






1、部署平台
本项目部署平台为趋动云,趋动云平台是一款一站式全流程人工智能平台。
平台打通模型开发与训练,原生支持多机多卡训练环境,优化 AI 场景下 IO 吞吐、持久化、结构化维护模型生产信息,优化数据资源共享路径,最终提高平台整体资源利用率,消除信息孤岛,大幅提高 AI 算法工程师工作效率,使其聚焦于算法与模型开发的核心工作,利用有限的资源更快挖掘商业价值与远见洞察。
2、项目准备
2.1、准备代码、模型
2.1.1、代码获取
从GitHub中Facebook官方项目中下载或命令行拉取:
git clone -b llama_v2 https://github.com/facebookresearch/llama.git
clone 的代码目录名为llama,为方便后续命令可直接复制执行,建议修改为llama2后再打包上传到平台。
2.1.2、模型文件获取
平台中已经预置了 llama-2-7B、llama-2-7B-chat 模型文件,创建项目时可选择直接挂载。
3、创建项目
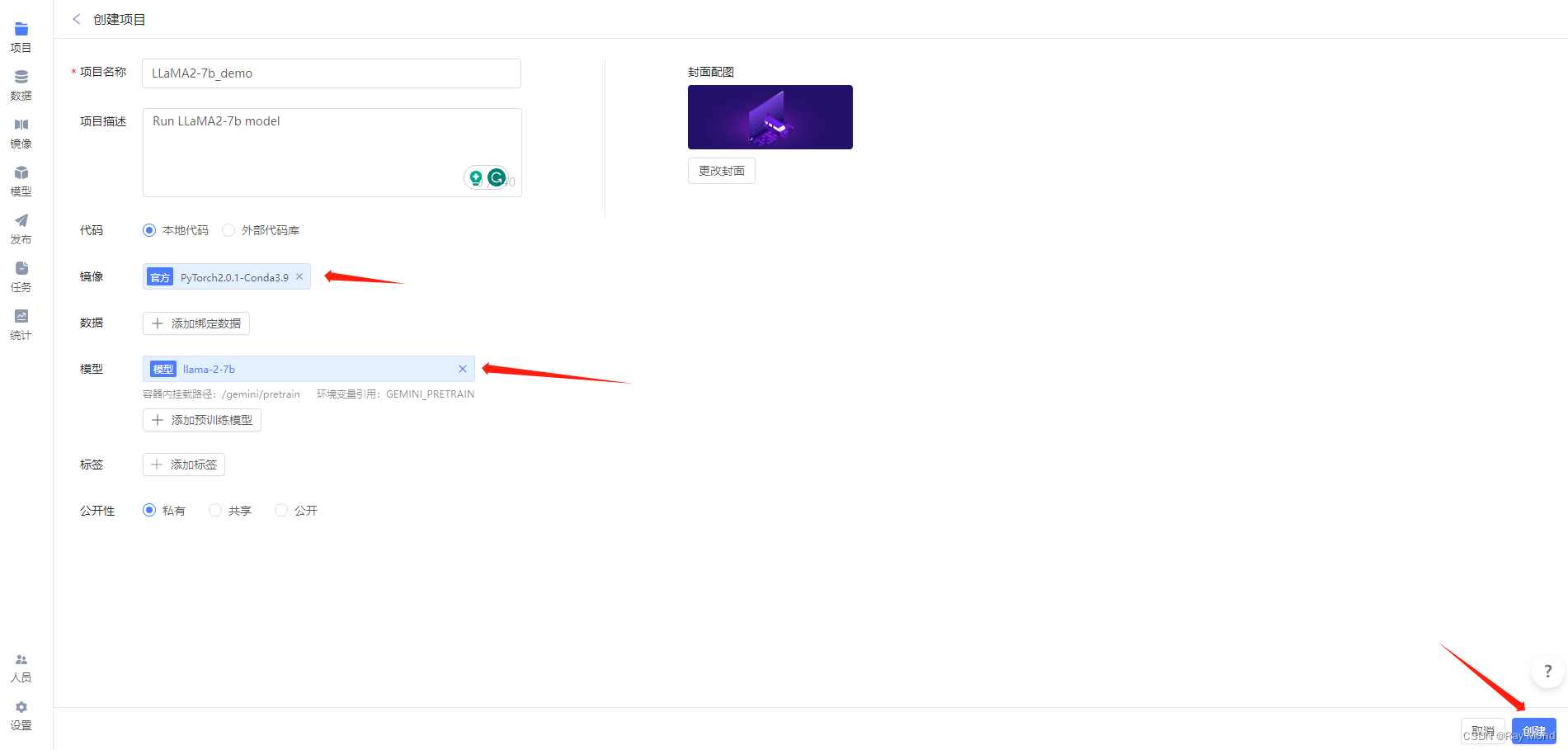
3.1、在右上角“项目”中,单击“创建项目”

3.2、填写必要信息
项目名称:可自定义,如 “LLaMA2-7b_demo”。
代码:选择本地代码(见2.1.1)。
镜像:选择官方镜像 PyTorch 2.0.1(PyTorch1.10以上的镜像均可)。
模型:选择公开下的 llama-2-7b 和 llama-2-7b-chat(作者均为“趋动云小助手”)。
最后,点击“创建”。
创建项目后,会立刻出现上传代码弹窗:
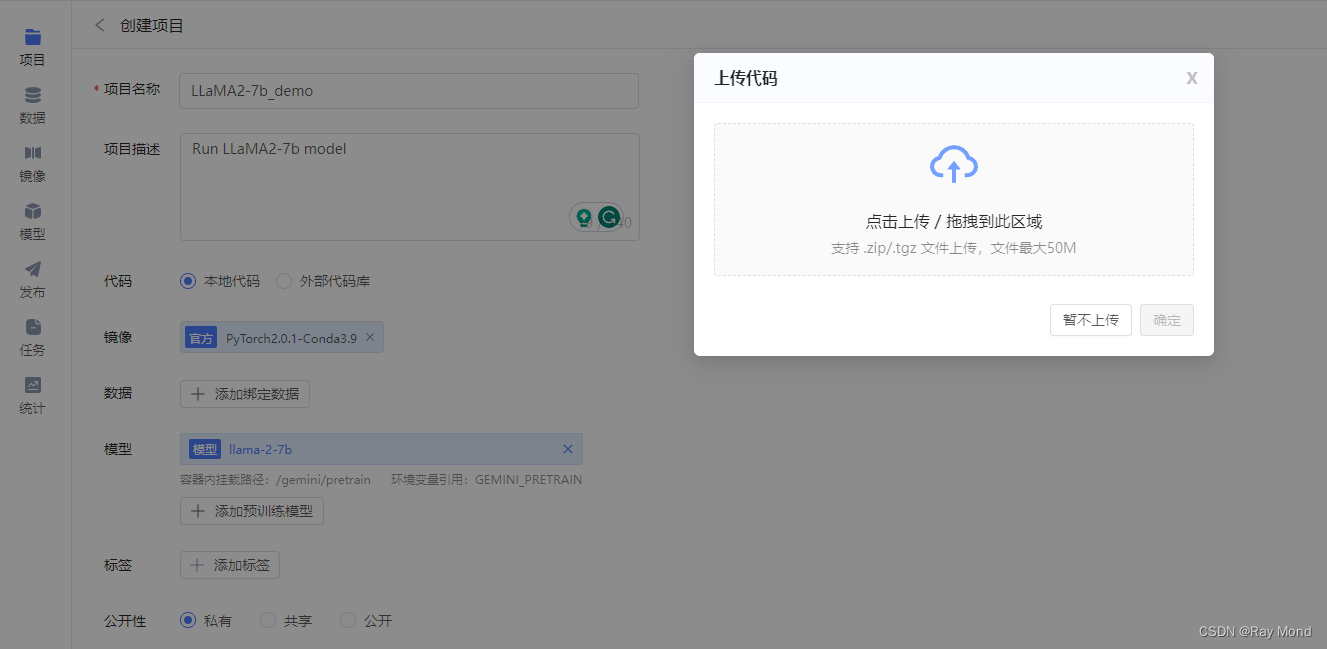
将之前下载到本地的代码上传,单击“确定”,则代码上传成功!
