







闭包
def account_create(inital_account = 0) :
def atm(num:int,deposite:bool = True) :
# 声明inital_account是外部声明的inital_account的值,也代表着可以通过内部修改外部的值。
nonlocal inital_account
if deposite:
inital_account+=num
print(f"存款+{num}元,账户余额{inital_account}元")
else:
inital_account -= num
print(f"取款-{num}元,账户余额{inital_account}元")
return atm
atm1 = account_create(100)
atm1(200)
atm1(100,False)
小总结:
优点:
- 无需定义全局变量即可实现通过函数,持续访问、修改某个值。
- 闭包使用的变量的所用于在函数内,难以被错误的调用修改。
缺点:
- 由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间会不被释放,一直占用内存。
装饰器
装饰器实际上也是一种闭包,其功能就是在不破坏目标函数原有代码和功能的前提下,为目标函数增加新功能。
比如我们原本一个函数:
def sleep():
import random
import time
print("睡眠中")
time.sleep(random.randint(1,5))
# 我们想要输出的结果是:
""" 我要睡觉了
睡眠中
我起床了"""
# 我们可以采用下列方法:
print("我要睡觉了")
sleep()
print("我起床了")
# 但是这样子很不优雅,所以可以采用下面的方法
def outer(func):
def inner():
print("我要睡觉了")
func()
print("我起床了")
return inner
# 注意此处代表着装饰器的最重点部分
@outer
def sleep():
import random
import time
print("睡眠中")
time.sleep(random.randint(1,5))
sleep()
设计模式
设计模式就是一种变成套路,事实上面向对象也是一种设计模式。
设计模式:使用特定的套路得到特定的结果。
单例模式
单例模式是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。
在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。(举个例子,比如一个工具类,我们调用这个工具的时候并不希望每次的调用都产生一个新的类对象来进行使用,毕竟工具只需要一把就行,多了浪费空间。)
定义: 保证一个类只有一个实例,并提供一个访问它的全局访问点。
适用场景: 一个类只能有一个实例,而客户可以从一个从所周知的访问点访问它。
单例的实现模式:
在一个文件中定义如下代码:
class Tool:
pass
tool = Tool()
在另外一个文件中导入对象
from test import tool
s1 = tool
s2 = tool
print(s1)
print(s2)
输出的结果s1和s2的地址是一致的,其实也说明二者使用的工具也是同一个。
总结:
单例模式就是对一个类,只获取其唯一的类实例对象,持续重复的使用它。
- 节省内存。
- 节省创建对象的开销。
工厂模式
当需要大量创造一个类的实例的时候,就可以使用工厂模式,即从原生的使用类的构造去创建对象的形式迁移到,基于工厂提供的方法去创建对象的形式。
class Person :
pass
class Teacher(Person):
pass
class Student(Person):
pass
class Factory :
def get_person_class(self,type :str):
if type == 's':
return Student()
elif type == 't':
return Teacher()
factory =Factory()
student = factory.get_person_class('s')
teacher = factory.get_person_class('t')
小总结:
优点
- 大批类创建对象的时候有统一的入口,易于代码维护。
- 当发生修改,仅仅修改工厂类创建方法即可
多线程
进程、线程和并行执行
进程:就是一个程序,运行在系统之上,那么便称这个程序为一个运行进程,并分配进程id方 便系统管理。
线程:线程是归属进程的,一个进程可以开启多个线程,执行不同的工作,是进程实际工作的最小单元。
注意点:
进程之间是存在内存隔离 ,即不同的进程拥有各自的内存空间。
线程之间是内存共享的,线程是属于进程的,一个进程内部的多个线程之间是共享这个进程所拥有的内存空间的。
并行执行:同一时间做不同的工作。进程之间就是并行执行的,操作系统可以同时运行好多程序,这些程序都是并行执行的。相同的线程也是并行执行的。
多个进程同时运行,称之为多任务并行执行,多个线程同时运行,称之为多线程并行执行。
多线程编程
先举个单线程的例子:
def sing() :
while True:
print("我在唱歌")
time.sleep(1)
def dance() :
while True:
print("我在跳舞")
time.sleep(1)
if __name__ == '__main__':
sing()
dance()
输出结果:
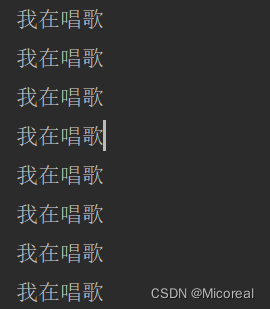
他只会出现唱歌,但是并不会出现跳舞,这就是单线程模式。
如果要采用多线程,则需要用到以下的方式:
import threading
