






在搭建hadoop集群之前,要先对hadoop有一定的了解,和熟悉liunx系统的一些基础命令
(可见本人于三月八日发布的博客)
在一定了解下开始我们的hadoop集群操作
一,Hadoop平台安装
首先需要准备三台虚拟机:主机master和从机slave1,slave2
1,配置 Linux 系统基础环境
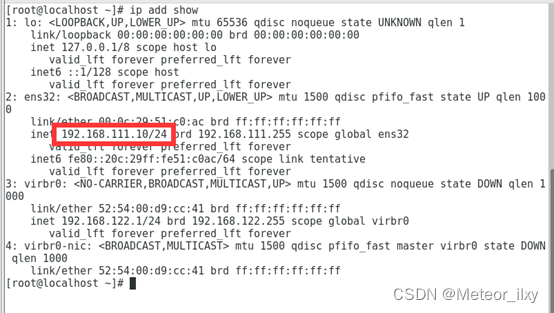
1),查看服务器的ip地址
2),设置服务器的主机名称

3),绑定主机名与ip地址

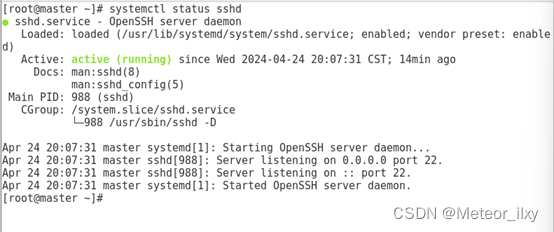
4),查看ssh服务状态
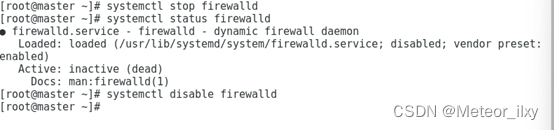
5),关闭防火墙,设置开机不启动
6),创建hadoop用户

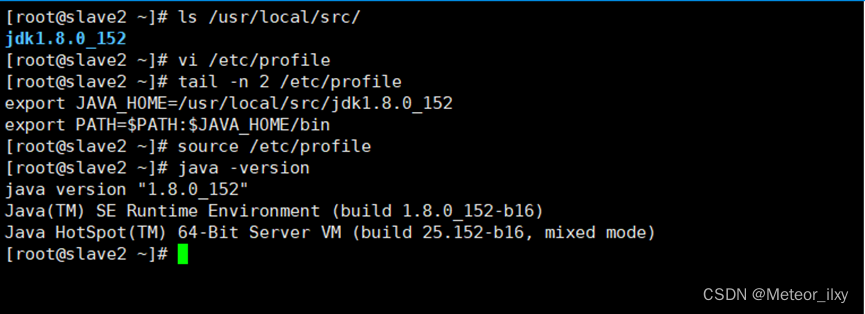
2,安装 JAVA 环境
1),下载JDK安装包
JDK安装包需要在Oracle官网下载 ,下载地址为:
这里采用的安装包为 jdk-8u152-linuxx64.tar.gz。
2),卸载自带OpenJDK
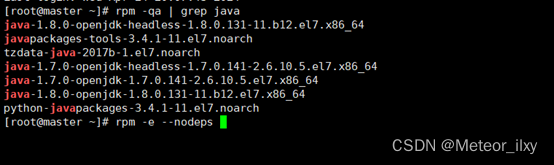
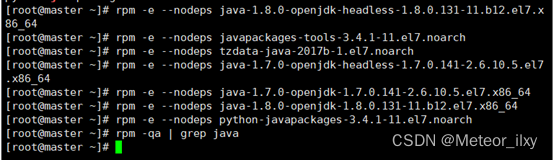
3),安装JDK
![]()
![]()
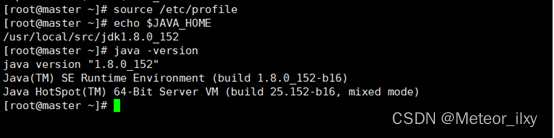
4),设置JAVA环境变量
修改/etc/profile 文件,在文件的最后增加如下两行

执行 source 使设置生效并检查 JAVA 是否可用
3,安装Hadoop软件
1),获取Hadoop安装包
hadoop安装包可在Apache Hadoop - Download官网下载
这里用的安装包为 hadoop-2.7.1.tar.gz。需要先下载 Hadoop 安装包,再上传到 Linux 系统的/opt/software 目录。
2),安装解压
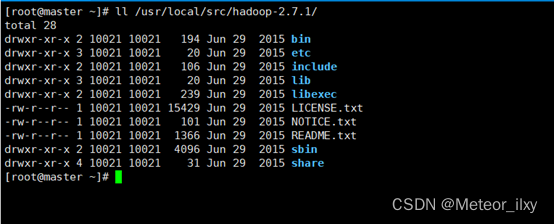
将安装包解压到/usr/local/src/目录下


查看 Hadoop 目录,得知 Hadoop 目录内容如下:
3),配置hadoop环境变量
修改/etc/profile 文件,在文件的最后增加如下两行
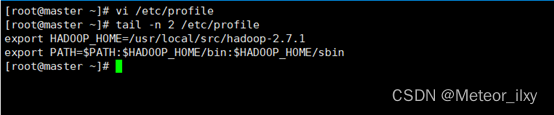
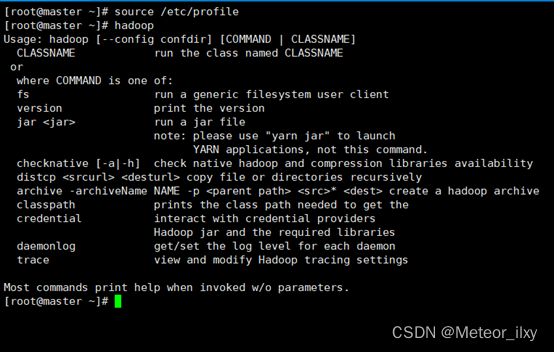
执行 source 使用设置生效并检查设置是否生效
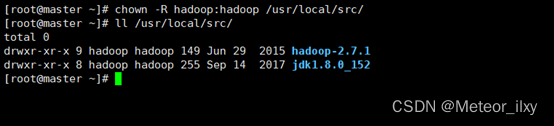
4),修改目录所有者和所有者组
4,安装单机版Hadoop系统
1),配置hadoop文件
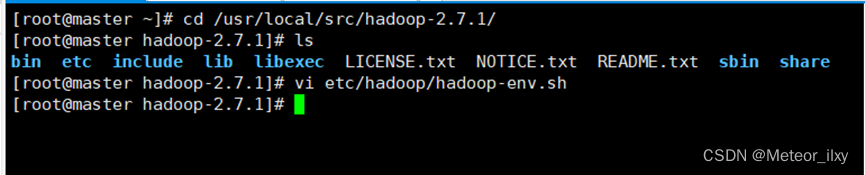
在文件中查找 export JAVA_HOME 这行,将其改为如下所示内容:

2),测试hadoop本地模式的运行
.1,切换到hadoop用户
.2,创建输入数据存放目录
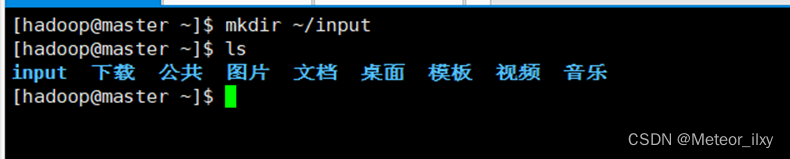
.3,创建数据输入文件

