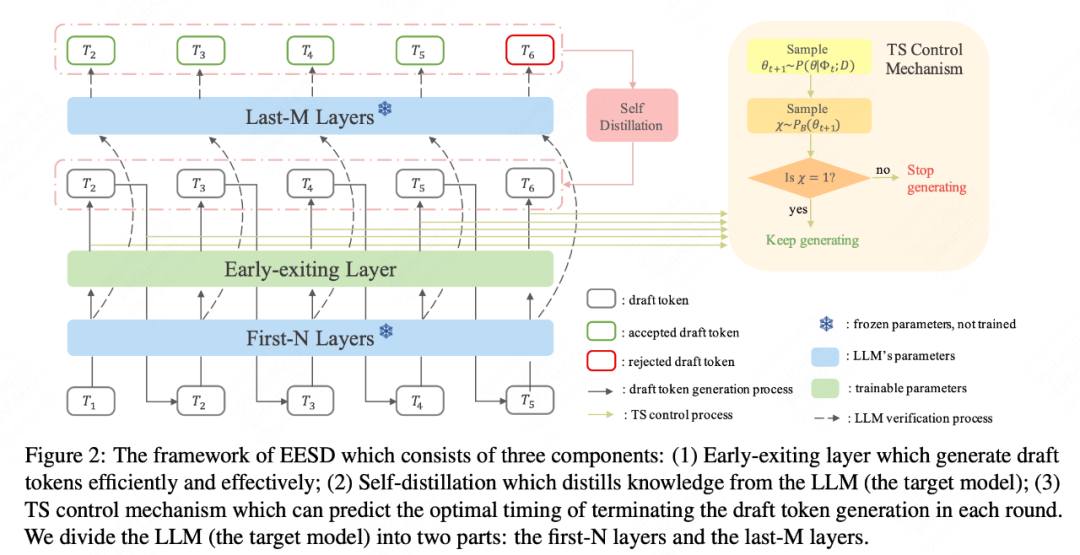
论文简介:近期,大型语言模型(LLMs)的发展突飞猛进,随之而来的就是推理成本上涨,这已经成为实际应用中较大的一个挑战。为了应对这些挑战,我们提出了一种名为「早期退出投机解码(EESD)」的全新方法,该方法实现了无损加速。
具体而言,EESD在前N层之后加入早期退出的结构,并使用这一部分来生成草稿令牌(Draft Token)。为了提升这些初步令牌的质量,我们还结合了一种自我蒸馏方法。这种早期退出的设计不仅降低了部署和训练的成本,还大大提高了令牌(Token)生成的速度。
除此之外,我们还引入了一种新的采样机制,该机制利用了汤普森采样来调生成过程,并自动确定每一轮中草稿令牌的数量。然后,我们使用原始的LLM来验证这些草稿令牌,通过一次前向传递来确保最终输出的文本与原始的自回归解码保持一致。在13B和70B的模型上的实验结果表明,我们的方法在文本生成速度上比以往的方法有显著的提升,这充分证明了该的方法的有效性。
02
Graph-Structured Speculative Decoding
论文类型:Long Paper
论文下载:PDF
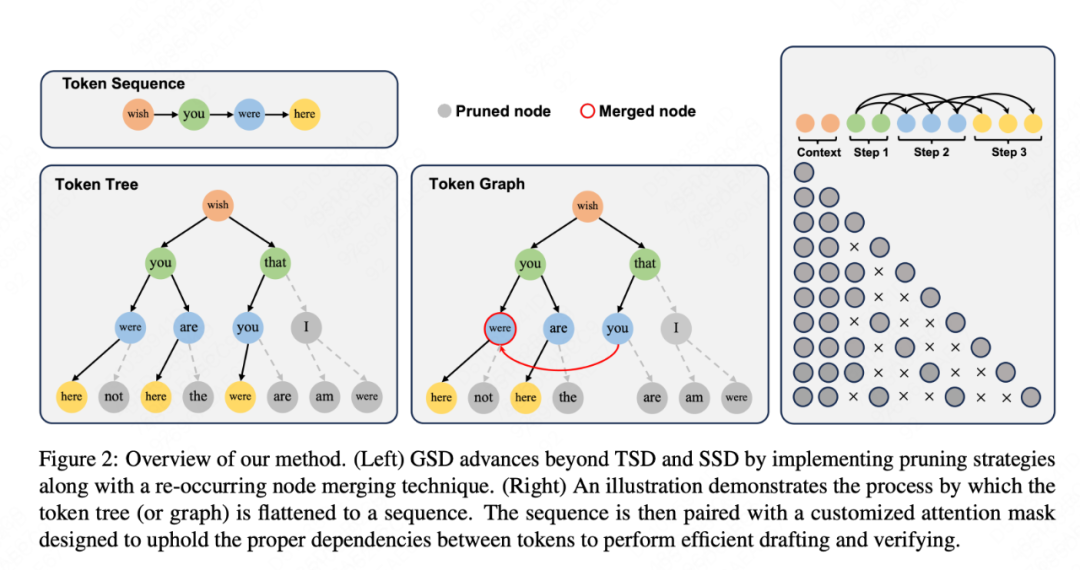
论文简介:投机解码已经崭露头角,它使用小型语言模型创建一种假设序列,然后由大型语言模型(LLM)进行验证,从而加快了LLM的推理速度。这种方法的效果主要取决于草稿模型的性能和效率如何平衡。在我们的研究中,我们试图通过生成多个假设,而不仅仅是一个,来增加被接受到最终结果的草稿令牌数量。这样,LLM就有了更多的选择,并可以选择最长的、符合其标准的序列。我们的分析发现,由草稿模型产生的假设中有许多公共的令牌序列,这暗示了我们可以优化计算。
