






大众点评技术部/搜索与内容智能团队组成的BlackPearl队伍,参加了2024年KDD 2024 OAG-Challenge Cup赛道的WhoIsWho-IND、PST、AQA三道赛题,以较大优势包揽了该赛道全部赛题的冠军。本文对这三个赛道的夺冠方案分别进行了解读,希望对大家有所帮助或启发。

KDD 2024 OAG-Challenge Cup与学术数据挖掘研究相关,学术数据挖掘的最终目标是加深我们对科学的发展、本质和趋势的理解。它提供了发掘巨大的科学、技术和教育价值的潜力。例如,从学术数据中进行深度挖掘可以协助政府制定科学政策,支持公司人才发现,并帮助研究人员更有效地获取新知识。学术数据挖掘包含很多以学术实体为中心的应用,比如论文检索、专家发现和期刊推荐等。然而,学术知识图谱挖掘相关的数据基准的缺乏严重限制了该领域的发展。KDD 2024 OAG-Challenge Cup主要包括三道经典学术知识图谱挖掘问题,包括:
-
论文同名消歧(WhoIsWho-IND):目前,在线出版物数量的迅速增加使得同名消歧问题变得更加复杂。此外,现有消歧系统的不准确导致了错误的作者排名和奖项作弊的情况。本任务在给定每位作者的个人资料,包括作者姓名和发表的论文情况下,需要开发一个模型来检测论文中错误分配给该作者的论文。此外,数据集还提供了所有涉及论文的详细属性,包括标题、摘要、作者、关键词、地点和发表年份。
-
论文源头追溯(PST):随着科技的飞速发展,论文数量呈爆炸式增长。全球每年发表数百万篇论文,且数量持续攀升。根据Scopus数据库,截至2021年,全球已发表2.2亿篇学术期刊论文,涵盖自然科学、社会科学和人文科学等各领域。对于研究者来说,从众多文献中把握技术发展的脉络变得愈加困难。PST任务要求在给定一篇论文p的全文的情况下,从这篇论文中找出ref-source。ref-source即最重要的参考文献(叫做“源头论文”),一般是指对本篇论文启发性最大的文献。每篇论文可以有一篇或多篇ref-source,也有可能没有ref-source。对于论文的每一篇参考文献,论文源头溯源都要给出一个范围在[0, 1]的重要性分数。
-
学术论文问答(AQA):在这个技术蓬勃发展,信息迅速更新的时代,为研究人员和大众提供多领域的高质量前沿学术知识已成为当务之急。AQA给定专业问题和一组候选论文,目标是检索到最相关的论文来回答这些问题。
BlackPearl团队在本次竞赛中,创新性地采用大模型来解决学术挖掘领域中的论文同名消歧、论文源头追溯、学术论文检索三个经典难题,显著优于特征工程、GNN、BERT等传统方案。本文将对BlackPearl团队在此次三赛道的夺冠方案进行分别解读,更多完整细节和代码请移步GitHub。
论文同名消歧(WhoIsWho-IND)
在论文同名消歧任务中,由于每条样本下的论文数量过多以及每篇论文包含的信息量较大,导致输入文本超长,现有的文本聚类方法不能充分的利用这些信息。故赛题的难点在于如何构造大模型输入形式、如何在资源有限的情况下利用更多信息以及充分发挥大模型的潜力。