然后,单击左侧导航栏的“数据”选项:
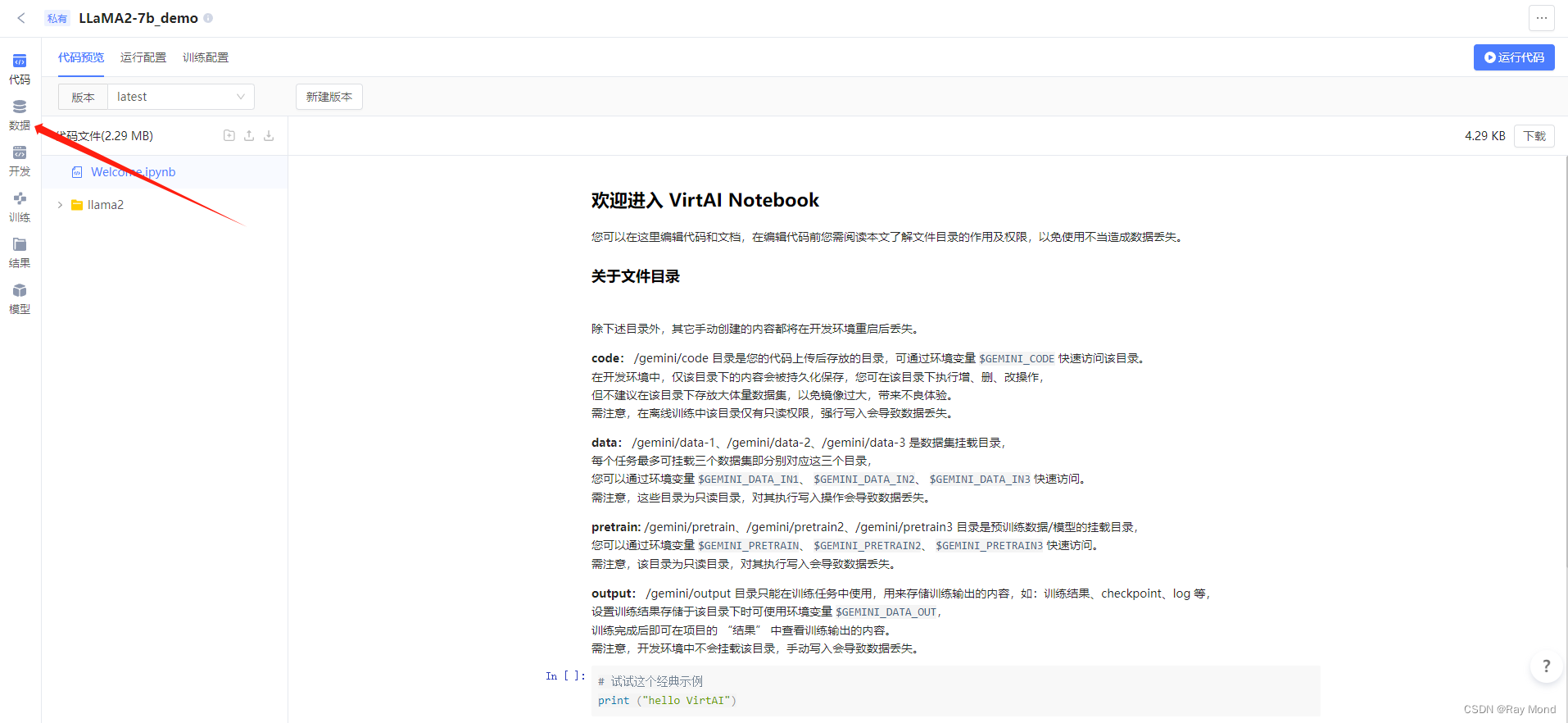
可以查看挂载的具体模型及其挂载的路径:
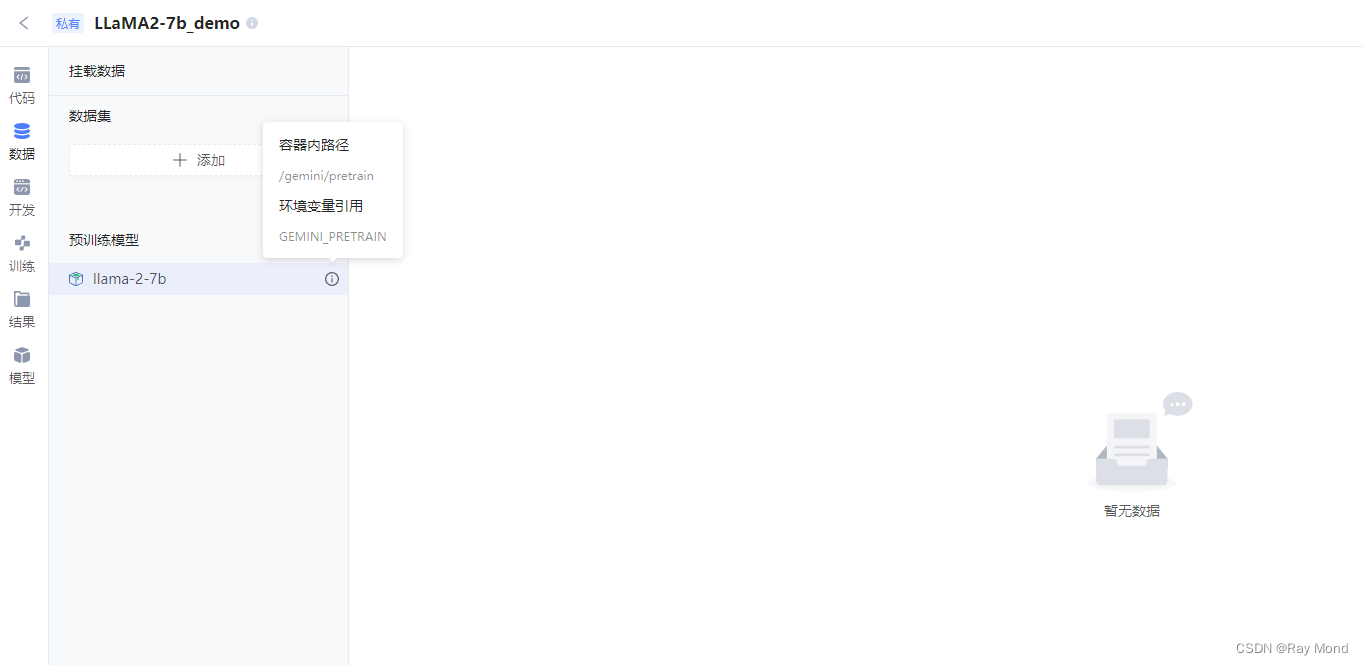
