







SimSiam论文阅读
介绍
SimSiam是一种自监督学习方法的结构,是基于Siamese networks结构提出的
创新点
- 没有使用负样本
- 没有依赖大的batch size
- 没有使用momentum encoders(不同于BYOL)
方法与实现
-
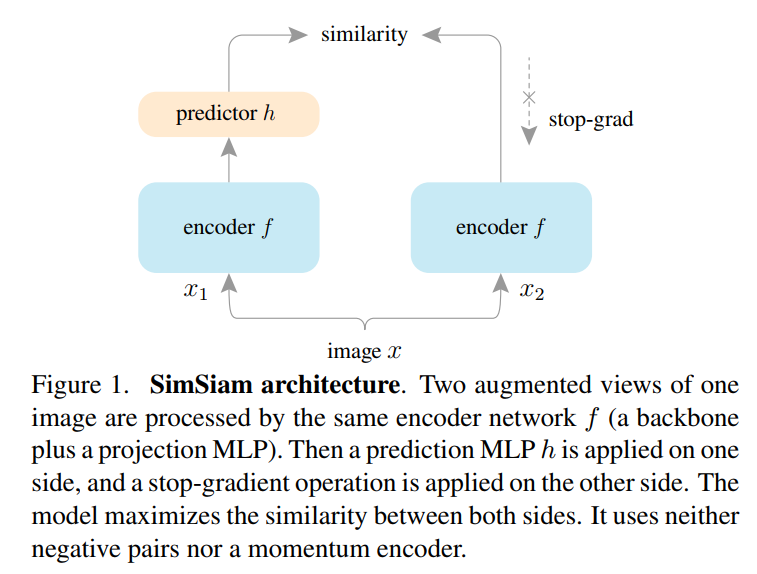
结构
- 两层网络结构基本相同,并且共享参数
- 对比于BYOL,将backone和projection MLP合并成一个encoder
- backone为ResNet-50
- MLP有3层,BN应用于每个FC,输出没有使用ReLU,隐藏层的FC为2048-d
- 左边network接了一层MLP作为predictor,右边network使用stop-grad阻断了梯度的反向传播
- MLP有2层,BN应用于每个隐藏层FC,输出没有使用ReLU和BN
- predictior h与BYOL中的相似,将左边encoder的输出向右边encoder的输出预测,计算二者之间的相似度
- 使用SGD优化器
-
基本训练流程

- input image 通过两种不同的图像增强方式,生成两张不同的image, x 1 x_1 x1和 x 2 x_{2} x2,将 x 1 x_1 x1和 x 2 x_{2} x2分别传进两个网络中
- 由于两个网络共享参数,使用同一个f()函数
- 然后通过MSE计算loss,计算梯度,更新encoder
LOSS
最小化负余弦相似度
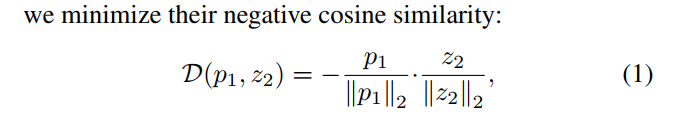
计算loss
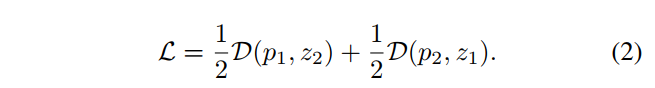
stop-grad