.4,测试MapReduce运行
运行 WordCount 官方案例,统计 data.txt 文件中单词的出现频度。这个案例可 以用来统计年度十大热销产品、年度风云人物、年度最热名词等。命令如下:
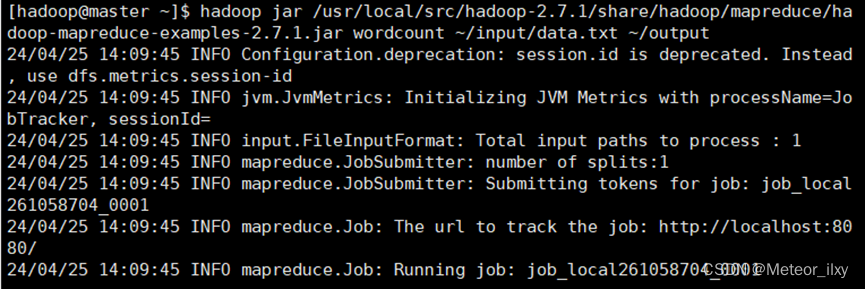
运行结果保存在~/output 目录中(注:结果输出目录不能事先存在),命令执行后查看结果:

文件_SUCCESS 表示处理成功,处理的结果存放在 part-r-00000 文件中,查看该文件

可以看出统计结果正确,说明 Hadoop 本地模式运行正常
二,实验环境下集群网络配置
1,修改 slave1 机器主机名和 slave2 机器主机名
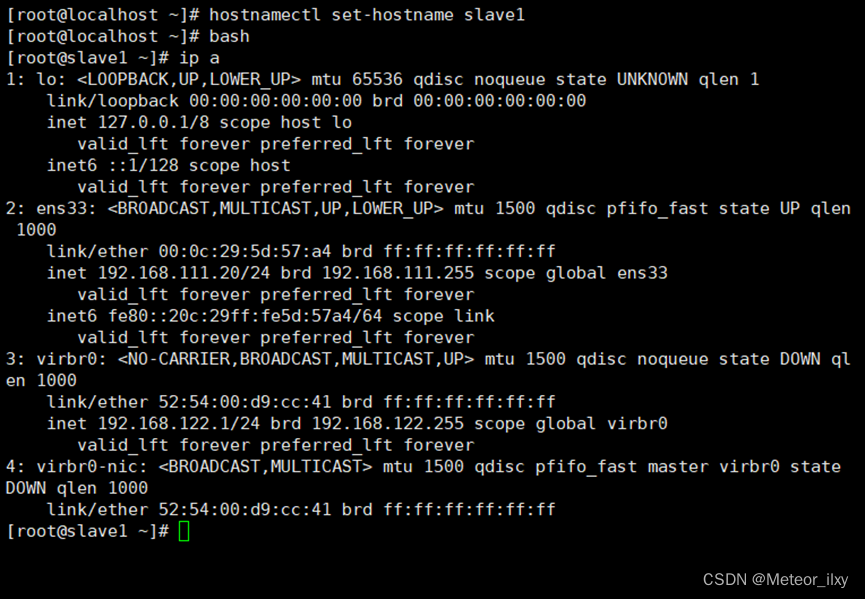
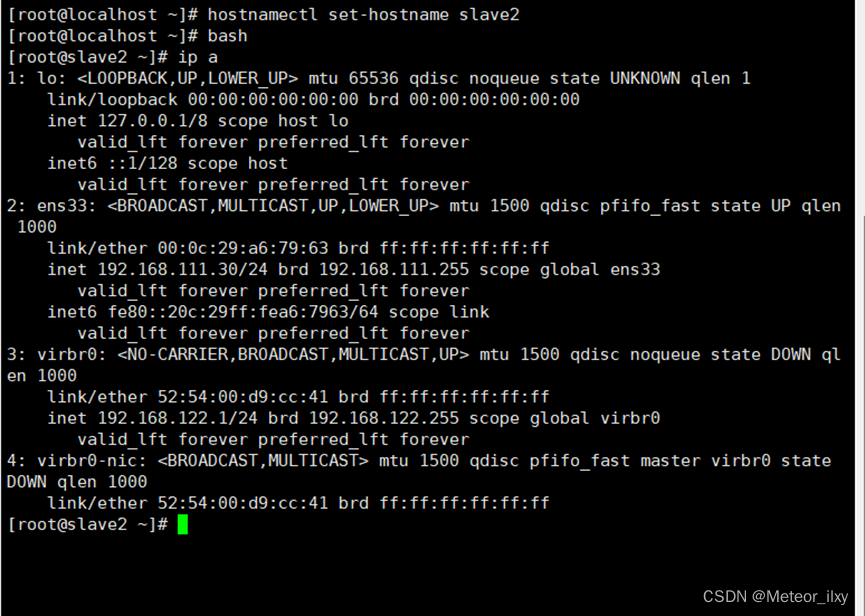
2,根据实验环境下集群网络 IP 地址规划
根据我们为 Hadoop 设置的主机名为“master、slave1、slave2”
映地址是 “192.168.111.10、192.168.111.20、192.168.111.30”
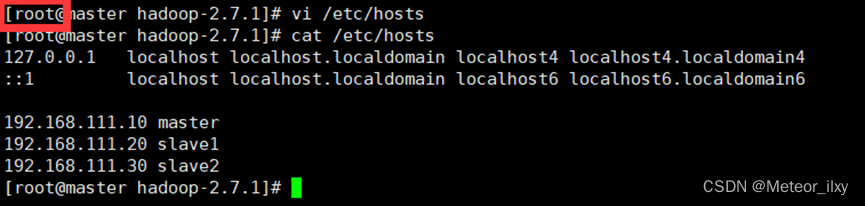
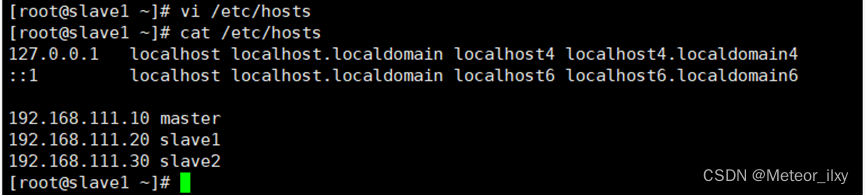
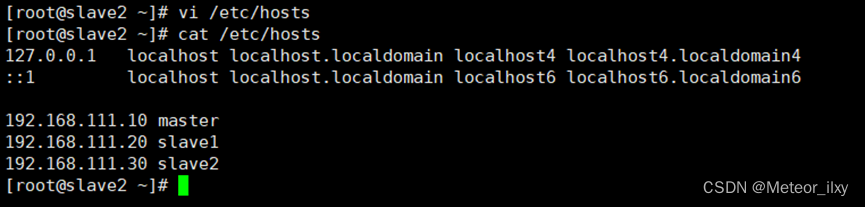
分别修改主机配置文件“/etc/hosts”, 在命令终端输入如下命令:
3,SSH 无密码验证配置
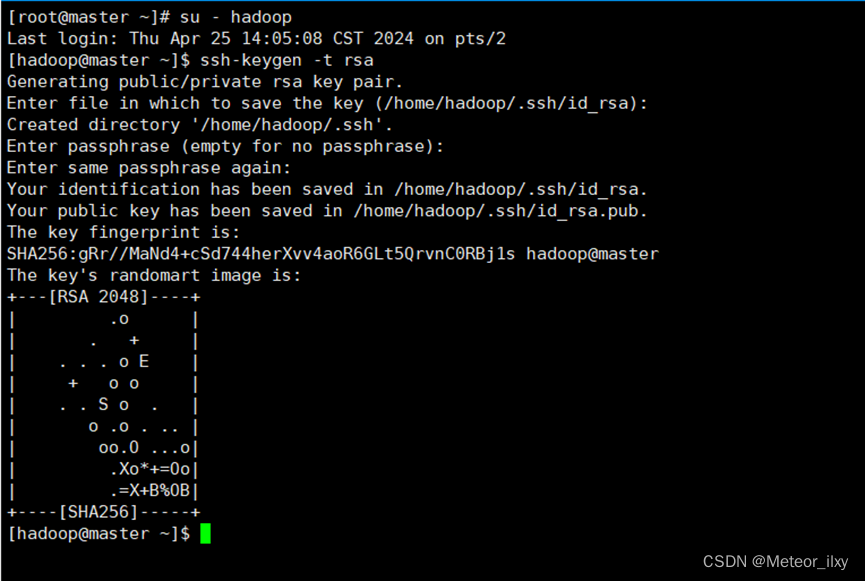
1),生成 SSH 密钥
每个节点安装和启动 SSH 协议,实现 SSH 登录需要 openssh 和 rsync 两个服务,一般情况下默认已经安装(如没有自行安装),可以通过下面命令查看结果