因此,我们引入了一种新的方法,使用有向无环图(DAG)来管理草拟的假设。这种结构使我们能够有效地预测和合并重复的令牌序列,大大降低了草稿模型的计算需求。我们将这种方法命名为图结构投机解码(GSD)。我们在多种LLM中应用了GSD,包括一个参数达到700亿的LLaMA-2模型,结果发现文本生成速度提高了1.73倍到1.96倍,显著超过了标准的投机解码。
03
DolphCoder: Echo-Locating Code Large Language Models with Diverse and Multi-Objective Instruction Tuning
论文类型:Long Paper
论文下载:PDF
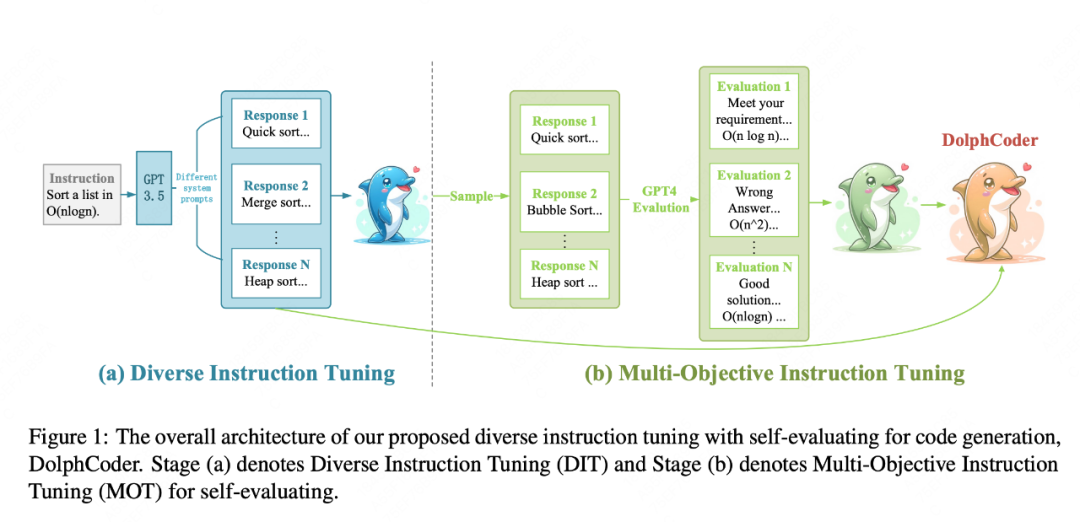
论文简介:在代码相关任务中,大型语言模型已经展现出出色的性能。为了提高预训练的 Code LLMs 的代码生成性能,一些工作已经提出了几种指令调优方法。
在本论文中,我们介绍了一种带有自我评估的多样化指令模型(DolphCoder),用于代码生成。它学习多样化的指令目标,并将代码评估目标结合起来,以增强其代码生成能力。我们的模型在HumanEval 和 MBPP 基准上取得了优越的性能,为未来的代码指示调优工作提供了新的见解。我们的主要发现是:(1)增加具有不同推理路径的多样化响应可以提高LLMs的代码能力。(2)提高评估代码解决方案的正确性的能力也同时提高了创建代码的能力。
04
Learning or Self-aligning? Rethinking Instruction Fine-tuning
论文类型:Long Paper
论文下载:PDF
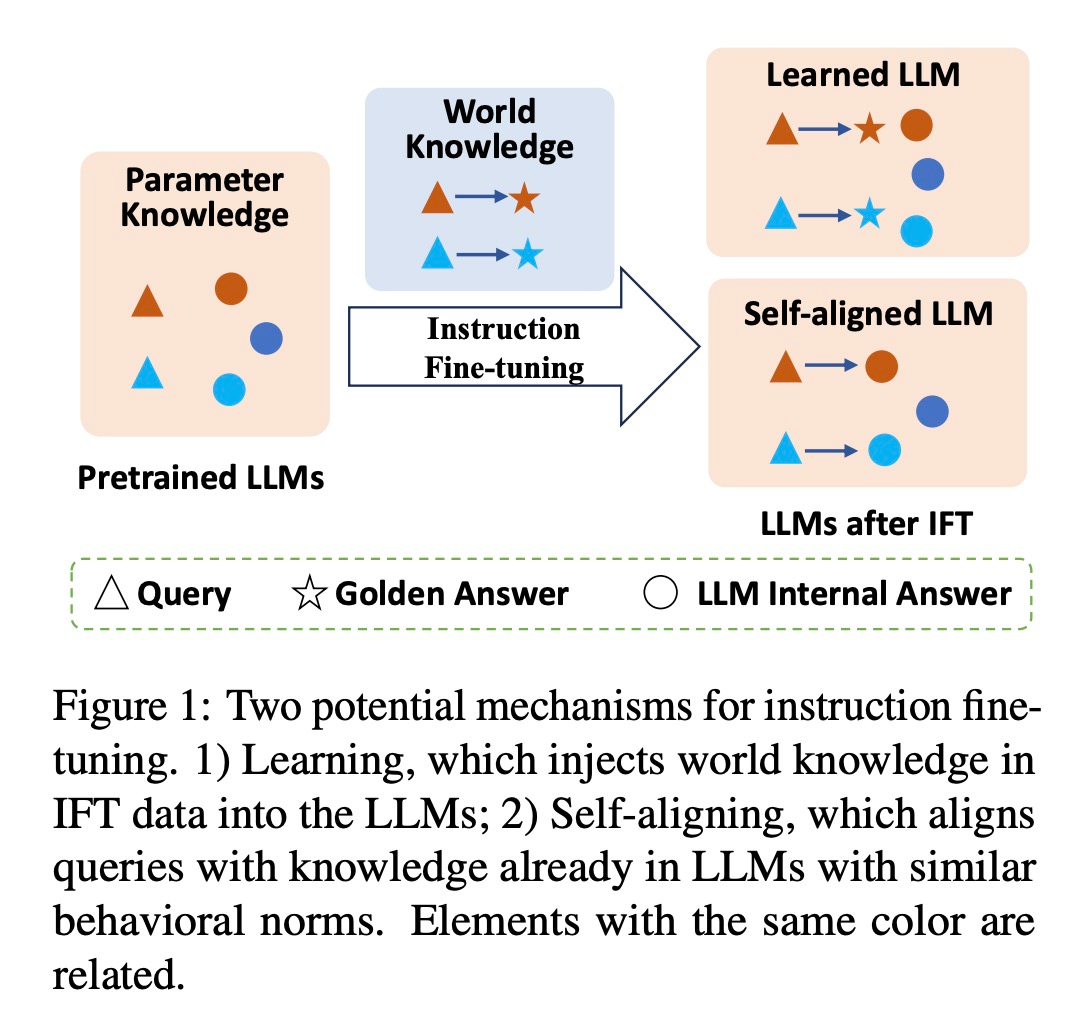