实验
测试stop-grad的影响
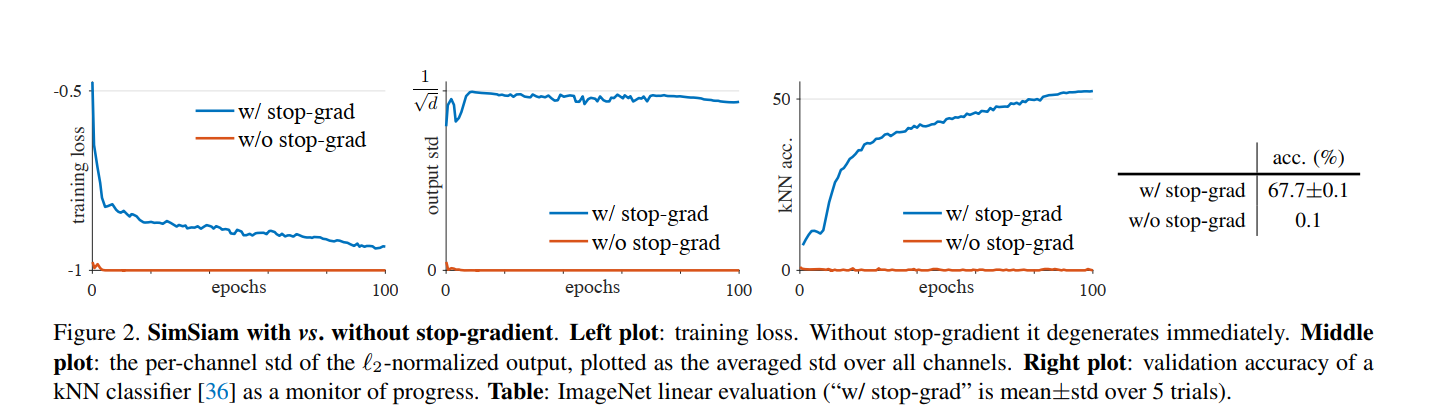
由于两个network共享参数,没有stop-grad将导致两个网络基本相同,从而引起坍塌,没有学习到有用的特征
测试predictor的影响

没有predictor,相当没有使用stop-grad,从而导致坍塌
使用固定随机初始化的MLP,模型失效的不是因为坍塌,而是因为训练无法收敛
lr不减小的效果更好,作者觉得可能是因为predictor可以更好地适应最新的表征
测试batch size
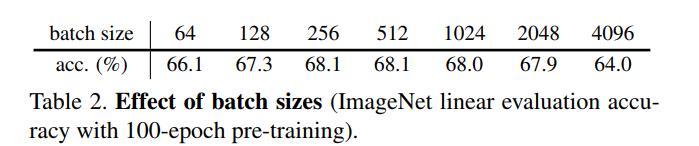
说明了SimSiam不依赖大的batch size
测试BN
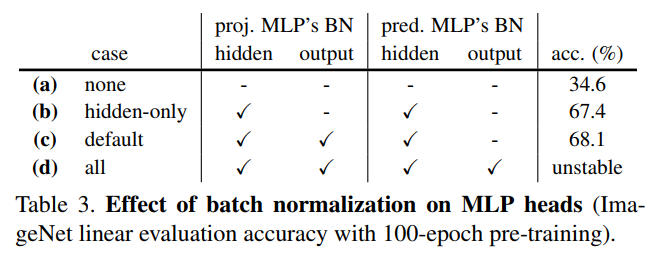
测试projection和predictor中的BN对SimSiam的影响,说明了BN可能是影响了SimSiam的优化,而不会导致SimSiam的坍塌
测试不同Similarity Function的效果
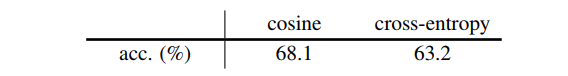
cross-entropy效果虽然没有consine好,但SimSiam整体同样可以work
测试Symmetrization的影响