thread_obj = threading.Thread([group[,target[,name[,args[,kwards]]]]])
- group: 展示没有作用,未来功能的预留参数
- target: 执行的目标任务名
- args: 以元组的方式给执行的人物传参
- kwards:以字典的方式给执行任务传参
- name: 线程名,一般不用设置。
样例:
import time
import threading
def sing(msg) :
while True:
print(msg)
time.sleep(1)
def dance(msg) :
while True:
print(msg)
time.sleep(1)
if __name__ == '__main__':
# 创建一个唱歌的线程
sing_thread = threading.Thread(target=sing,args=("我在唱歌",))
# 创建一个跳舞的进程
dance_thread = threading.Thread(target=dance,kwargs={"msg":"我在跳舞"})
# 让线程开始工作
sing_thread.start()
dance_thread.start()
输出结果:

网络编程
socket(套接字)是进程之间通信的一个工具,好比现实生活中的插座,所有的家用电器想要工作都是基于插座进行的,进程之间想要进行网络通信就需要socket。
socket负责进程之间的网络数据传输,好比数据的搬运工。
2个进程之间通过socket进行相互通讯,就必须有服务端和客户端。
socket服务端:等待其他进程的连接,可接受发来的消息,可以回复消息
socket客户端:主动连接服务端,可以发送消息,可以接收回复
一个服务端可以接收多个客户端的消息,并返回信息。
服务端开发
建立一个服务端:
# 1. 创建socket对象
improt socket
socket_server = socket.socket()
# 2. 绑定socket_server到指定的IP和地址
socket_server.bind((host,port))
# 3. 服务端开始监听端口
# backlog为int整数,表示允许的连接数量,超出的会等待,可以不填,不填会自动设置一个合理的值。
socket_server.listen(backlog)
# 4. 接收客户端连接,获得连接对象
# accept方法是阻塞方法:如果没有连接,会卡在当前这一行不向下执行代码
# accept返回的值是一个二元元组,可以使用上述形式,用两个变量接收二元元组的2个元素。
conn,address = socket_server.accept()
print(f"接收到客户端连接,连接来自:{address}")
# 5. 客户端连接后,通过recv方法,接收客户端发送的消息
while True:
data = conn.recv(1024).decode("UTF-8")
# recv方法的返回值是字节数组(Byte),可以通过decode使用UTF-8解码为字符串。
# recv方法的传参是buffsize,缓冲区大小,一般设置为1024即可
if data =='exit':
break
print("接收到的发送过来的消息为:",data)
# 可以通过while True无限循环来持续和客户端进行数据交互。
# 可以通过判定客户端发来的特殊标记,如exit,来退出无限循环。
# 6. 通过conn(客户端当次连接对象),调用send方法可以回复消息
while True:
data = conn.recv(1024).decode("UTF-8")
if data =='exit':
break
print("接收到的发送过来的消息为:",data)
conn.send("你好",encode("UTF-8"))
# 7. conn和socket_server对象调用close方法,关闭连接。
conn.close()
socker_server.close()
客户端开发
建立一个客户端:
# 1. 创建socket对象
improt socket
socket_server = socket.socket()
# 2.连接到服务端
socket_client.connect(("localhost",8888))
# 3. 发送消息
while True :
send_msg = input("请输入要发送的消息")
if send_msg == 'exit' :
break
socket_client.send(send_msg.encode("UTF-8"))# 消息需要编码为字节编码
# 4. 接收返回消息
while True :
send_msg = input("请输入要发送的消息")
if send_msg == 'exit' :
break
socket_client.send(send_msg.encode("UTF-8"))# 消息需要编码为字节编码
#recv也是阻塞的。
recv_data = socket_client.recv(1024).decode("UTF-8")
print("服务端回复的消息是:",recv_data)
# 5. 关闭连接
socket_client.close()
正则表达式
正则表达式,又称作规则表达式,是使用单个字符串来描述、匹配某个句法规则的字符串,常被用来检索,替换那些复合某个模式(规则)的文本。
基础匹配
- re.match(匹配规则,被匹配的字符串),含义是从被匹配的字符串的开头进行匹配,匹配成功则返回匹配对象,匹配不成功则返回空
- re.search(匹配规则,被匹配的字符串),含义是搜索整个字符串,找出匹配的。从前往后,找到第一个后,就停止,不会继续往后。
- re.findall(匹配规则,被匹配的字符串),找出全部匹配规则的数据,找不到返回空list[].