2),切换到 hadoop 用户,在每个节点生成秘钥对
三个回车键
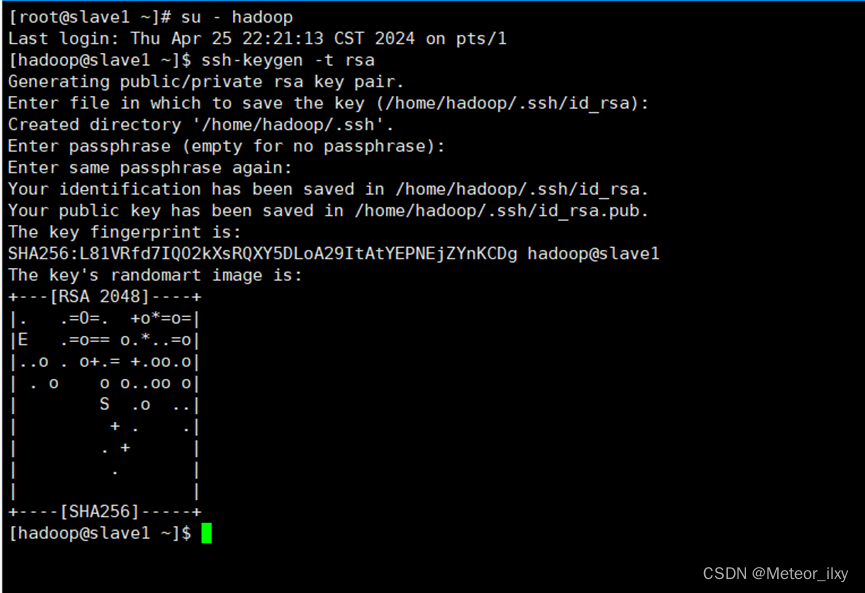
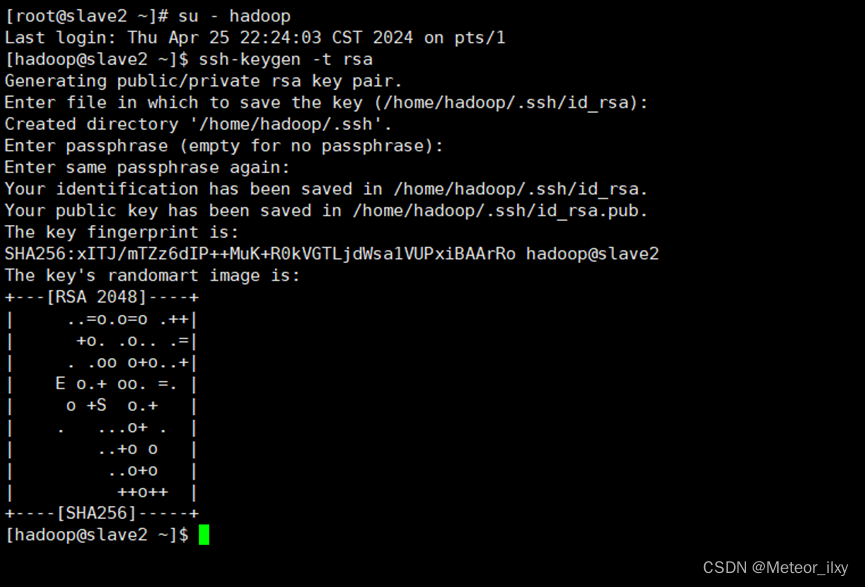
3),查看"/home/hadoop/"下是否有".ssh"文件夹,且".ssh"文件下是否有两个刚 生产的无密码密钥对。

4),将 id_rsa.pub 追加到授权 key 文件中



5),修改文件"authorized_keys"权限
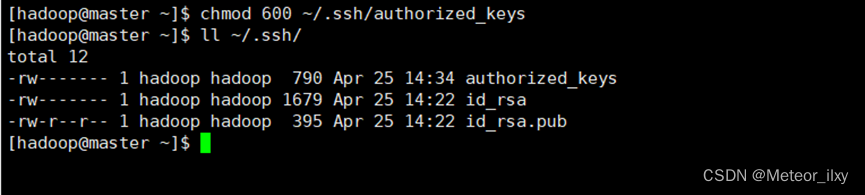
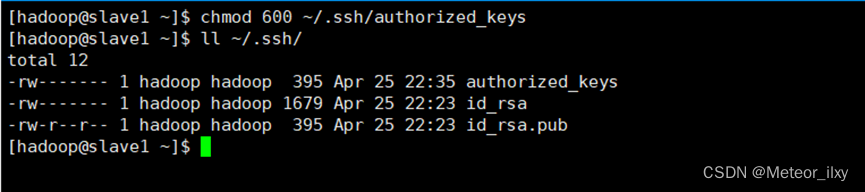
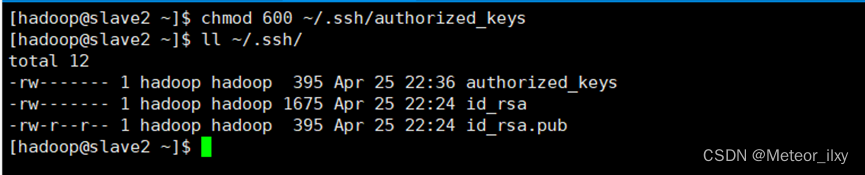
6),配置 SSH 服务
使用 root 用户登录,修改 SSH 配置文件"/etc/ssh/sshd_config"的下列内容,需要将该配置字段前面的#号删除,启用公钥私钥配对认证方式,同样也是三台虚拟机运行相同操作,这里略了


7),重启 SSH 服务并切换到 hadoop 用户

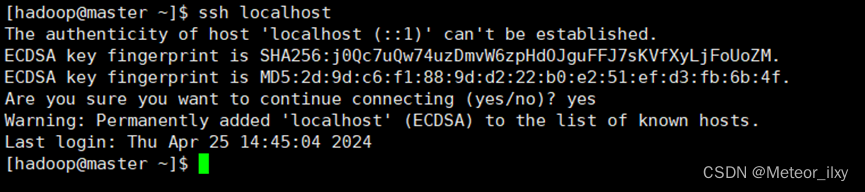
8),验证 SSH 登录本机
在 hadoop 用户下验证能否嵌套登录本机,若可以不输入密码登录,则本机通过密钥登录认证成功
4,交换 SSH 密钥
1),将 Master 节点的公钥 id_rsa.pub 复制到每个 Slave 点

2),在每个 Slave 节点把 Master 节点复制的公钥复制到authorized_keys 文件


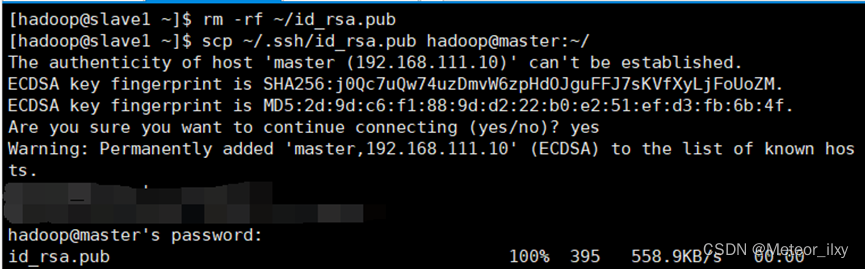
3),在每个 Slave 节点删除 id_rsa.pub 文件


4),将每个 Slave 节点的公钥保存到 Master
.1,将 Slave1 节点的公钥复制到 Master
.2,在 Master 节点把从 Slave 节点复制的公钥复制到 authorized_keys 文件

.3,在 Master 节点删除 id_rsa.pub 文件
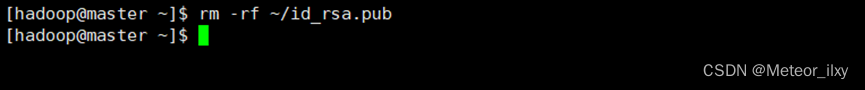
.4,将 Slave2 节点的公钥复制到 Master