论文简介:指令微调(IFT)已经成为大型语言模型构建的核心步骤之一,当前主要是应用于模型行为模式的转换和注入特定领域知识。但指令微调对大模型输出的影响机制仍缺乏深入分析,对于指令微调给模型带来的增益,是由于指令微调过程带来的额外领域知识增益,还是其成功对齐了期望的输出空间从而实现了更好的知识表达机制尚不清楚。为此,本文设计了一个知识扰动的分析框架,来解耦合模型行为模式转换与额外知识注入的作用,以探索大模型指令微调的底层机制。
实验表明,试图通过指令微调学习额外知识往往难以产生积极影响,甚至可能导致明显的负面影响。而在指令微调前后保持内部知识一致性是实现成功指令微调的关键因素。研究结果揭示出指令微调的潜在机制,即指令微调的核心作用机制并不是让模型去「学习」额外知识,而是将模型内部现有的知识进行一种自我对齐,从而给模型带来增益。
活动推荐:直播带你读ACL论文
美团在ACL会议现场设有展位(第11号),美团的论文作者、技术专家、HR也都在现场,欢迎大家来交流!
会议期间,我们还邀请了业内技术大咖、Paper作者,齐聚美团直播间,点评优秀论文,分享前沿成果,欢迎预约。
---------- END ----------
美团科研合作
美团科研合作致力于搭建美团技术团队与高校、科研机构、智库的合作桥梁和平台,依托美团丰富的业务场景、数据资源和真实的产业问题,开放创新,汇聚向上的力量,围绕机器人、人工智能、大数据、物联网、无人驾驶、运筹优化等领域,共同探索前沿科技和产业焦点宏观问题,促进产学研合作交流和成果转化,推动优秀人才培养。面向未来,我们期待能与更多高校和科研院所的老师和同学们进行合作。欢迎老师和同学们发送邮件至:meituan.oi@meituan.com。
推荐阅读
















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