4、环境准备
4.1、左侧导航栏选择“开发”,随后单击“初始化开发环境实例”
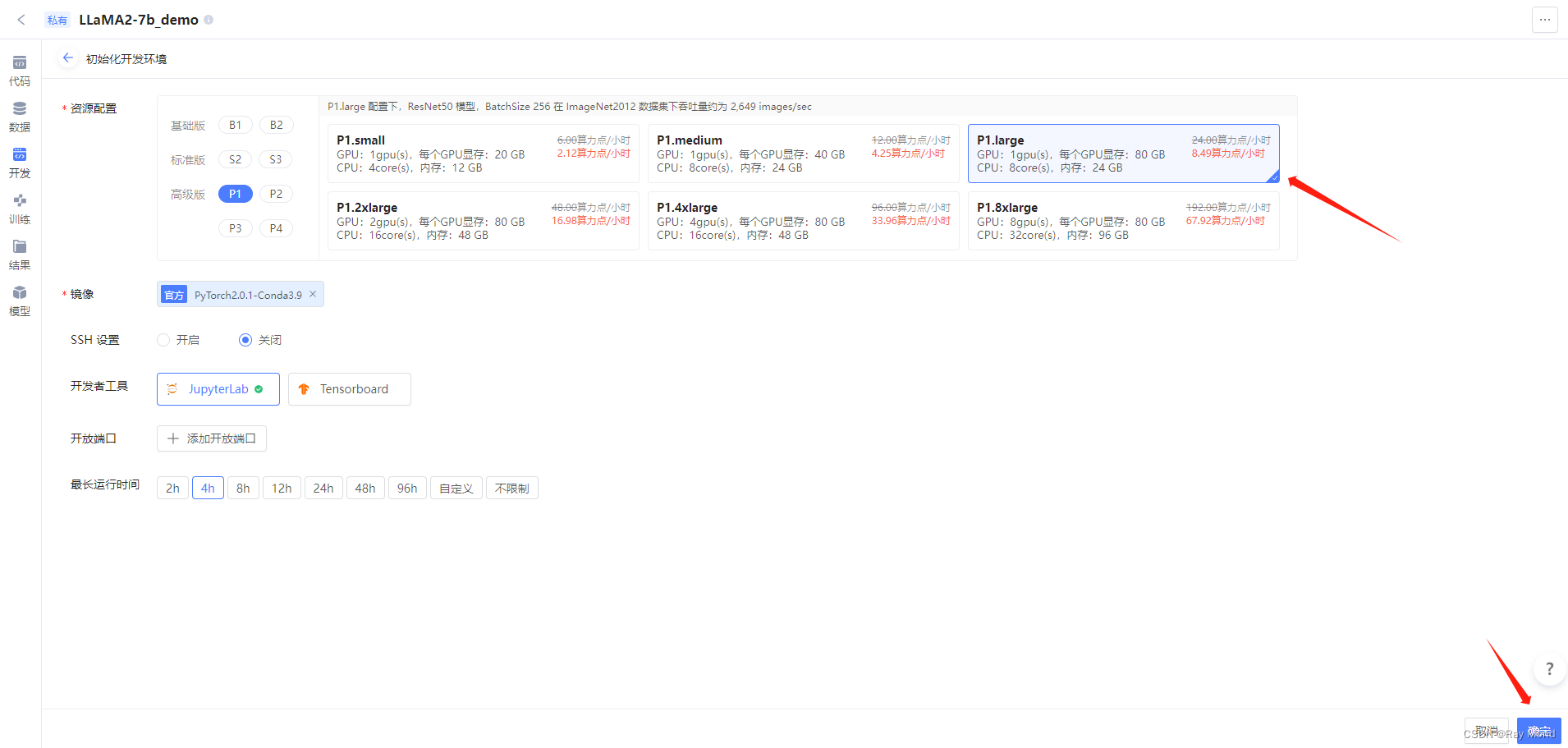
此过程需要填写开发环境相关配置,然后点击“确定”。
