






http://blog.csdn.net/myarrow/article/details/52064608
1. 基本概念
1.1 MXNet相关概念
深度学习目标:如何方便的表述神经网络,以及如何快速训练得到模型
CNN(卷积层):表达空间相关性(学表示)
RNN/LSTM:表达时间连续性(建模时序信号)
命令式编程(imperative programming):嵌入的较浅,其中每个语句都按原来的意思执行,如numpy和Torch就是属于这种
声明式语言(declarative programing):嵌入的很深,提供一整套针对具体应用的迷你语言。即用户只需要声明要做什么,而具体执行则由系统完成。这类系统包括Caffe,Theano和TensorFlow。命令式编程显然更容易懂一些,更直观一些,但是声明式的更利于做优化,以及更利于做自动求导,所以都保留。
| 浅嵌入,命令式编程 | 深嵌入,声明式编程 | |
| 如何执行a=b+1 | 需要b已经被赋值。立即执行加法,将结果保存在a中。 | 返回对应的计算图(computation graph),我们可以之后对b进行赋值,然后再执行加法运算 |
| 优点 | 语义上容易理解,灵活,可以精确控制行为。通常可以无缝的和主语言交互,方便的利用主语言的各类算法,工具包,bug和性能调试器。 | 在真正开始计算的时候已经拿到了整个计算图,所以我们可以做一系列优化来提升性能。实现辅助函数也容易,例如对任何计算图都提供forward和backward函数,对计算图进行可视化,将图保存到硬盘和从硬盘读取。 |
| 缺点 | 实现统一的辅助函数和提供整体优化都很困难。 | 很多主语言的特性都用不上。某些在主语言中实现简单,但在这里却经常麻烦,例如if-else语句 。debug也不容易,例如监视一个复杂的计算图中的某个节点的中间结果并不简单。 |
1.2 深度学习的关键特点
(1)层级抽象
(2)端到端学习
2. 比较表
| 比较项 | Caffe | Torch | Theano | TensorFlow | MXNet |
| 主语言 | C++/cuda | C++/Lua/cuda | Python/c++/cuda | C++/cuda | C++/cuda |
| 从语言 | Python/Matlab | - | - | Python | Python/R/Julia/Go |
| 硬件 | CPU/GPU | CPU/GPU/FPGA | CPU/GPU | CPU/GPU/Mobile | CPU/GPU/Mobile |
| 分布式 | N | N | N | Y(未开源) | Y |
| 速度 | 快 | 快 | 中等 | 中等 | 快 |
| 灵活性 | 一般 | 好 | 好 | 好 | 好 |
| 文档 | 全面 | 全面 | 中等 | 中等 | 全面 |
| 适合模型 | CNN | CNN/RNN | CNN/RNN | CNN/RNN | CNN/RNN? |
| 操作系统 | 所有系统 | Linux, OSX | 所有系统 | Linux, OSX | 所有系统 |
| 命令式 | N | Y | N | N | Y |
| 声明式 | Y | N | Y | Y | Y |
| 接口 | protobuf | Lua | Python | C++/Python | Python/R/Julia/Go |
| 网络结构 | 分层方法 | 分层方法 | 符号张量图 | 符号张量图 | ? |
3.详细描述
3.1 MXNet
MXNet的系统架构如下图所示:
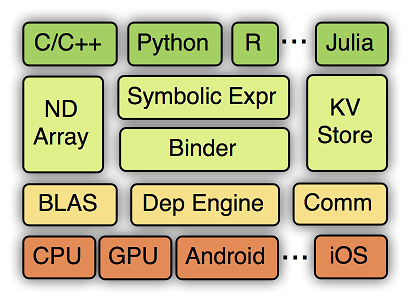
从上到下分别为各种主语言的嵌入,编程接口(矩阵运算,符号表达式,分布式通讯),两种编程模式的统一系统实现,以及各硬件的支持。