针对以上难点,BlackPearl将原始的聚类任务转化为比较任务,构建了一套基于自反馈增强的迭代式大模型文本聚类链路。此外,BlackPearl还使用了Train-Time Difficulty Increase (TTDI)和Test-Time Augmentation(TTA)[1]等技术,进一步提升效果。算法框架如下图1所示:
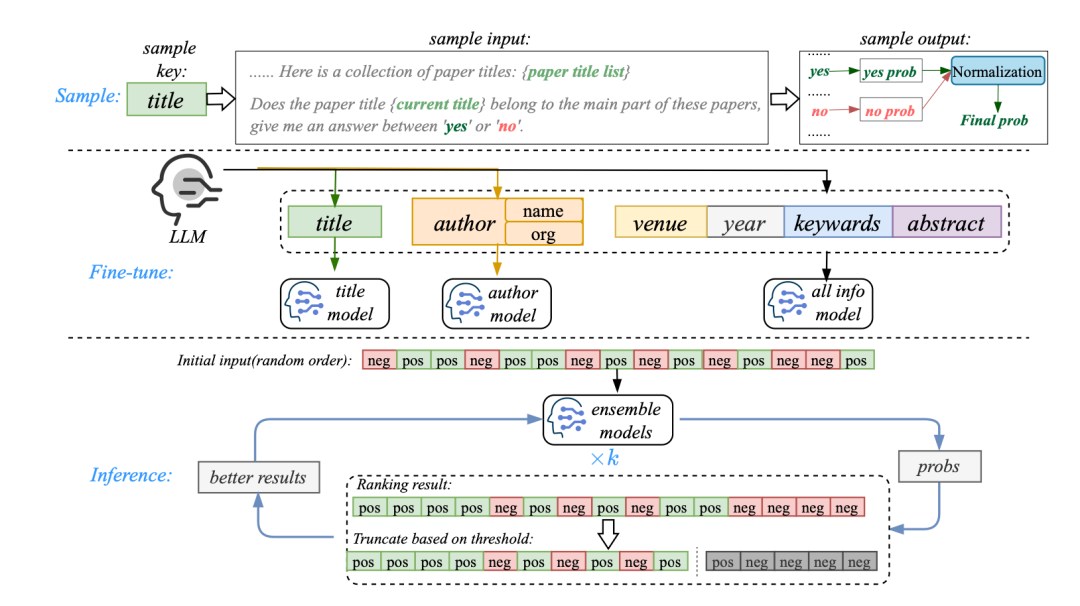
在将任务转化为比较任务后,从经验上看,输入的参考文献越多,模型接收的输入中的参照信息也更丰富,对模型判断当前paper是否正确也越有帮助,我们通过实验也验证了这一点。然而,在固定最大输入长度的限制下,在输入中拼接的参考文献越多,每篇论文所包含的信息就越少。
为了尽可能利用更多信息以及尽量减少训练所用资源,我们使用了一种拆分策略、在微调阶段我们使用多源数据对多个模型独立微调,以确保每个模型能够专注于特定的信息源,我们使用deepspeed[2]的zero1来在训练时长和显存占用方面取得平衡,微调方法用LoRA[3]和QLoRA[4]。通过实验,我们确定了标题和作者是最关键的两个信息,其他信息则不在单独训练模型以避免资源浪费。为了利用到其他信息,我们对所有可用信息源进行微调得到一个综合模型,用于模型结果集成,进行信息互补。
由于我们使用比较任务来确定当前论文是否属于主要(正确)类别,我们自然会认为,参考文献中正确论文的比例越高,模型对当前论文的正确性判断就越有信心。基于此,我们提出了迭代自精炼(IRF)方法,该方法不需要额外的模型训练,通过不断精炼参考论文中正确论文的比例来获得更好的结果。通过将大模型预测的若干paper正确概率进行排序+阈值截断,使得大模型比较任务下一轮输入的参考paper中正样本浓度提升,从而使得模型输出结果时更自信,最终显著提高了识别正确论文的概率。由于第一轮迭代时我们还没有拿到预测概率,因此初始输入中的参考文献是随机采样的。
为了使模型在推理阶段应对更具挑战的样本,我们在训练阶段增加任务难度,以防止任务变得简单。例如,减少最大训练长度、适当增加训练输入中错误论文的比例,从而提升模型的鲁棒性。
在比较任务中,模型输出的概率不应受参考文献输入顺序的影响。针对这一问题,我们充分利用TTA,在将每个样本中的参考文献输入模型之前,对其顺序进行shuffle,并对多个结果进行平均,以获得更稳健的结果。
我们做了大量实验验证了我们方法的有效性,对比实验和消融实验如下所示:
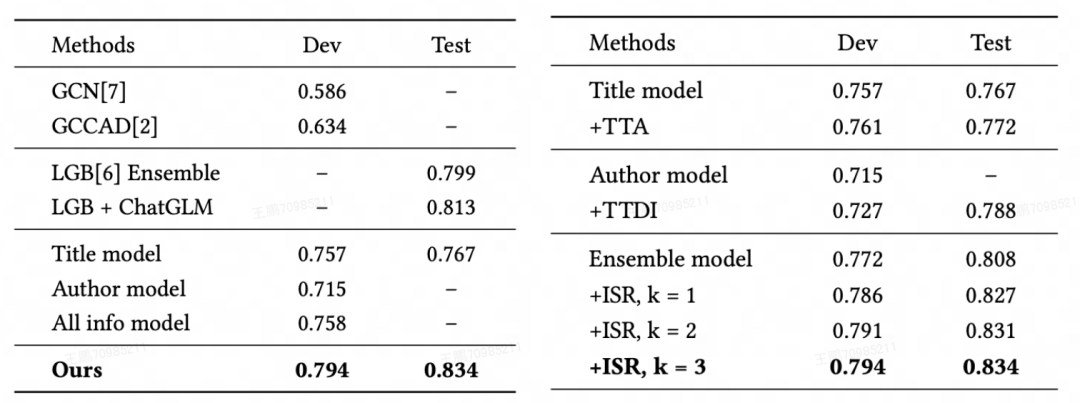
总的来说,我们的核心上分点如下:
-
Task Format Conversion:将聚类任务转化为比较任务,在输入中给出一些参考论文,并确定当前论文是否属于主要类。
-
Train-Time Difficulty Increase (TTDI) : 训练阶段增加任务难度,让模型跳出“舒适区”,使其能够在推理过程中更好地处理具有挑战性的示例。