.5,在 Master 节点把从 Slave 节点复制的公钥复制到 authorized_keys 文件

.6,在 Master 节点删除 id_rsa.pub 文件
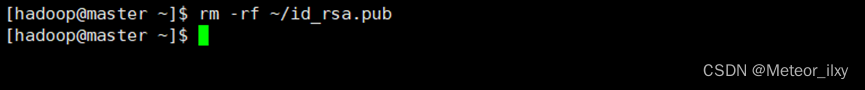
5,验证 SSH 无密码登录
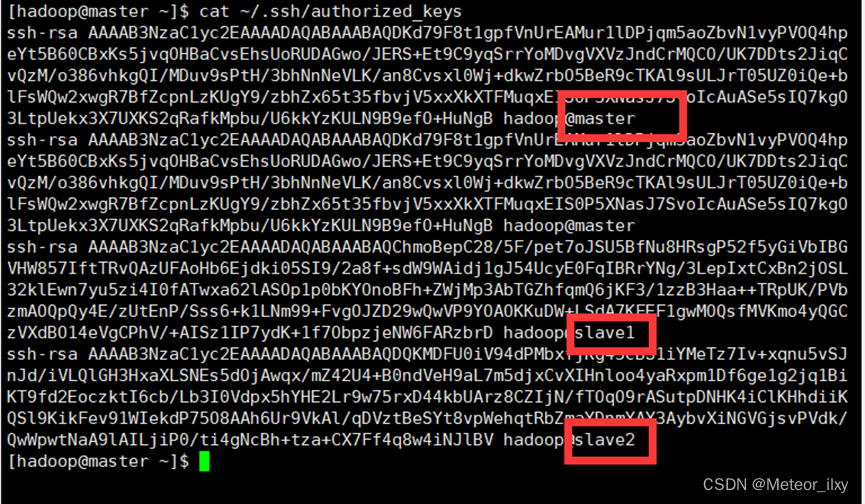
1),查看 Master 节点 authorized_keys 文件
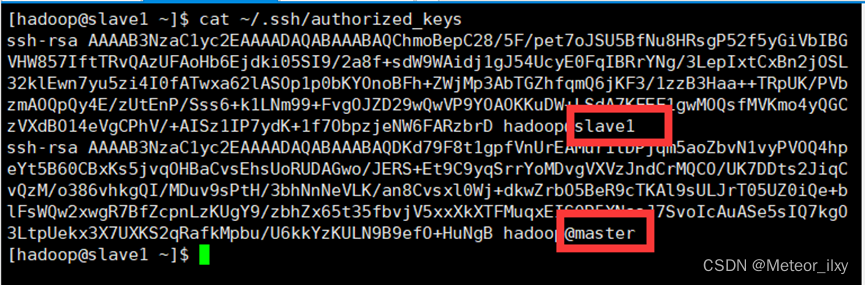
2),查看 Slave 节点 authorized_keys 文件
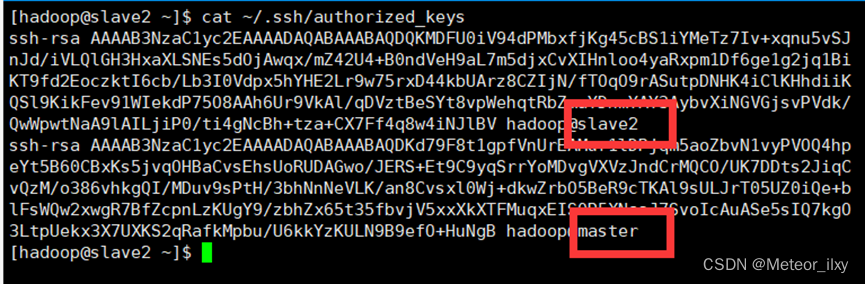
3),验证 Master 到每个 Slave 节点无密码登录
4),验证两个 Slave 节点到 Master 节点无密码登录


5),配置两个子节点slave1、slave2的JDK环境
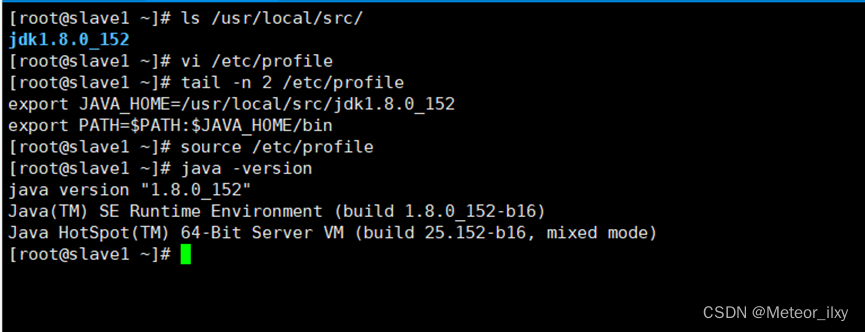
在 /etc/profile 此文件最后添加下面两行
三,Hadoop集群运行
1,在 Master 节点上安装 Hadoop
1),将 hadoop-2.7.1 文件夹重命名为 Hadoop

2),配置 Hadoop 环境变量
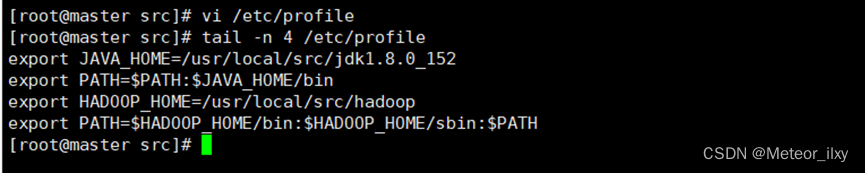
3),使配置的 Hadoop 的环境变量生效

4),执行以下命令修改 hadoop-env.sh 配置文件

修改以下配置

2,配置 hdfs-site.xml 文件参数
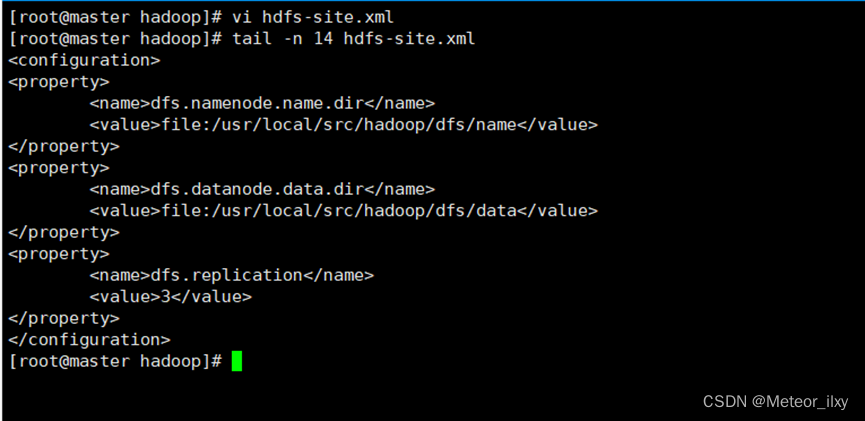
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
3,配置 core-site.xml 文件参数