MXNet的设计细节包括:符号执行和自动求导;运行依赖引擎;内存节省。
3.2 Caffe
优点:
1)第一个主流的工业级深度学习工具。
2)它开始于2013年底,由UC Berkely的Yangqing Jia老师编写和维护的具有出色的卷积神经网络实现。在计算机视觉领域Caffe依然是最流行的工具包。
3)专精于图像处理
缺点:
1)它有很多扩展,但是由于一些遗留的架构问题,不够灵活且对递归网络和语言建模的支持很差。
2)基于层的网络结构,其扩展性不好,对于新增加的层,需要自己实现(forward, backward and gradient update)
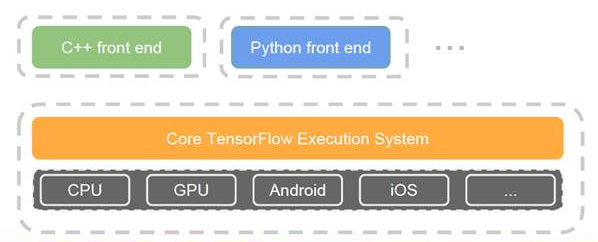
3.3 TensorFlow
优点:
1) Google开源的其第二代深度学习技术——被使用在Google搜索、图像识别以及邮箱的深度学习框架。
2)是一个理想的RNN(递归神经网络)API和实现,TensorFlow使用了向量运算的符号图方法,使得新网络的指定变得相当容易,支持快速开发。
3)TF支持使用ARM/NEON指令实现model decoding
4)TensorBoard是一个非常好用的网络结构可视化工具,对于分析训练网络非常有用
5)编译过程比Theano快,它简单地把符号张量操作映射到已经编译好的函数调用
缺点:
1) 缺点是速度慢,内存占用较大。(比如相对于Torch)
2)支持的层没有Torch和Theano丰富,特别是没有时间序列的卷积,且卷积也不支持动态输入尺寸,这些功能在NLP中非常有用。
3.4 Torch
优点:
1)Facebook力推的深度学习框架,主要开发语言是C和Lua
2)有较好的灵活性和速度
3)它实现并且优化了基本的计算单元,使用者可以很简单地在此基础上实现自己的算法,不用浪费精力在计算优化上面。核心的计算单元使用C或者cuda做了很好的优化。在此基础之上,使用lua构建了常见的模型
4)速度最快,见convnet-benchmarks
5)支持全面的卷积操作:
- 时间卷积:输入长度可变,而TF和Theano都不支持,对NLP非常有用;
- 3D卷积:Theano支持,TF不支持,对视频识别很有用
缺点
1)是接口为lua语言,需要一点时间来学习。
2)没有Python接口
3)与Caffe一样,基于层的网络结构,其扩展性不好,对于新增加的层,需要自己实现(forward, backward and gradient update)
4)RNN没有官方支持
3.5 Theano
优点:
1)2008年诞生于蒙特利尔理工学院,主要开发语言是Python
2)Theano派生出了大量深度学习Python软件包,最著名的包括Blocks和Keras
3)Theano的最大特点是非常的灵活,适合做学术研究的实验,且对递归网络和语言建模有较好的支持
4)是第一个使用符号张量图描述模型的架构
5)支持更多的平台
6)在其上有可用的高级工具:Blocks, Keras等
缺点:
1)编译过程慢,但同样采用符号张量图的TF无此问题
2)import theano也很慢,它导入时有很多事要做
3)作为开发者,很难进行改进,因为code base是Python,而C/CUDA代码被打包在Python字符串中
参考资料:
2)Evaluation of Deep Learning Toolkits
3)TensorFlow vs. Theano vs. Torch comparison
机器学习这个领域,从业者(特指技术类从业者,不包括资本类玩家)一定会分成三个不同的群体:
1.学术研究者
他们的工作是从理论上诠释机器学习的各个方面,试图找出“这样设计模型/参数为什么效果更好”,并且为其他从业者提供更优秀的模型,甚至将理论研究向前推进一步。
