






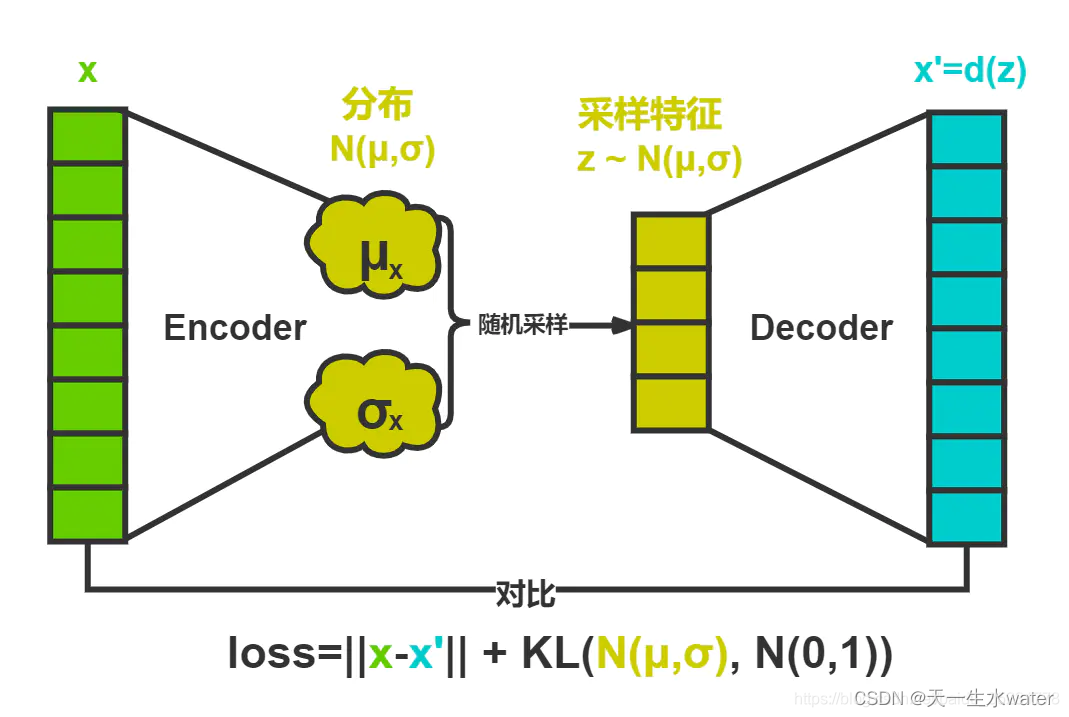
变分自编码器(Variational Autoencoder,VAE)是一种生成模型,通常用于学习数据的潜在表示,并用于生成新的数据样本。它由两部分组成:编码器和解码器。
-
编码器(Encoder):接收输入数据,并将其映射到潜在空间中的分布。这意味着编码器将数据转换为均值和方差参数的分布,通常假设为高斯分布。
-
解码器(Decoder):接收来自编码器的潜在表示,并将其映射回原始数据空间。解码器尝试从潜在空间中的样本中生成与输入数据尽可能接近的重建数据。
VAE的目标是学习一个能够生成与训练数据类似的数据分布。为了实现这一点,VAE采用了一种被称为变分推断的方法,其中引入了一个额外的损失项,即KL散度,用于度量生成的潜在分布与预先设定的先验分布之间的差异。
VAE将经过神经网络编码后的隐藏层假设为一个标准的高斯分布,然后再从这个分布中采样一个特征,再用这个特征进行解码,期望得到与原始输入相同的结果,损失和AE几乎一样,只是增加编码推断分布与标准高斯分布的KL散度的正则项,显然增加这个正则项的目的就是防止模型退化成普通的AE,因为网络训练时为了尽量减小重构误差,必然使得方差逐渐被降到0,这样便不再会有随机采样噪声,也就变成了普通的AE。
举例来说,假设我们有一组手写数字的图像作为输入数据。我们可以使用VAE来学习手写数字的潜在表示,并用此表示来生成新的手写数字图像。编码器将输入图像转换为潜在空间中的分布,解码器则将从该分布中采样的样本映射回原始图像空间。通过训练编码器和解码器,VAE可以生成与训练数据类似的手写数字图像,同时学习数据的潜在结构。
以下是使用 PyTorch 实现的简单示例代码,演示了如何使用变分自编码器(VAE)学习手写数字的潜在表示,并用此表示来生成新的手写数字图像:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import numpy as np
import matplotlib.pyplot as plt
# 定义变分自编码器模型
class VAE(nn.Module):
def __init__(self, input_dim, latent_dim):
super(VAE, self).__init__()
# 编码器部分
self.encoder = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, latent_dim * 2) # 输出均值和方差参数
)
# 解码器部分
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, input_dim),
nn.Sigmoid() # 输出范围在 0 到 1 之间
)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
# 编码
z_mu_logvar = self.encoder(x)
mu, logvar = torch.chunk(z_mu_logvar, 2, dim=1)
# 重参数化
z = self.reparameterize(mu, logvar)
# 解码
x_recon = self.decoder(z)
return x_recon, mu, logvar
# 计算重构损失和 KL 散度
def loss_function(x_recon, x, mu, logvar):
recon_loss = nn.BCELoss(reduction='sum')(x_recon, x) # 二进制交叉熵损失
kl_divergence = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return recon_loss + kl_divergence
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.view(-1)) # 将图像展平成向量
])
# 加载 MNIST 数据集
train_dataset = MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
# 初始化模型和优化器
latent_dim = 20
input_dim = 784 # 28x28
model = VAE(input_dim, latent_dim)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 训练模型
num_epochs = 20
for epoch in range(num_epochs):
total_loss = 0
for batch_idx, (x, _) in enumerate(train_loader):
optimizer.zero_grad()
x_recon, mu, logvar = model(x)
loss = loss_function(x_recon, x, mu, logvar)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss / len(train_loader.dataset)}")
# 使用训练好的模型生成新的手写数字图像
with torch.no_grad():
z = torch.randn(10, latent_dim) # 生成 10 个随机潜在向量
generated_images = model.decoder(z)
generated_images = generated_images.view(-1, 1, 28, 28) # 将向量转换成图像形状
# 可视化生成的图像
fig, axes = plt.subplots(1, 10, figsize=(10, 1))
for i, ax in enumerate(axes):
ax.imshow(generated_images[i][0], cmap='gray')
ax.axis('off')
plt.show()
这段代码首先定义了一个简单的变分自编码器模型,然后使用 MNIST 数据集训练该模型,最后使用训练好的模型生成新的手写数字图像。
参考 【PyTorch】变分自编码器/Variational Autoencoder(VAE)_variantautoencoder(vae)pytorch-CSDN博客














 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