<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.111.10:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
</property>
</configuration>
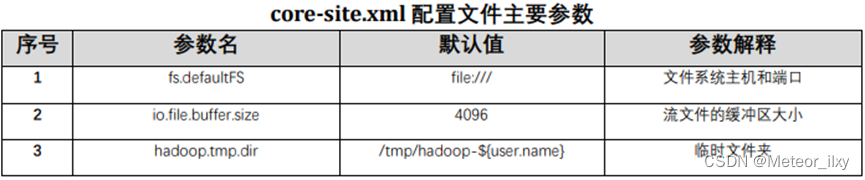
4,配置 mapred-site.xml文件参数
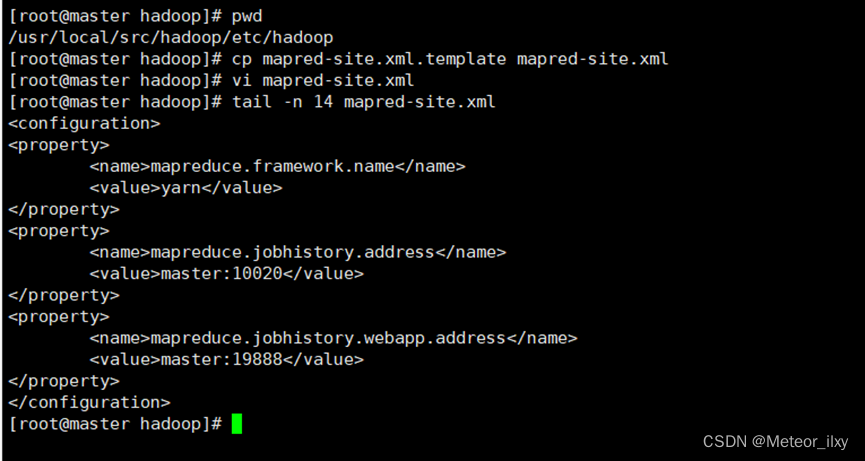
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
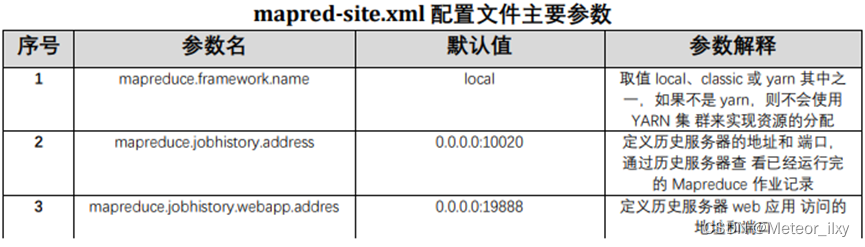
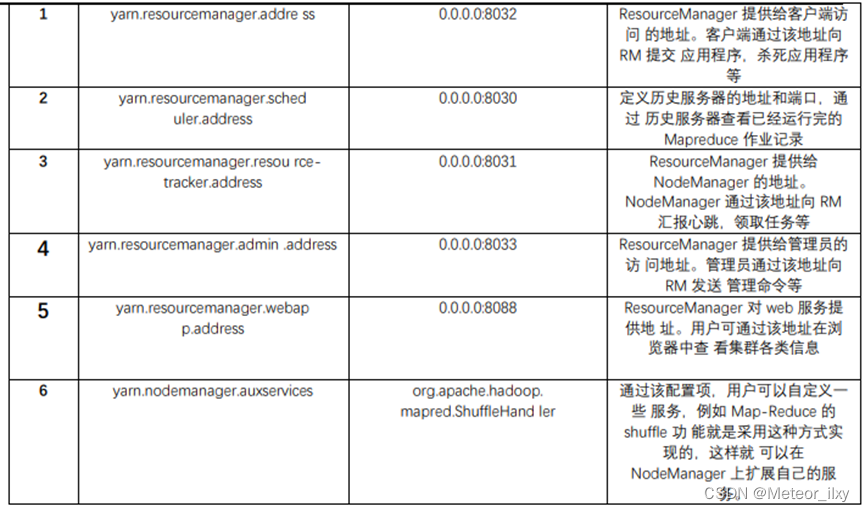
5,配置 yarn-site.xml文件参数
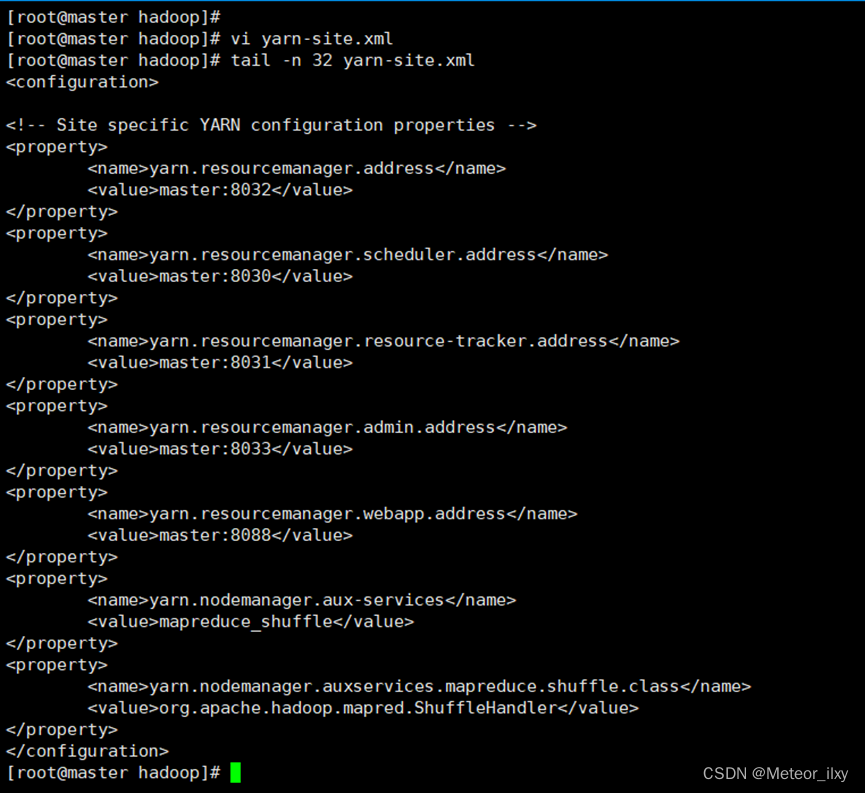
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
6,Hadoop 其他相关配置
1),配置 masters 文件

2),配置 slaves 文件

3),新建目录

4),修改目录权限

5),同步配置文件到 Slave 节点


四,大数据平台集群运行
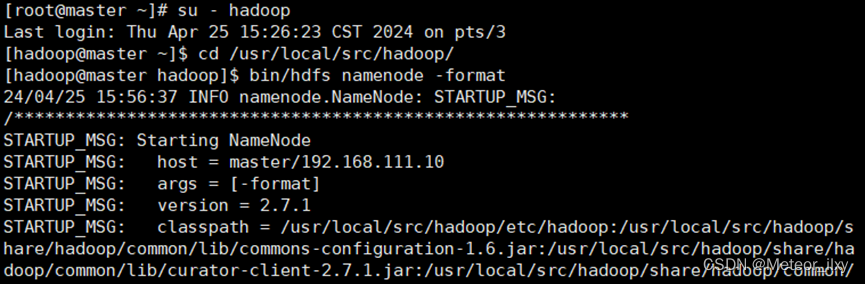
1,配置 Hadoop 格式化
1),NameNode 格式化
2),启动 NameNode