虽然效果差一些,但是不对称的loss也可以work
结论
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bFKkNqha-1628602867138)(SimSiam/image-20210810142806378-162857688886111.png)]
通过以上的一些实验,作者排除了optimizer,BN,similarity function,symmetrization等因素对SimSiam是否坍塌的影响。于是,作者假设SimSiam是否坍塌的关键在于stop-grad
性能
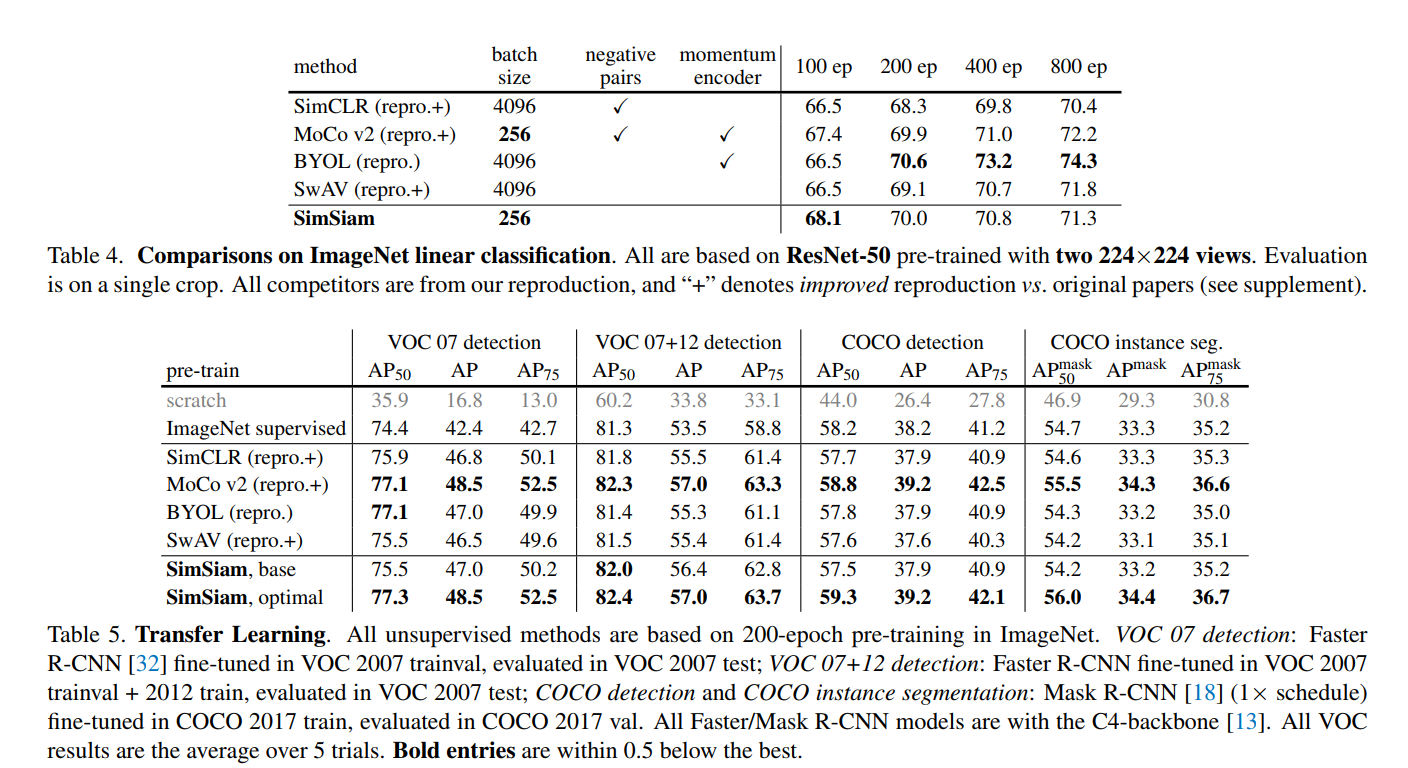
避免坍塌
作者提出了,SimSiam类似于EM算法
EM算法
T表示图像增强, η x \eta_x ηx表示图像x的表征,F表示network, θ \theta θ表示网络参数
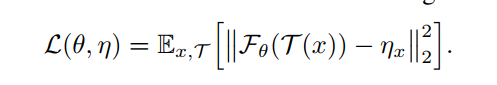
在训练过程,希望找到 θ \theta θ和 η \eta η使得loss的期望最小,也就是说,预测得到的图像x的位置要和图像实际存在的位置 η x \eta_x ηx越接近越好
固定一边的参数,不断优化另一边的参数,这就相当于SimSiam中的stop-grad
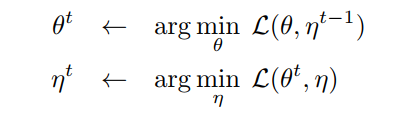
这是网络中没有predictor的部分
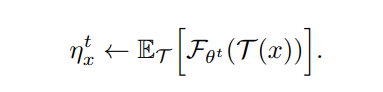
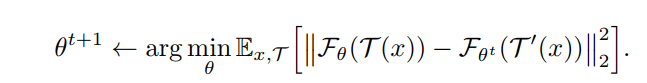
T ’ T’ T’是上个周期训练使用的图像增强策略
网络中predictor的任务就是最小化
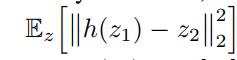
因此满足
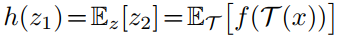

















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