4.2、安装第三方包/工具
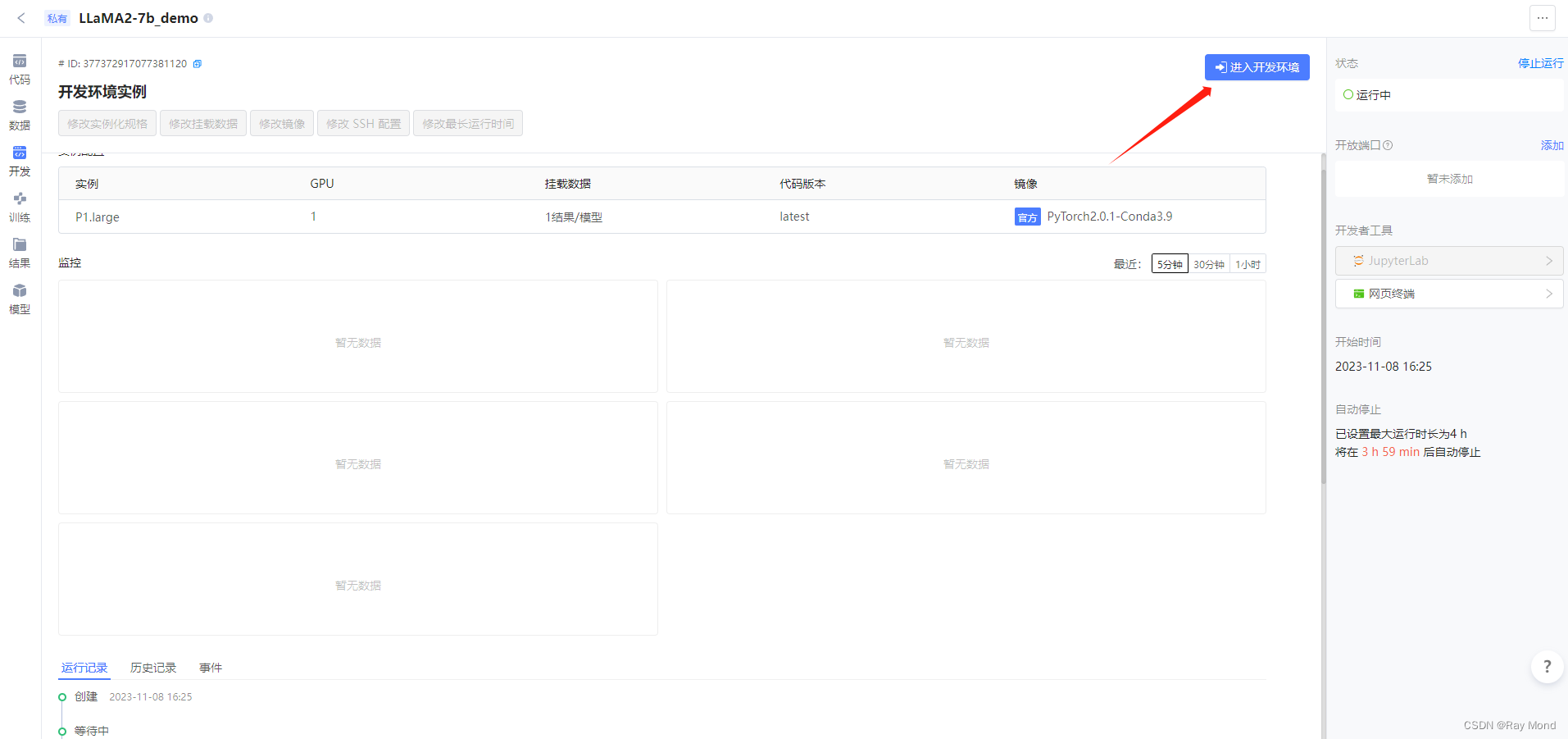
官方镜像PyTorch2.0.1中虽已预置 AI 常用工具及依赖包,但要加载LLaMA2,还需补充安装相关包。首先进入开发环境:
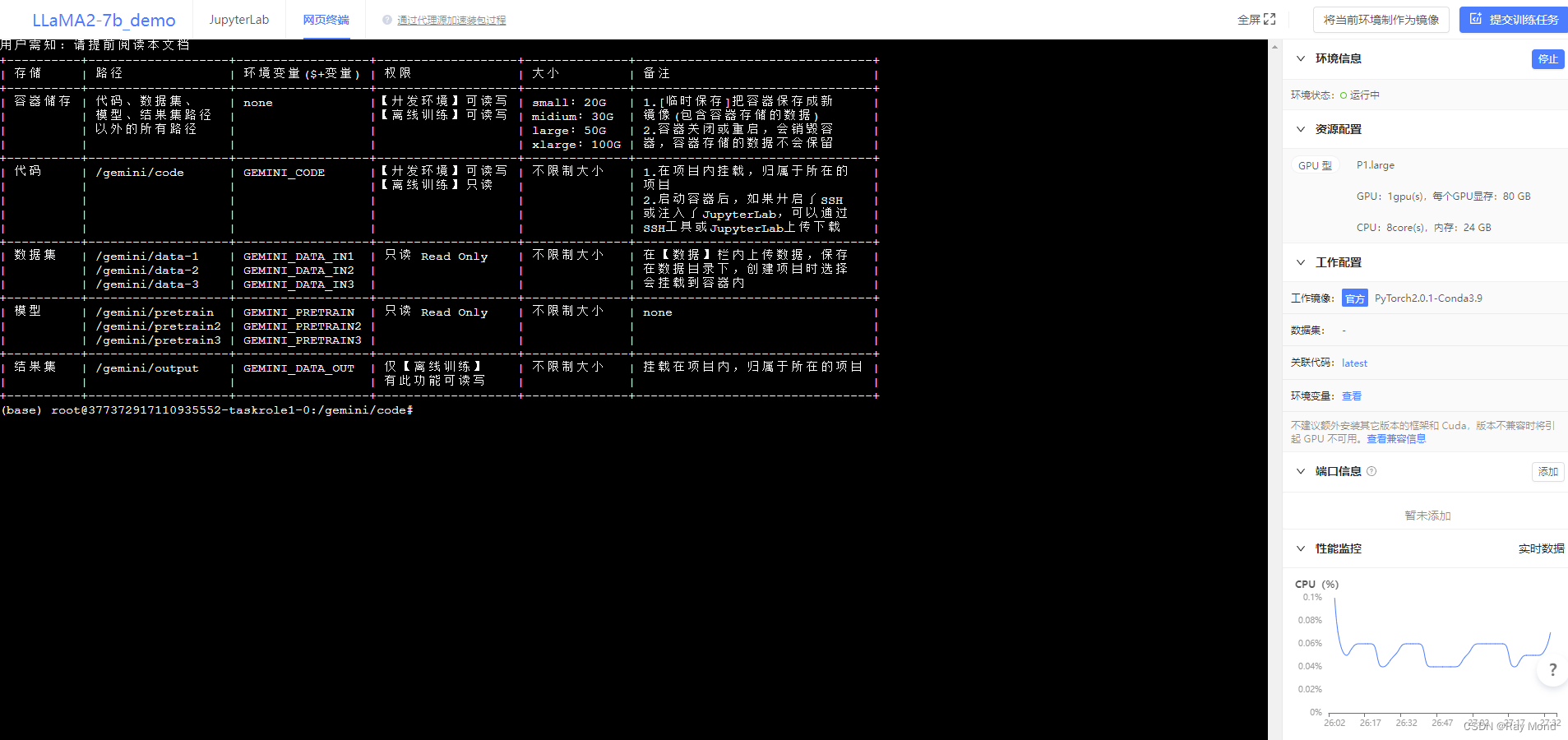
切换至网页终端:
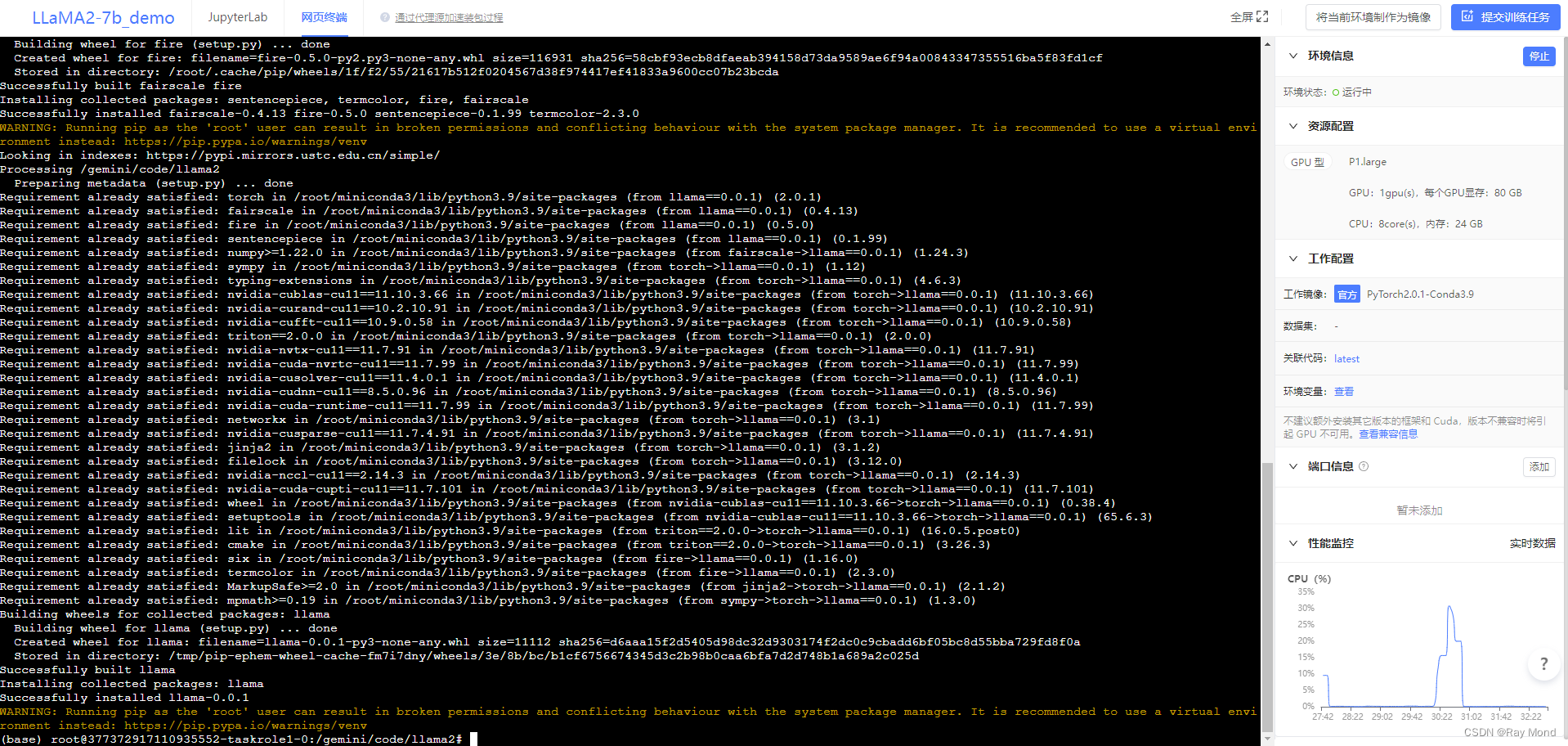
并执行如下命令:
cd llama2 && \
pip install -r requirements.txt -i https://pypi.virtaicloud.com/repository/pypi/simple && \
pip install .