2,查看 Java 进程
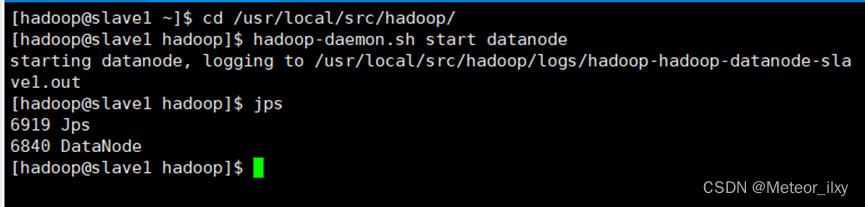
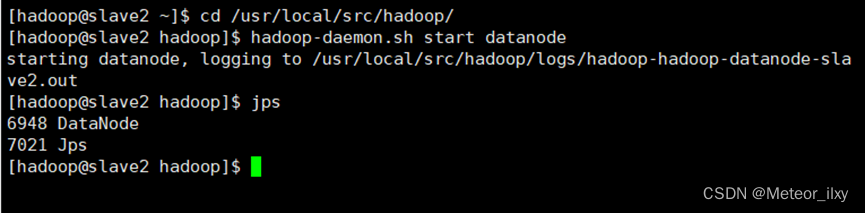
1),slave节点 启动 DataNode
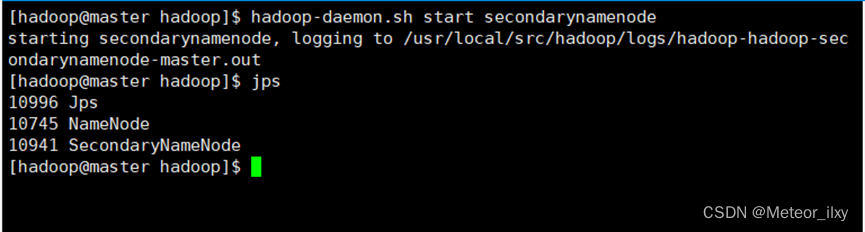
2),启动 SecondaryNameNode
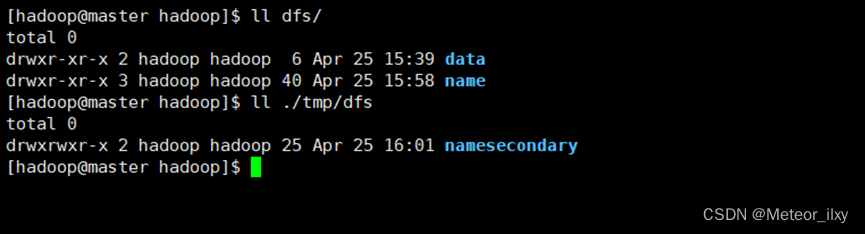
3),查看 HDFS 数据存放位置
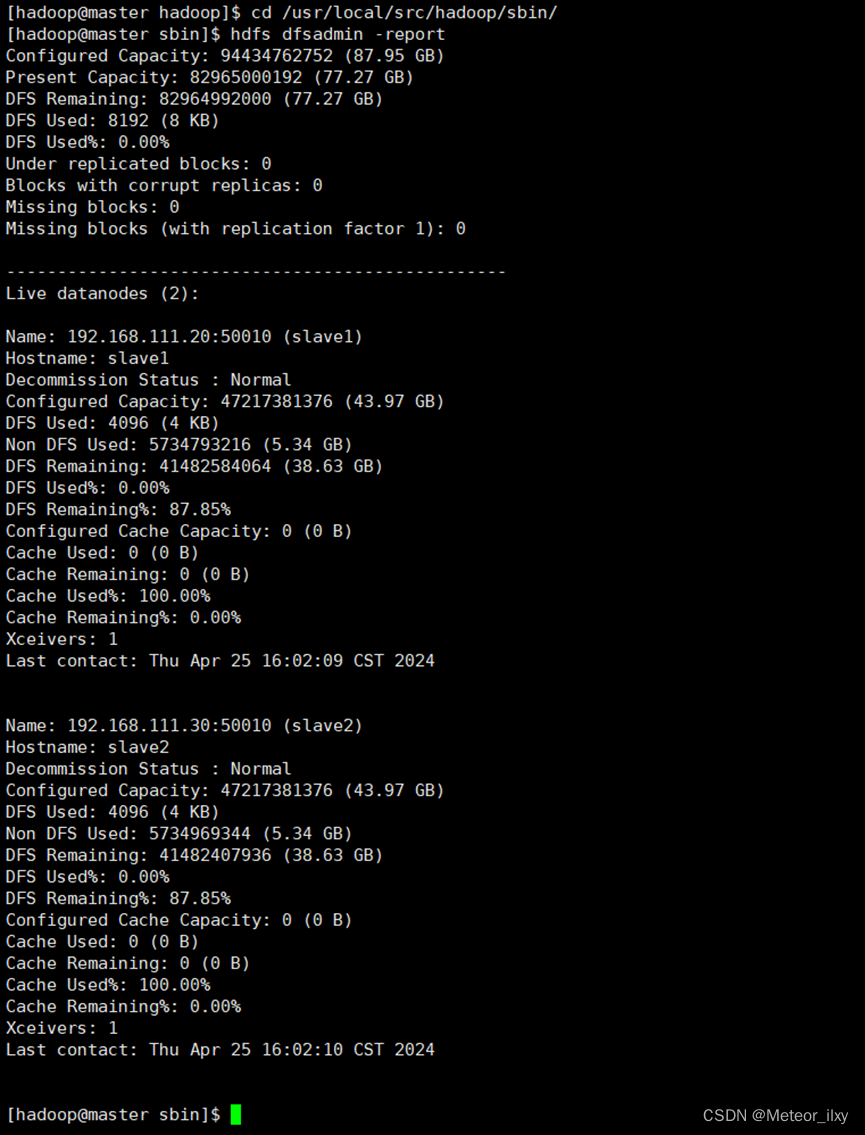
3,查看 HDFS 的报告
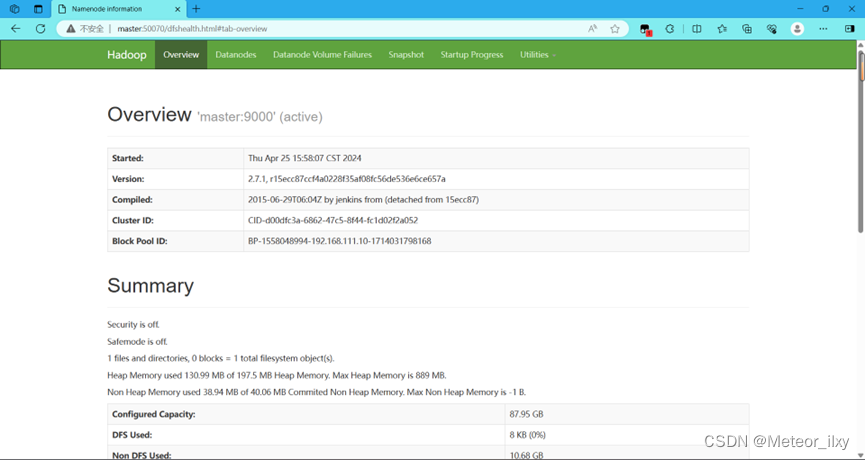
4,使用浏览器查看节点状态
在浏览器的地址栏输入http://master:50070,进入页面可以查看NameNode和DataNode 信息
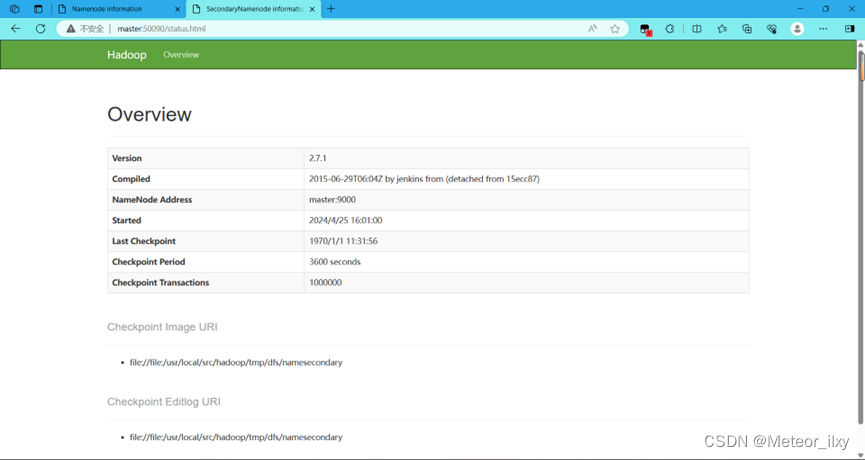
在浏览器的地址栏输入 http://master:50090,进入页面可以查看 SecondaryNameNode信息
五,Hive数据仓库组件
该操作可参考本人于四月八日发布的博客
六,大数据生态组件
Zookeeper组件与Hbase数据库组件
1,下载和安装 ZooKeeper
ZooKeeper 最新的版本可以通过官网 Apache ZooKeeper来获取
安装 ZooKeeper 组件需要与 Hadoop 环境适配
解压安装包到指定目标,在 Master 节点执行如下命令