-
Test-Time Augmentation (TTA):在测试时对输入数据施加多种变换(此题为打乱参考文献的输入顺序),并对这些变换后的数据进行模型预测。最终,汇总这些预测结果(例如取平均值或进行投票),以获得更稳健和准确的最终预测。
-
自反馈增强的迭代式大模型文本聚类:针对比较任务,通过不断精炼参考论文中正确论文的比例来获得更好的结果。
论文源头追溯(PST)
在论文源头追溯任务中,我们面临三大挑战:数据集标签分布差异、冗长的HTML格式标识符、超大规模无标注数据集辅助信息召回。具体而言,该任务存在规则标注的和人工标注的两类数据集,且这两类数据集的标签分布存在显著差异。规则标注的数据集数据量大,但标签置信度低、噪声较多且有效信息分散;人工标注的数据集标签置信度高,且与测试集分布一致,但数据量较少。此外,数据集中还存在大量HTML格式标识符,这些标识符文本长度可达数万Token,却包含极少的有效信息。同时,该任务存在的超大规模无标注数据集(DBLP数据集)拥有各论文完善的辅助信息,但需要自行召回有效信息。
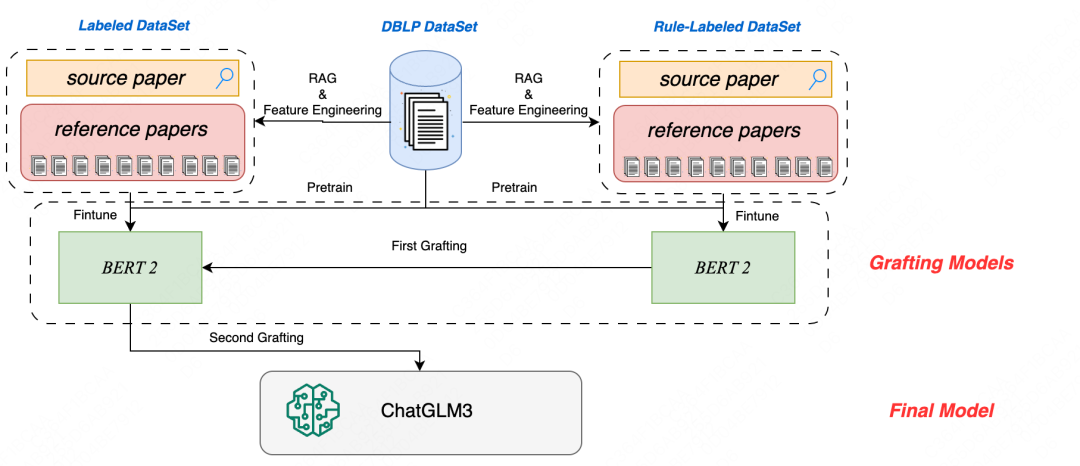
故赛题的难点在于如何充分利用不同置信度的训练数据集及超长的上下文信息、提取高噪声数据中的有效增益信息。针对这两个难点,团队利用嫁接学习[5]的思想分别提出Grafting-Learning For DataSet技术和Grafting-Learning For LongText技术,将BERT-Like模型的复杂文本语义匹配能力嫁接到LLM中,提高样本置信度。同时,团队提出的Automatic RAG & Feature Engineering技术能够自动召回辅助信息,进一步去除超大规模无标注数据集中的高噪声。算法框架如下图2所示:
-
Grafting-Learning For DataSet:多个不同数据集之间的标注规则存在差异,由于本次存在规则标注的数据集,其标注质量较低但数据集规模极大,巧妙利用该数据集能够带来较大的指标提升。我们提出了Grafting-Learning For DataSet技术,在规则数据集上对BERT进行微调,并将其最后一层隐状态作为人工标注数据集的额外特征,用于训练第二个BERT模型。这种方法巧妙地嫁接了规则数据集的有效正标签信息。同时,我们在消融实验下发现嫁接学习的方式比普通迁移学习(即在规则标注数据集微调后的BERT模型再用人工标注数据集微调)更具鲁棒性。由于两类数据集的标签分布差异较大,普通迁移学习甚至会带来负收益,而嫁接学习能够有效保留有益信息、摒除无益信息。
-
Grafting-Learning For LongText:长文本训练和推理会显著增加时间和显存消耗。为缓解该现象,团队提出了Grafting-Learning For LongText技术,将多来源的文本分别经过不同的BERT进行有监督微调,最终每条数据都将得到多个不同来源的模型预测概率,此时噪声文本中的有效信息增益都被BERT模型提取完成,再将预测概率输入到ChatGLM中,即可用较短的文本和BERT预测概率进行最终的模型判断。此方法能够有效避免在Attention计算时由于文本过长导致时间开销平方级爆炸增长,将其切割后利用小模型BERT提纯噪声,只保留过滤后的BERT预测概率用以做最终判断。同时,由于采用了多个BERT模型提纯去噪,高噪声对最终结果的影响进一步降低,模型输出结果更加置信。