安装过可能需要等待一小段时间,等待约 1 分钟执行完,执行过程中无 error 报错,则安装成功。
5、运行LLaMA2
LLaMA2 提供了两个推理体验的 demo,可以分别进行体验。
- 句子补全:基于基础模型(llama-2-7b),使用 example_text_completion.py 代码加载模型进行推理。
- 对话生成:基于微调后的对话模型(llama-2-7b-chat),使用 example_chat_completion.py 代码加载模型进行推理。
推理:代码中已提供了默认输入,直接在网页终端执行下述命令,会按默认输入加载模型并推理。当然,也可以修改输入。
5.1、句子补全
torchrun --nproc_per_node 1 example_text_completion.py --ckpt_dir /gemini/pretrain/llama-2-7b/ --tokenizer_path /gemini/pretrain/tokenizer.model
5.2、对话生成
torchrun --nproc_per_node 1 example_chat_completion.py --ckpt_dir /gemini/pretrain2/llama-2-7b-chat/ --tokenizer_path /gemini/pretrain2/tokenizer.model
上述命令参数含义:
torchrun:是 PyTorch 提供的用于分布式训练的命令行工具。
–nproc_per_node:指定在每个节点上使用 GPU 的个数。该参数与模型大小存在严格对应关系:
| 模型 | MP |
|---|---|
| 7B | 1 |
| 13B | 2 |
| 30B | 8 |
–ckpt_dir:指定所使用的模型。
–tokenizer_path:指定 tokenizer 的路径。
5.3、执行结果
句子补全:
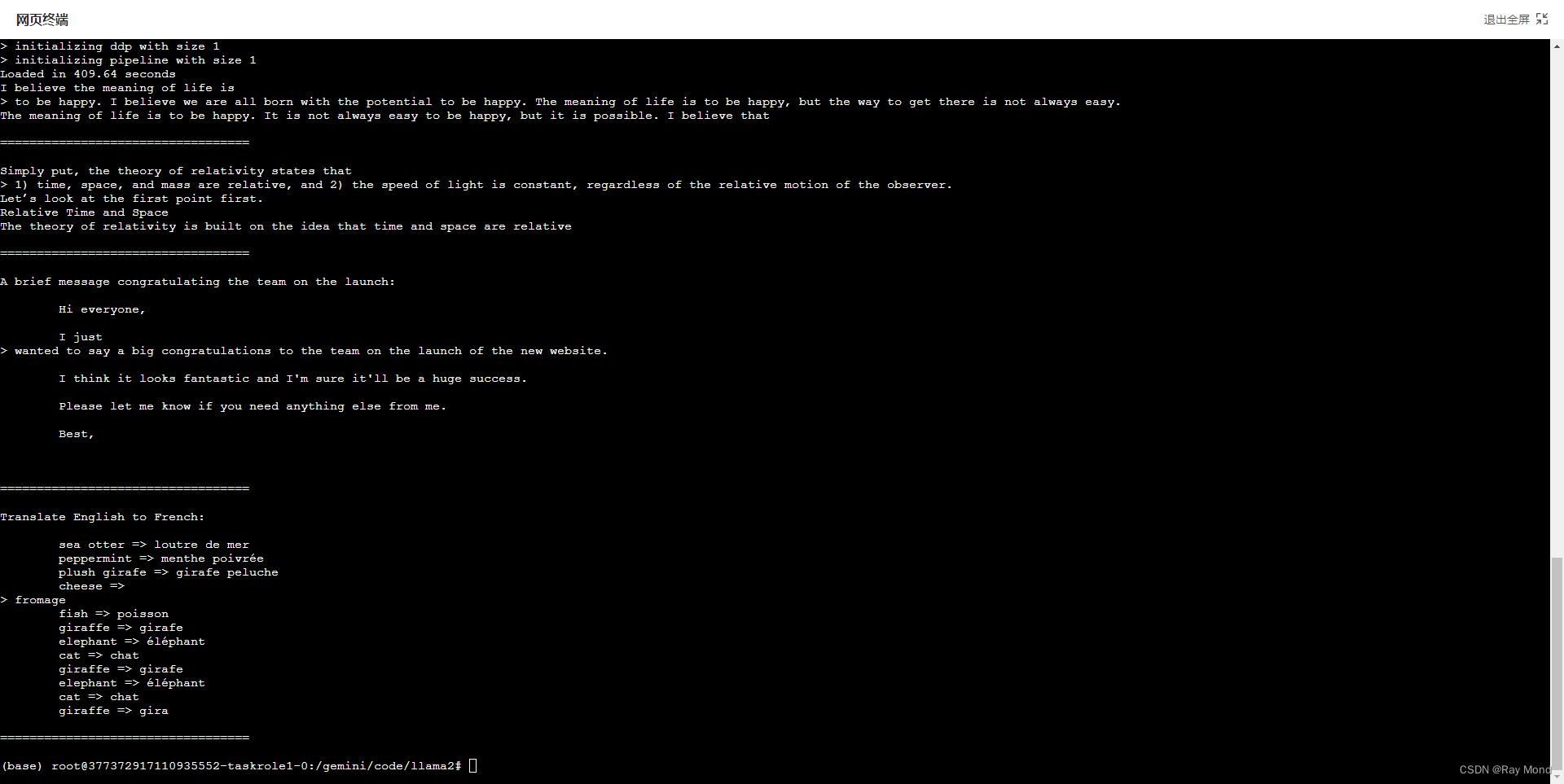
对话生成:
对话生成需要预先加载llama-2-7b-chat模型,部署过程与llama2-7b完全一致,本次不做展示。
因代码文件(example_text_completion.py 和 example_chat_completion.py)中已明确了 “文本补全” 和 “对话” 的输入,因此模型按照既有输入推理并返回结果,如上述执行结果所示。
如果想按照用户自己指定的输入给出推理,可以修改代码文件中相应的输入。















 3109
3109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









