







 本文围绕水下图像增强(UIE)展开,介绍了CURE-Net网络。该网络采用从粗到细的方式,包含三级子网,引入DEB和SRB模块改善图像质量。通过在多个数据集上实验,CURE-Net在定量和定性评价中表现良好,还能提高水下目标检测性能。
本文围绕水下图像增强(UIE)展开,介绍了CURE-Net网络。该网络采用从粗到细的方式,包含三级子网,引入DEB和SRB模块改善图像质量。通过在多个数据集上实验,CURE-Net在定量和定性评价中表现良好,还能提高水下目标检测性能。
文章目录
此篇文章来源于IEEE期刊。
链接: 论文下载
叠甲:本篇论文阅读仅仅是个人的想法与猜测。
刊物发布时间
IEEE JOURNAL OF OCEANIC ENGINEERING, VOL. 49, NO. 1, JANUARY 2024
作者列表:
Xiaowen Cai, Nanfeng Jiang , Weiling Chen , Member, IEEE, Jinsong Hu , Member, IEEE,and Tiesong Zhao , Senior Member, IEEE
前三位应该是共一作,这么写的话。
论文结构 及 读论文的方法总结

我稍微在word当中进行了相关的整理,关于目录其实每篇论文的结构都差不多,但由于之前没大概说过,这边就大概说一下每个部分大概讲解的是什么,之后的论文阅读就不细说了。(注意以下存是个人的super small cup理解)
首先注意的是,个人把读论文分作读三轮,所以下面也会有读论文的方法介绍。
- Abstract:这一部分主要就是对于自己论文方法概括性介绍以及对于自己研究的任务的概括性介绍【第一遍读的时候重要的】
- Introduction:对于上面的Abstract的详细介绍【可以详细看也可以不详细看】
- Relation Work:这一部分主要就是关于这个任务下,前人给予的贡献的叙述,也相当于站在巨人的肩膀上不能忘本,所以要提一嘴的【不太重要】
- Perposed Method:这一部分主要就是关于方法的具体接受【第二遍第三遍重点读的位置】
- Experiments And Results:这一部分主要是关于实验时超参数的调整的位置和最后的结果【第一遍第三遍重点读,但读的重点不一样】
- Conclusion:总结【小看一下,看完论文没想法就详细看】
读论文读三遍:
第一遍粗读:主要看的是Abstract(明白任务以及此篇论文的大概是什么个情况),然后去看Experiments And Results(这一部分是要看实验的硬件设施,以及作者 的方法相对于其他人的方法有多少提升),总结可以看一下
看完第一遍之后,需要明白的是自己能不能复现这篇论文(配置),以及这个任务对于自己的研究方向上有没有什么意义(抄袭创意点),如果都满足就可以开始考虑下面的第二遍
第二遍细度:第二遍主要看的位置就是Perposed Method位置,先搭配着论文给出的图片,对整体的算法有个想法,知道大概的流程是怎么样子的,也可以补充看一下Introduction的总结部分,知道每个部分的结构的作用
这一遍看完之后需要明白的是,你对于论文的前置知识是否有遗漏,需不需要去补充了解别的论文或知识点来辅助看懂这篇论文,比如读这篇论文,如果你还不知道CNN是什么,那在读原理的时候,就需要前去补充,要确保的是你读完第二遍之后对于整体的算法有个概括性的理解。并根据现在的理解,判断此篇论文对你研究的方向是否有效,是否还需要了解论文的细节上的处理,来决定是否进行第三步的阅读。
第三遍精读:第三遍主要做的事情是复现代码,一切脱离实践的阅读都是虚假的,这一步主要需要做的事情主要是搭配着code去理解算法【Perposed Method】,然后当代码大概搞懂了之后根据Experiments And Results中的超参数进行复现论文,然后看看此篇论文是否能复现【注意数据集,很多情况下数据集选择的不同,或者说不按照论文提供的数据集来训练,结果会很一般,我被坑了好多次。。。。。】。
论文理解
下面是个人存手工翻译,由于处于大三,所以并不是很系统的学习过机器学习,只能说略懂,已经尽量去把一些机器学习名词给还是弄成英文了,但有些个人可能还是不知道,会直接直译。
看图
这一步需要了解大概的任务,以及模型的大概思路:

比如论文中的这张图,我们可以看出,这篇论文做的事情实际上是水下的图像识别的。
然后就是抓模型大概了解,别死钻:
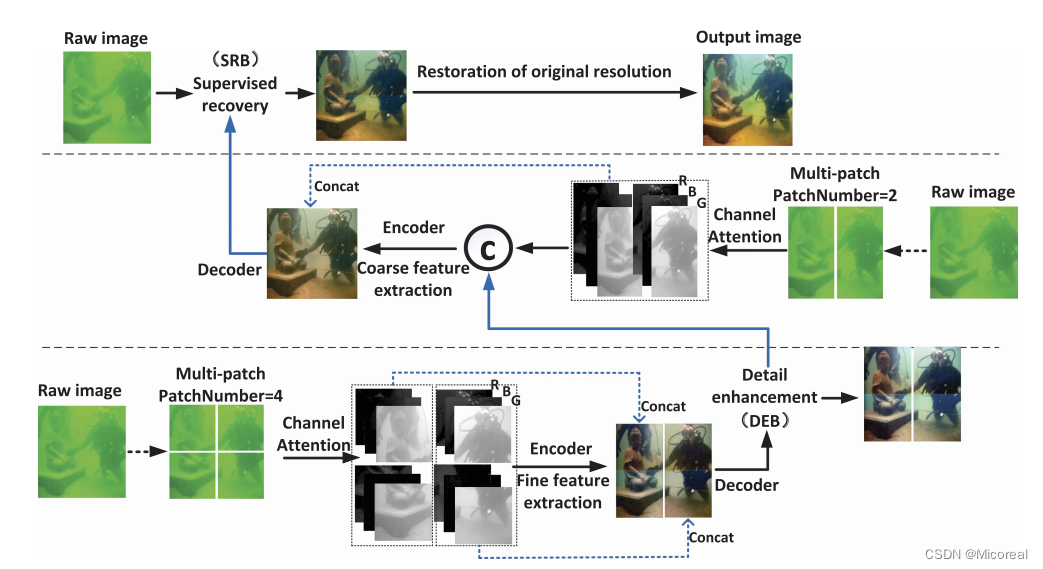
一看就是利用transfomer架构的CNN变种,需要知道的是图片的流向输入输出。
Abstract

由于光的色散和吸收,水下图像在低对比度和图像铸造上会退化。
这个因素限制了在水下和海洋环境下的图像识别的准确性。
在这篇文章中,为了解决这个问题,我们采用CURE-Net,这个网络用从粗到细的方式去改善这种水下的退化。
具体来说,CURE-Net包含三级子网。
前两级子网融合了注意力机制和门去学习多尺度的上下文信息,而第三级网络保护了网络本身的空间信息。
在子网之间插入了细节增强和有监督的恢复的block去更多的恢复图像的颜色和细节
我们让CURE-Net在流行的数据集上进行广泛的评价和得到了最好的效果。
对比于同辈的方法,我们的方法更友好,水下的目标检测在我们的方法下也更容易去识别。
总结:CURE-Net是一个级联网络,改善了水下成像的图像退化问题。
Introduction



因为光在穿过水的时候会衰退,水下图像检测经常有到噪点,颜色变形和低对比度的问题。
这些问题使得各种任务比如海洋生物识别复杂化。
因此,需要海洋图像增强(UIE)的方法已经被提出去改善水下图像的退化。
现在使用的UIE方法包括基于传统算法的和深度学习算法的。
早期的尝试([3][4])主要是通过处理图像的像素提高特定图像的特征,比如通过调整颜色,对比度,亮度。
然后,很多的UIE算法的模型是基于([5][6]),这些算法都是利用了图像本身的属性和物理的成像规律来恢复成清晰的图片的。
最近,深度神经网络在低级任务中已经取得了显著的性能提升,比如去雨去雾([7][8][9])方面。
但是,水下图像展现出不同的视觉外观的模式。
在传统的去雾问题当中,图片噪点和不想要的对象造成了图片扭曲。
因此,我们仍然可以看到包含大量噪点的原始图像。
而在UIE当中,原始场景是不可见的因为图像的变形是在令人不满意的光照条件下。
最近,各种基于深度学习的UIE算法([2][10][11][12])都是用来改善图像的。
尽管做出了这些努力,UIE任务仍然可以进一步改进。
如图1所示,水下图像存在不同类型的变形(颜色偏差、细节模糊、对比度低、细节损失)。
但是,一些深度学习方法(waternet和ucolor)缺少足够的灵活度去处理这个变形,从而导致了细节上的损失。
我们的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6542
6542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