-
Automatic RAG & Feature Engineering:在超大规模无标注数据集(DBLP数据集)中,存在着每篇论文对应的少量辅助信息,同时也存在大量相似论文的噪声信息。团队提出的Automatic RAG & Feature Engineering技术能够自动分析每篇论文的重点,于DBLP数据集中找到其对应的辅助信息,同时在RAG链路过程中就完成了一系列特征工程的构建。在辅助信息和特征工程的帮助下,模型能够以更短的输入产出更可信的结果。
学术论文问答(AQA)
在这个技术蓬勃发展,信息迅速更新的时代,为研究人员和大众提供多领域的高质量前沿学术知识已成为当务之急,本次学术论文问答任务要求参与者开发一个模型,能够通过检索相关论文来回答专业问题,本质上是一个检索任务,即给定用户问题,检索出最相关的论文,评估指标是MAP@20。
本赛题数据集来源于从StackExchange和知乎网站检索问题帖,提取答案中提到的论文URL作为标签,从业务和数据角度上理解,带有复杂噪声的数据是该任务的主要难点,主要原因在于数据来源于互联网网站用户问题的引用数据集,不可避免的存在大量噪音。比如用户为什么引用这篇论文的认知标准是不一样的,理论上一个问题可以对应多个论文,所以噪音之大可想而知。采用开源向量模型对文本进行召回时,存在开源模型召回的论文从语意上跟原文非常接近,但正确答案可能排名靠后的问题。甚至在采用bert类SimCSE模型进行对比学习微调后模型性能进一步降低。
针对噪声大,学习难的问题,我们提出了三个核心方法去解决噪声大、学习难的问题。算法框架如图3所示:
-
LLM for Vector:在LLM时代前期,一般文本相似度表征会采用自编码模型,参数量一般不超过1B,在大模型时代,LLM的表征能力明显优于自编码器模型的表征能力,本次赛题我们采用了目前向量表征能力较好的7B模型SFR-Embedding-Mistral[6]。
-
Hard example挖掘:在训练向量表征的模型时,比较通用的提升方法是负样本的挖掘,在训练向量表征模型时,负样本的挖掘通常是提升模型表现的重要手段。在赛题中,由于数据呈现出的是“相似并不一定正确”的规律,负样本的挖掘尤为重要。
-
Boosting:Boosting 本质上是一种集成模型的思路,我们在Boosting思想的基础上,我们提出了一种迭代的负样本挖掘过程。在每次迭代中,模型能够召回难度更高的负样本,逐步累积具有更高挑战性的负样本集,进而指导模型学习。
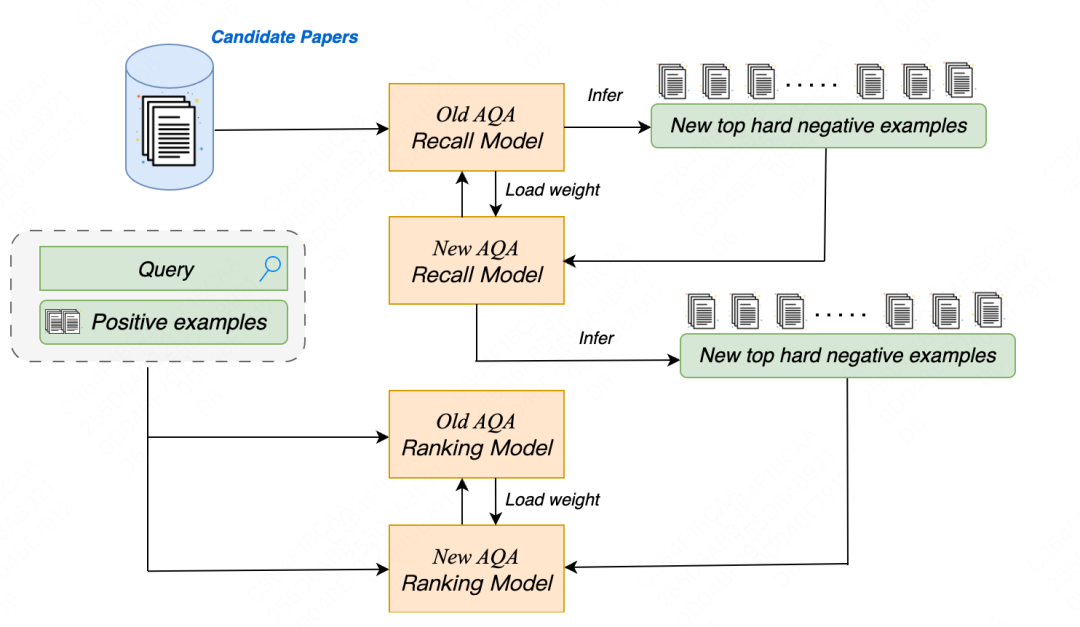
接下来介绍我们实现的模型框架细节:
-
召回(Recall):在此次竞赛中,用户查询的候选论文集包含成千上万的论文。为了确保效率和实用性,将任务分成召回和排序两个过程是一个切实有效的策略,我们基于SFR-Embedding-Mistral 进行指令微调,微调采用对比学习损失函数,每一个batch迭代过程中,对每一个正样本,我们随机从100个难负样本中抽取3个负样本,并联合batch内其他负样本计算一个样本的损失。每次迭代我们固定轮次10轮,学习率1e-4,若采用QLORA进行微调可进行单卡微调。
-
排序(Ranking):在排序优化中,我们同样采取指令微调的方式,基于SOLAR-10.7B-Instruct-v1.0模型,微调采用交叉熵损失函数,每一个batch迭代过程中,对每一个正样本,我们随机从100个难负样本中抽取3个负样本计算一个样本的损失函数,每次迭代我们固定轮次10轮,学习率1e-4,若采用QLORA进行微调可进行单卡微调。
-
Boosting迭代:在召回模型和排序模型的训练中,负样本是至关重要的。我们制定了一种困难负样本挖掘方法来进一步提高模型的性能即采用迭代的方法进行困难负样本挖掘,如图3所示。在召回模型的训练中,在初始迭代时,我们使用开源的SFR-Embedding-Mistral模型来检索前100个困难负样本。这些样本然后用于微调以获得增强的模型。在随后的迭代中,利用上一轮改进的模型来检索前100个困难负样本,并进一步进行微调。对于排序模型,我们继续使用由召回模型检索到的困难负样本进行训练。这个迭代过程确保每一轮训练都能提升模型在上一轮中的性能。
如果未经微调,即使是先进的基于LLM的模型也表现不佳。然而,通过实施我们的微调策略,我们在第一次迭代中观察到初步提升了0.07。如下表所示,MAP@20分数在后续的每次迭代中逐步提高。到第六次迭代时,改进的速度开始减缓。最终,我们共进行了八次迭代,并通过Rank avg融合,最终分数达到了0.301,相对于原生的基座模型获得较大提升。
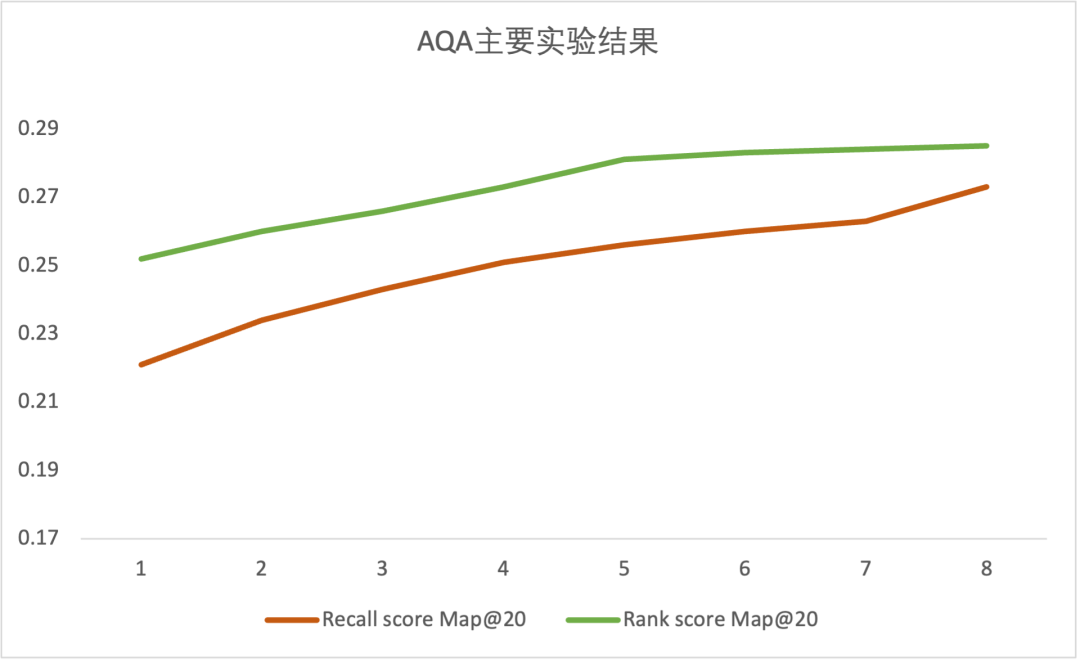
图4:AQA主要实验结果
在本次大赛中,BlackPearl团队同学通过大模型技术解决了多个问题,再次让我们看到了前沿科技的力量。面向未来,大众点评技术部将不断深入探索大模型技术,充分挖掘其内在潜力,通过先进的AI技术,使点评App能够更精准地服务于用户,让AI帮大家更懂美食,更会生活。
写在后面
就在今天,2024年9月12日,美团技术团队公众号粉丝刚好突破了40万,感谢大家十年来的支持与厚爱,陪我们一路同行。种一棵树最好的时间是十年前,其次是现在。从十年前开始,我们就信仰耐心和坚持的力量,愿意持续去做一些正确、有积累的事情。
十年来,美团技术团队公众号一直在努力践行,已经将600多篇美团内部优秀的技术文章分享给了大家,很开心能够跟大家一起学习交流、共同进步。恰逢中秋佳节即将到来,美团技术团队提前祝大家阖家欢乐,健康平安~~
// 参考文献 //
[1] Wang, G., Li, W., Ourselin, S., & Vercauteren, T. (2019). Automatic brain tumor segmentation using convolutional neural networks with test-time augmentation. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries: 4th International Workshop, BrainLes 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 16, 2018, Revised Selected Papers, Part II 4 (pp. 61–72). Springer.
[2] Rasley, J., Rajbhandari, S., Ruwase, O., et al. (2020). Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 3505-3506).
[3] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
[4] Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2024). Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36.
[5] Jiangli Club. (n.d.). 嫁接学习的提出与具体用例. Retrieved from http://jiangliclub.com/article?article_id=72.
[6] Meng, R., Liu, Y., Joty, S. R., Xiong, C., Zhou, Y., & Yavuz, S. (2024). SFR-Embedding-Mistral: Enhance Text Retrieval with Transfer Learning. Salesforce AI Research Blog. Retrieved from https://blog.salesforceairesearch.com/sfr-embedded-mistral/.
[7] Zhang, F., Shi, S., Zhu, Y., Chen, B., Cen, Y., Yu, J.,... & Tang, J. (2024). OAG-Bench: A Human-Curated Benchmark for Academic Graph Mining. arXiv preprint arXiv:2402.15810.
---------- END ----------
推荐阅读
















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