2,ZooKeeper 的配置选项
1),在 ZooKeeper 的安装目录下创建 data 和 logs 文件夹

2),在每个节点写入该节点的标识编号,每个节点编号不同,master 节点写 入 1,slave1 节点写入 2,slave2 节点写入 3

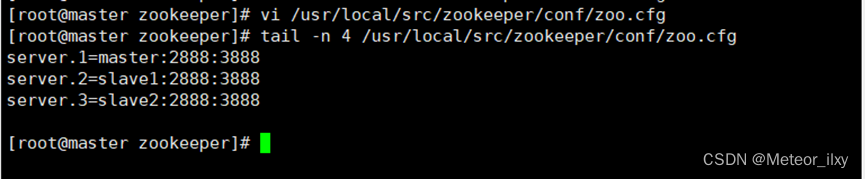
3),修改配置文件 zoo.cfg


4),在 zoo.cfg 文件末尾追加以下参数配置,表示三个 ZooKeeper 节点的访问端口号
5),修改 ZooKeeper 安装目录的归属用户为 hadoop 用户

6),从 Master 节点复制 ZooKeeper 安装目录到两个 Slave 节点


7),slave节点配置
在 slave1 节点上修改 zookeeper 目录的归属用户为 hadoop 用户

在 slave1 节点上配置该节点的 myid 为 2

在 slave2 节点上修改 zookeeper 目录的归属用户为 hadoop 用户

在 slave2 节点上配置该节点的 myid 为 3

8),系统环境变量配置
在 master、slave1、slave2 三个节点增加环境变量配置

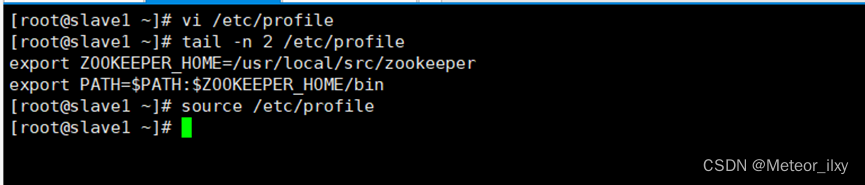
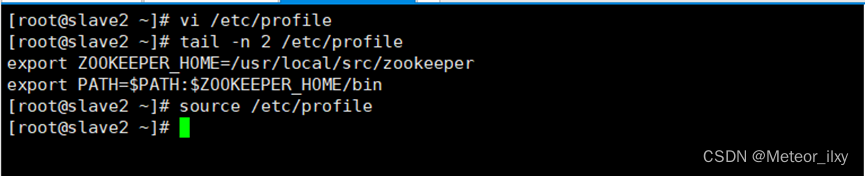
3,启动 ZooKeeper
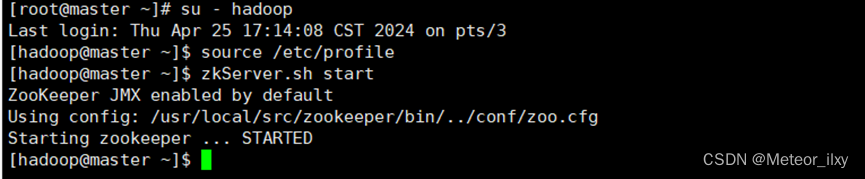
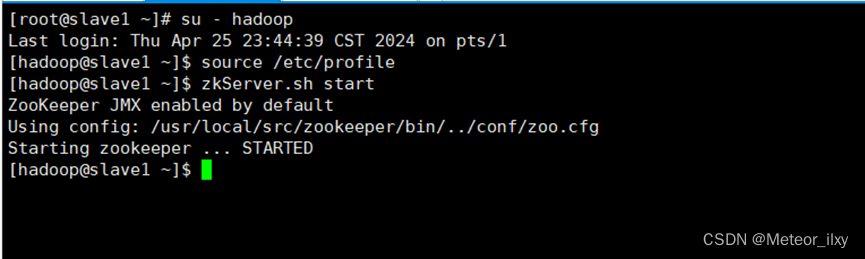
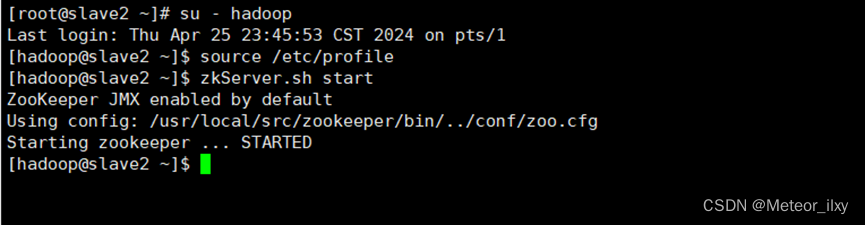
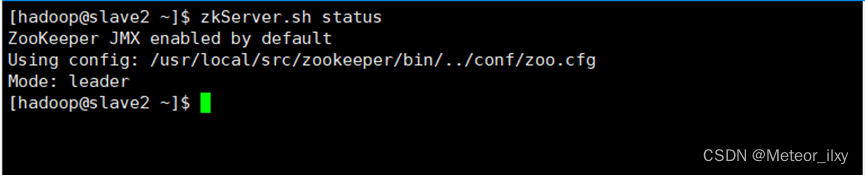
三个节点都启动完成后,再统一查看 ZooKeeper 运行状态


4,Hbase 安装与配置
1),解压缩 HBase 安装包

2),重命名 HBase 安装文件夹

3),在所有节点添加环境变量,并生效

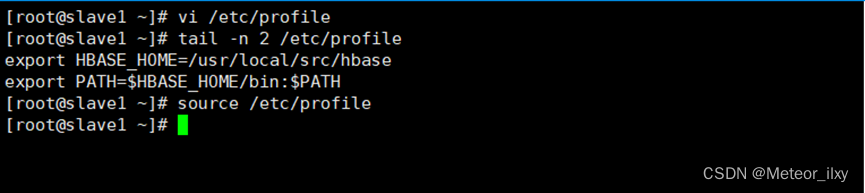
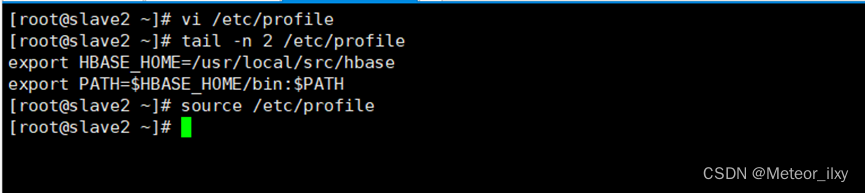
4),在 master 节点进入配置文件目录

5),在 master 节点配置 hbase-env.sh 文件



6),在 master 节点配置 hbase-site.xml 如下
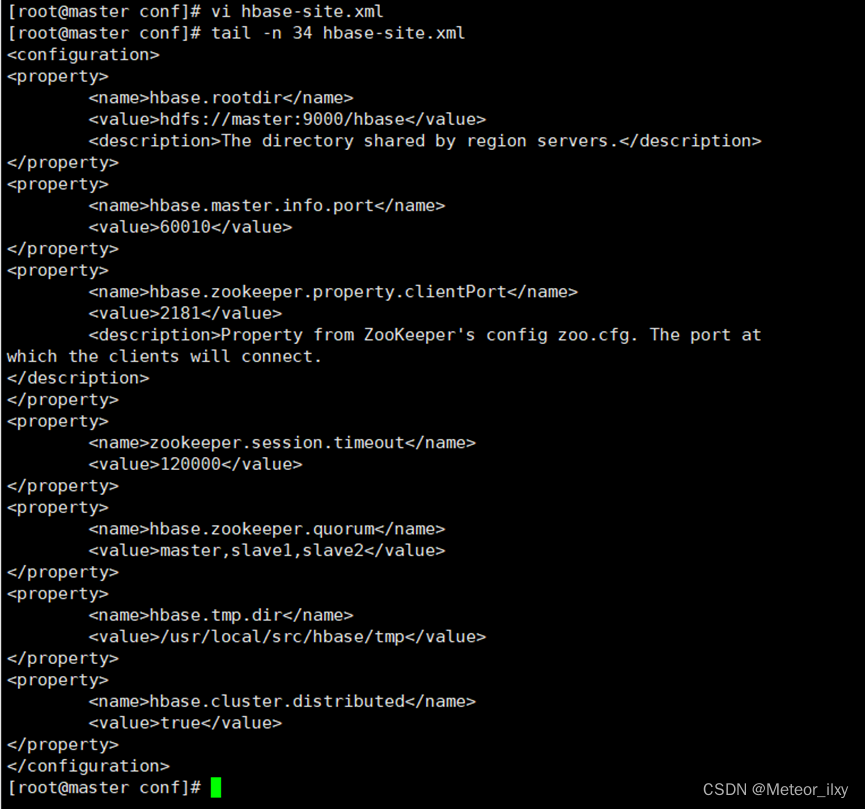
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value> # 使用 9000 端口
<description>The directory shared by region servers.</description>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value> # 使用 master 节点 60010 端口
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value> # 使用 master 节点 2181 端口
<description>Property from ZooKeeper's config zoo.cfg. The port at
which the clients will connect.
</description>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value> # ZooKeeper 超时时间
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value> # ZooKeeper 管理节点
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/src/hbase/tmp</value> # HBase 临时文件路径
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value> # 使用分布式 HBase
</property>
</configuration>
7),在 master 节点修改 regionservers 文件