能够做到这一步的人,可以说凤毛麟角,天赋是绕不过去的大山,机遇和努力也缺一不可。
对于这些人,其实也轮不到我们来建议,在长期的研究中他们都有自己喜好的工具和方法,甚至有一言不合就自己开发工具甚至开发语言的(比如LeCun……)。
题主应该不属于这一层。
2.算法改进者
他们也许无法回答出“我的方法为什么work”,也许没有Hinton,LeCun那样足以载入史册的重大成果,但是却能根据经验和一些奇思妙想,将现有的模型玩出更好的效果,或者提出一些改进的模型。这些人通常都是各个机器学习巨头公司的中坚力量或者成长中的独角兽,使用什么模型对他们来讲也不是问题,根据所处的环境,通常都有固定的几个选择。他们其实也并不怎么需要关心“我该用什么框架”,重要的是什么框架能够快速地把想法实现出来。所以你会看到caffe和theano和mxnet和torch都一样有大批的用户,仍然在贡献大量的新算法的实现。在这个层面,insight和idea才是重要的东西,各种工具的区别,影响真的没那么大。可能会让一个结果早得到或者晚得到几天或者几周,却不可能影响“有没有成果”。
这也造成了另外一个结果:最最新,最最前沿的成果往往还是用caffe或者theano做出来,发paper,然后tensorflow才开始复现这些成果。搞不好很长一段时间之内也许tf上面都不会出现原生的新奇玩意儿。因为那些正在努力嗷嗷发论文的大中牛们时间非常宝贵,没有太多心思重新学习一种框架。
不过没关系,题主(至少目前)应该不属于这一层。
这些人基本上不会在算法领域涉入太深,也就是了解一下各个算法的实现,各个模型的结构。他们更多地是根据论文去复现优秀的成果,或者使用其他人复现出来的成果,并且试图去在工业上应用它。
这个层次的人数是最多的,涉及的因素也非常复杂。但是在框架选择上,其实完全可以用最单纯的原则: 哪个人多用哪个。
至于调试的方便性或者性能或者最新算法的实现能力,其实都与使用者数量相关。
人多了贡献代码的人就会更多,遇到问题时候能讨论的人也就更多,出现新的成果时,在这个框架上进行实现的的也就越多,同样的,为这个框架开发各种外围工具的人也会更多。目前这个阶段,TF的靠山最厚实,功能虽然还不强大,更新也还不够快,但是确实人气已经攒得很足了,一些外围的包装比如tflearn也实现了很多最新的成果。所以从目前来看,投身TF不会是一个坏选择,找工作的时候你遇到用tf的公司的可能性也是非常非常高的。
至于MXNet,这个年代早就不是胜者通吃的时候了,即使TF有google撑腰,也不可能“消灭”其他几个框架,更何况每个框架都有自己出彩的地方。现在流行的这几个框架都有一些算法改进层次的高手大牛支持着,他们很可能会继续使用正在用的框架。哪怕只有他们支持,也足够撑起一个框架的生命力了,更何况他们的号召力还颇为可观。
我就是第三类人,工业实现者。所以我这个回答是从工业界角度来讲的,至少是从我所在的公司的角度来说说。
结论先说出来,在工业界TensorFlow将会比其他框架更具优势。
大家从机器学习算法研发的角度讲了很多,很多观点我也表示赞同。但是很多人忽略了重要的一点,那就是Google旗下的Android的市场份额和影响力。要知道,不管机器学习研发进行的多么火热,要转化为生产力和利润,最终需要落实到产品。目前来看,机器学习的应用归宿可粗略的划分为两类:部署于服务器端的大规模数据挖掘,为大数据服务的;另一类就是直接面向终端用户的移动端。
这两块可以说Google都不比任何人弱。首先,服务器端没什么可说的,Google拿手好戏。此外,服务器上大规模机器学习的应用各家都有自己的看家本领,比如Facebook、Twitter、Linkedin、Netflix、Amazon等等,一般各家也都有内部研发项目,用什么工具外界也不得而知,但不管怎么讲这部分毕竟数量有限,而且这些内部项目回馈开源项目的可能性较低(FB和Amazon有开源框架,但我上面说的这几个公司只是成百上千的互联网公司的一小部分,大部分用机器学习的公司事实上没有任何开源行为),因而对开源机器学习框架的格局影响不大。