样例:
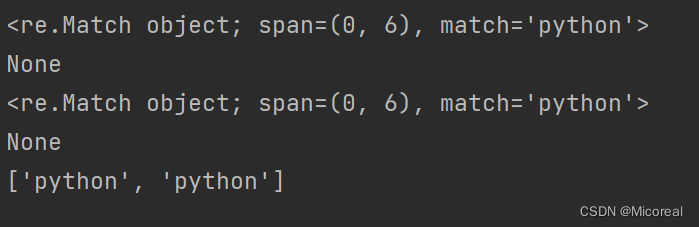
import re
s = 'python and python'
# match从头匹配
result1 = re.match('python',s)
print(result1)
result2 = re.match('ython',s)
print(result2)
# search搜索匹配
result3 = re.search('python',s)
print(result3)
result4 = re.search('ht',s)
print(result4)
# findall 搜索全部匹配
result5 = re.findall('python',s)
print(result5)
输出结果:
元字符匹配
字符串的r的标记表示:字符串内转移字符无效,作为普通字符使用。
单字符匹配:
| 字符 | 功能 |
|---|---|
| . | 匹配任意一个字符(除了\n),\.匹配.本身 |
| [] | 匹配[]中列举的字符 |
| \d | 匹配数字 |
| \D | 匹配非数字 |
| \s | 匹配空白,即空格 tab键 |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z,A-Z,0-9,_ |
| \W | 匹配非单词字符 |
数量匹配:
| 字符 | 功能 |
|---|---|
| * | 匹配前一个规则的字符出现0至无数次 |
| + | 匹配前一个规则的字符出现1至无数次 |
| ? | 匹配前一个规则的字符出现0次或者1次 |
| {m} | 匹配前一个规则的字符出现m次 |
| {m,} | 匹配前一个规则的字符最少出现m次 |
| {m,n} | 匹配前一个规则的字符最少出现m到n次 |
边界匹配:
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词的边界 |
分组匹配:
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| () | 将括号中字符作为一个分组 |
下面给出三个案例:
- 匹配账号,只能由字母和数字组成,长度限制在6-10位。
- 匹配QQ号,要求纯数字,长度5-11,第一位不为0
- 匹配邮箱地址,只允许qq\163\gmail这三种邮箱地址
import re
# 1. 匹配账号,只能由字母和数字组成,长度限制在6-10位。
r ='^[0-9a-zA-Z]{6,10}$'
s = '12345a'
print(re.findall(r,s))
# 2. 匹配QQ号,要求纯数字,长度5-11,第一位不为0
r = '^[1-9][0-9]{4,10}$' # 值得注意的是如果取的是子串,则不需要加上开头结尾,如果需要是完整的,就需要加上^和$
r1 = '[1-9][0-9]{4,10}'
s = '012345678'
print(re.findall(r,s))
print(re.findall(r1,s))
# 3. 匹配邮箱地址,只允许qq\163\gmail这三种邮箱地址
r = r'^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$' # 带有括号分组时需要这么操作
递归
def func() :
if ... :
func()
return ...















 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