8),在 master 节点创建 hbase.tmp.dir 目录

9),将 master 上的 hbase 安装文件同步到 slave1 slave2


10),在所有节点修改 hbase 目录权限

11),在所有节点切换到 hadoop 用户,启动 HBase,和ZooKeeper
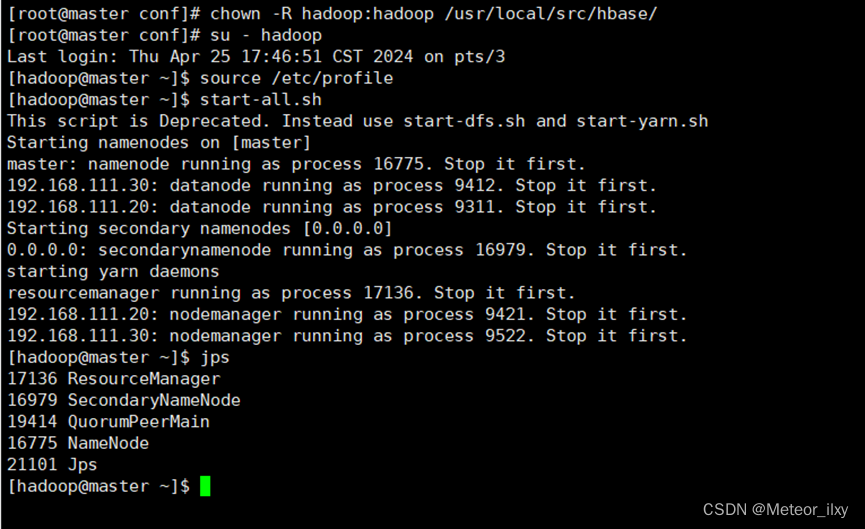
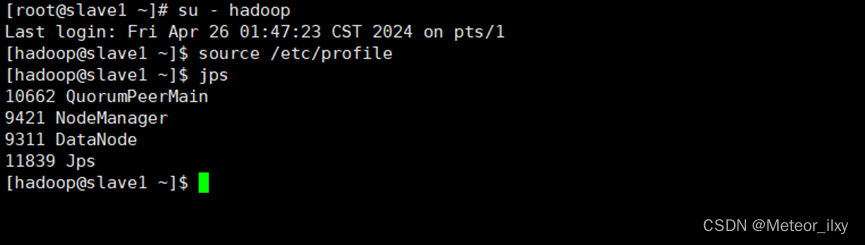
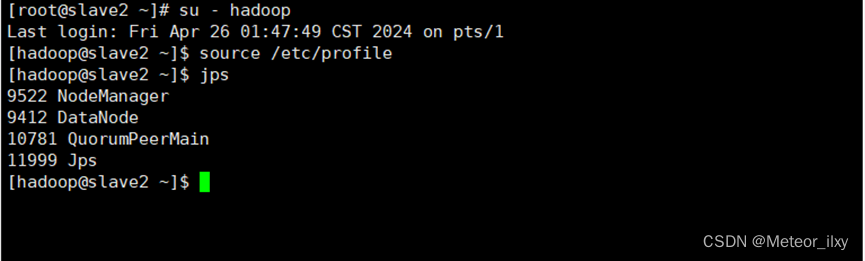
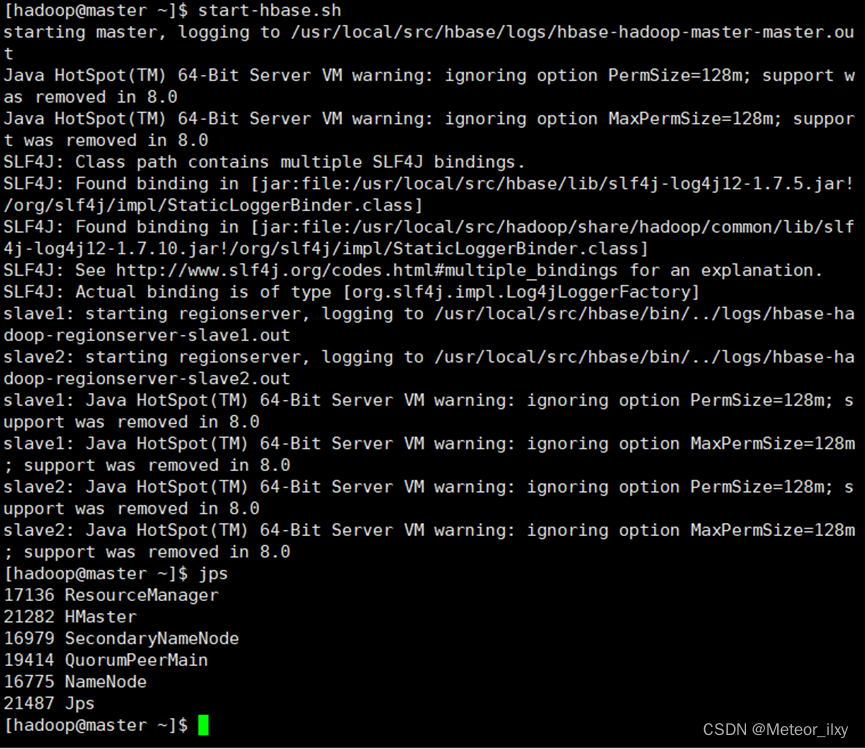
12),在 master 节点启动 HBase


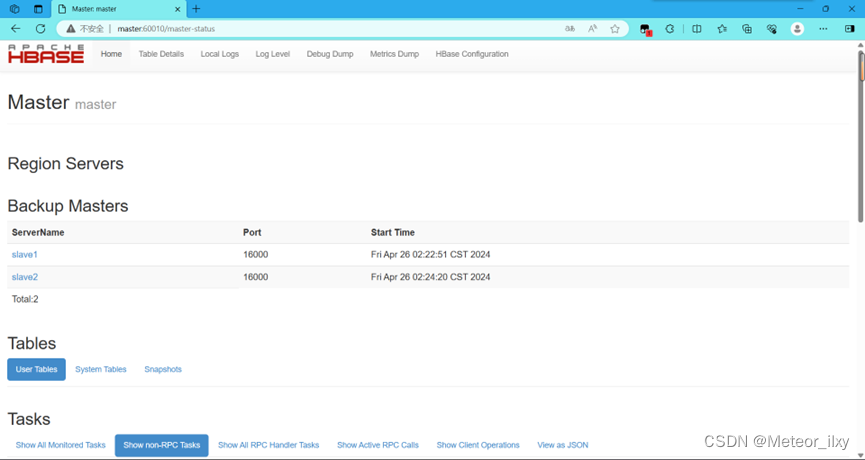
13),在浏览器输入 master:60010 出现如下图所示的界面















 7542
7542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