而移动端,目前的需求以终端上的inference的部署为主,比如用户手机上的图像识别等应用。移动计算市场对于机器学习的需求是极其强劲的,这部分巨大的需求将会铸就一个空前规模的市场,而机器学习则是这其中不可或缺的一环。依托Android生态圈存活的不计其数的公司自然也不会放弃这个巨大的蛋糕。
在移动这一块,借助Android的巨大影响力,开发者在选择开源框架时,势必会优先选择有Google背书的TF。再加上TF标榜的“移动设备作为第一公民”的开发理念(有待于时间的检验),以及目前TF官方支持Android和iOS两大移动平台来看,选择TF将会是开发者的理性选择。此外,Google力推模型压缩和8bit低精度数据存储,除了对训练系统本身优化的作用,显然在某种程度上会使算法在移动设备上的部署收益多多,这些优化举措带来的存储需求的降低,内存带宽要求的降低,以及性能的提升,对移动设备的性能和功耗的帮助要远比在桌面或服务器系统上大的多。
简单说说移动计算这块的现状。iOS生态圈用苹果的自研SoC芯片,GPU加速靠Metal。而另一边,Android阵营芯片厂商主要有高通、三星、联发科、华为等。NVIDIA的Tegra已经明确退出移动市场(手机、平板、可穿戴设备等),转而主攻车载芯片;因此在手机端我们已经不可能看到任何设备支持CUDA。所以Android生态圈的芯片基本架构就是ARM CPU(除高通是用自己研发的处理器体系结构,各家都用的是公版ARM CPU)+ 移动GPU(高通用自研Adreno GPU,其他家大多用ARM的Mali GPU,少量Imagination的PowerVR GPU)。在Android阵营,GPU通用计算主要靠OpenCL来挑大梁(各家中/高端GPU均支持OpenCL);Google的RenderScript由于种种原因变得非常鸡肋,几乎没有开发者使用;而从Android N开始,Vulkan也会成为逐渐成为GPU通用计算的中坚力量。一句话总结下来就是,要想在Android上实现对机器学习框架的GPU加速,必须首先把机器学习框架移植到OpenCL或Vulkan上去,并且投入大量的精力针对硬件体系结构进行有针对性的优化,才有可能实现机器学习在移动平台的高效部署。
从我司视角来看,目前高通在机器学习上的战略很清楚,全力支持自己的Snapdragon Machine Learning SDK和Google的TensorFlow。为达到此目标,已经调动起SoC的所有相关部件,试图最大化的推动深度机器学习在移动设备上的应用。包括CPU、GPU(OpenCL,SYCL等)、DSP(HVX)在内的异构多核计算平台已经纷纷投入资源开始对TF进行有针对性的优化。并且从应用层面、系统硬件、甚至编译器等多方面给予支援。
此外,在工业界,还有Codeplay这样很牛的代码工厂作为partner很严肃向TF的贡献代码,推动异构平台上TF的各种实现和优化。(详见6月1日Codeplay发布的技术博客,codeplay.com 的页面)
综上,从工业界的角度来看这几大软件框架,TF的前景相对更好一点。虽然我个人很喜欢Caffe,也很敬佩各位中国学者为推动的MX做出的不懈努力,也乐于看到开源社区百花齐放的繁荣景象,但客观的从工业界的现状来看,TF背靠Google这课大树目前来看优势明显。更何况Google手中还有TPU这样的硬件,说不定它哪天急了,开卖TPU了呢(虽然可能性较小,但万事皆有可能)。广告词我都给想好了,“配合使用,效果更佳”,ヽ(^。^)丿。















 3007
3007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









