







文章目录
mvc与mvt
mvc

M:Model,模型, 和数据库进行交互。
V:View,视图, 产生 html 页面。
C:Controller,控制器, 接收请求,进行处理,与 M 和 V 进行交互,返回应答
mvt

M:Model,模型, 和 MVC 中 M 功能相同,和数据库进行交互。
V:View,视图, 和 MVC 中 C 功能相同,接收请求,进行处理,与 M 和 T 进行交互,返回应答。
T:Template,模板, 和 MVC 中 V 功能相同,产生 html 页面
软件安装
可以看出来,现在最新的正式版本是4.2,但这边采用3.2版本进行安装,原因就是conda安装不能直接安装4.2版本,这边只更新到4.1.应该用法是一样的。

创建项目(window)
新建django项目
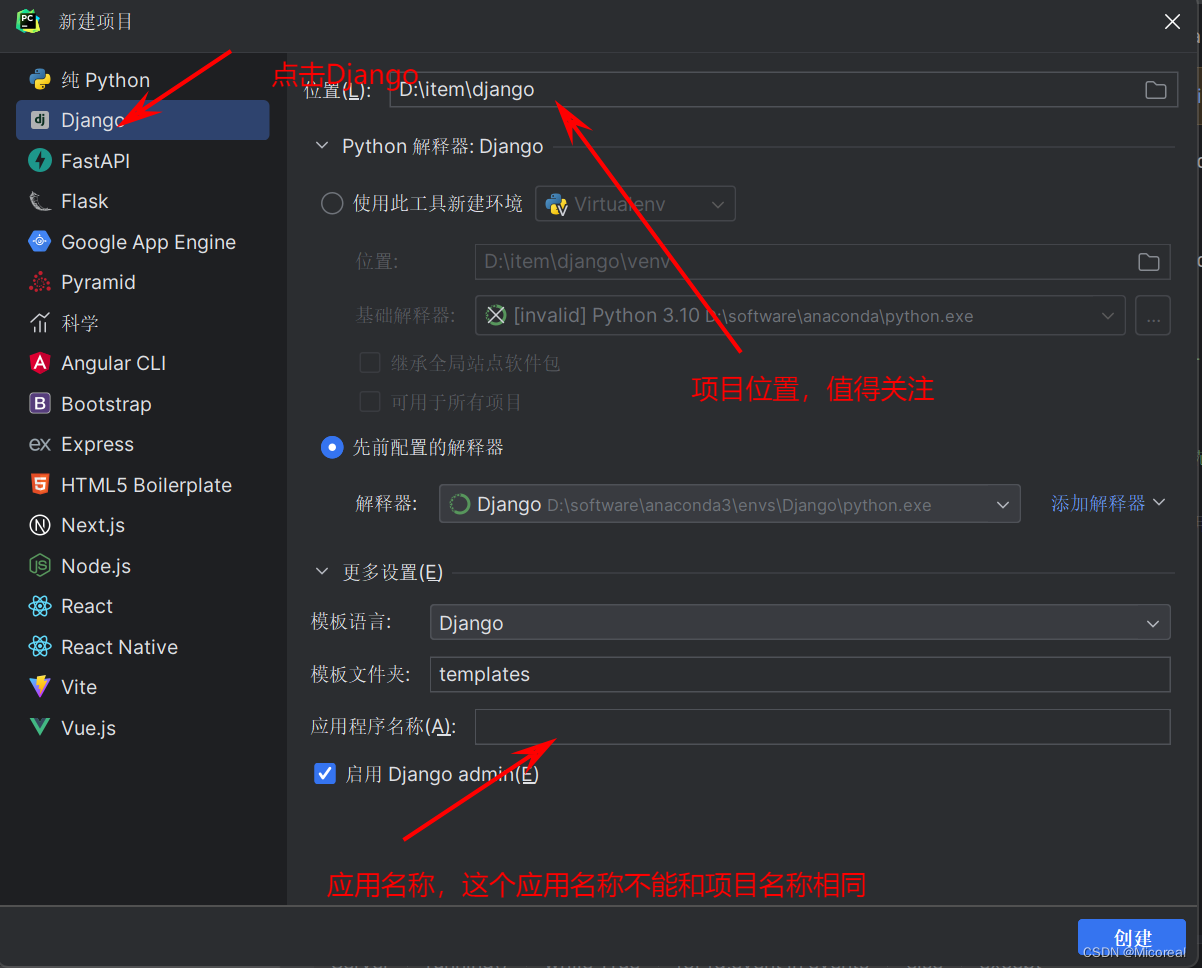
我这边应用程序名称填的是test_app
相关了解
创建项目后,会出现三个目录,实际上对应的就是mvt的三种模式

manage.py: 项目的管理文件
第一个目录:项目目录也就是我们这边的 djang_test文件包中

- __init__.py: 说明 django_test 是一个 python 包。
- settings.py: 项目的配置文件。
- urls.py: 进行 url 路由的配置 (返回资源的函数位置)。
- wsgi.py: web 服务器和 Django 交互的入口。
第二个目录:temple实际上就是T模块
第三个目录:

- __init__.py: 说明目录是一个 Python 模块。
- models.py: 写和数据库项目的内容, 设计模型类。
- views.py: ,接收请求,进行处理,与 M 和 T 进行交互,返回应答。定义处理函数,视图函数。
- tests.py: 写测试代码的文件。
- admin.py: 网站后台管理相关的文件。
- migrations 作用后面讲解
启动项目
在开发阶段,为了能够快速预览到开发的效果,django 提供了一个纯 python
编写的轻量级 web 服务器,仅在开发阶段使用。
运行服务器命令如下(注意 manage.py 在 test1 路径下):
python manage.py runserver ip:端口
例:
python3 manage.py runserver
框架介绍
模型类
ORM(依赖倒置原则)

O 是 object,也就类对象的意思,R 是 relation,翻译成中文是关系,也就是关系数据库中数据表的意思,M 是 mapping,是映射的意思。在 ORM 框架中,它帮我们把类和数据表进行了一个映射,可以让我们通过类和类对象就能操作它所对应的表格中的数据。ORM 框架还有一个功能,它可以根据我们设计的类自动帮我们生成数据库中的表格,省去了我们自己建表的过程。
django 中内嵌了 ORM 框架,不需要直接面向数据库编程,而是定义模型类,
通过模型类和对象完成数据表的增删改查操作。
使用 django 进行数据库开发的步骤如下:
- 在 models.py 中定义模型类
- 迁移去数据库中看表是否生成
- 通过类和对象完成数据增删改查操作
连接mysql与sqlite3
sqlite3
实际上默认就是使用sqlite3:
打开项目地址下的setting,进行查看后面的databases,就可以看到,这一块
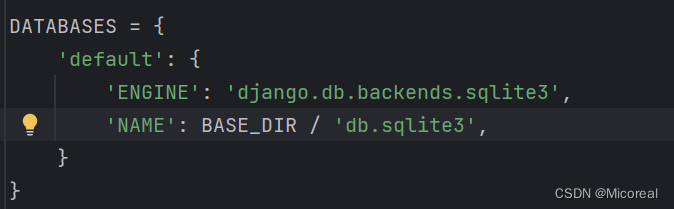
想要修改名字实际上直接在那栏name上面直接进行修改即可。
使用nav进行连接sqlite数据库:

mysql
首先需要先查看你的环境中是否存在下面的包,需要安装一下:mysqlclient这个包,但是在linux下有可能在安装的过程中会报错,原因就是还需要先安装这个:libssl-dev包
将数据库当中的 这些修改成下文:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '数据库名称', # 使用的数据库的名字,数据库必须手动创建
'USER': 'root', # 链接mysql的用户名
'PASSWORD': '123', # 用户对应的密码
'HOST': 'mysql所在地址', # 指定mysql数据库所在电脑ip,你要换为你的ubuntu的
'PORT': 3306, # mysql服务的端口号
}
}
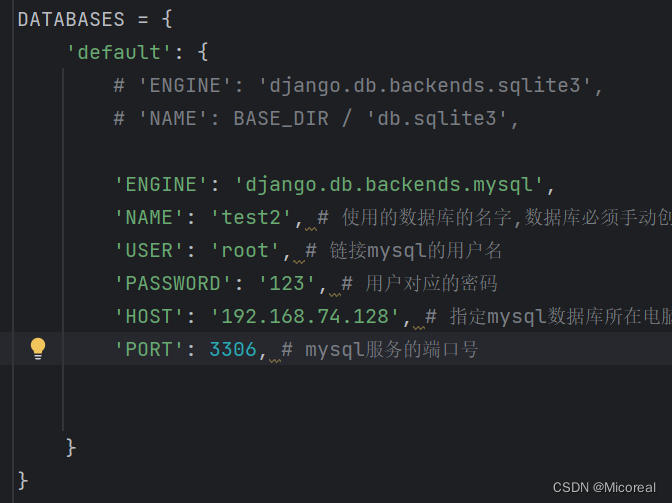
这样子即可实现连接mysql,需要注意的是:这个数据库需要自己先创建,而非让他和sqlite一样自己生成创建。
基础了解
在应用文件夹下的model中:
class BookInfo(models.Model):
btitle=models.CharField(max_length=20,db_index=True)
bpub_date=models.DateField()
# 增加新列时,如果数据库中原本表已经数据,要增加default
# 价格,最大位数为10,小数为2,default 是django的模型类层使用的
bprice = models.DecimalField(max_digits=10, decimal_places=2,default=0,null=True,blank=True)
# 阅读量
bread = models.IntegerField(default=0)
# 评论量
bcomment = models.IntegerField(default=0)
# 删除标记
isDelete = models.BooleanField(default=False)
class HeroInfo(models.Model):
hname = models.CharField(max_length=20)
hgender = models.BooleanField(default=False)
hcomment = models.CharField(max_length=100)
# on_delete=models.CASCADE 删除Bookinfo里边的书籍时,外键的使用
# 会自动删除依赖该书籍的英雄信息
hbook = models.ForeignKey('BookInfo',on_delete=models.CASCADE,db_constraint=False)
# 删除标记
isDelete = models.BooleanField(default=False)
创建类似上文的类,这个类名实际上就是最后生成的表名,有时候表名称会是应用 名称_类名 这种格式,我们这里将类与数据相映射,然后对于这些对象的一系列限制,我们就按照上文的限制来,值得关注的是,外键的使用,是来限制不合法数据的插入更新。
生成结束之后


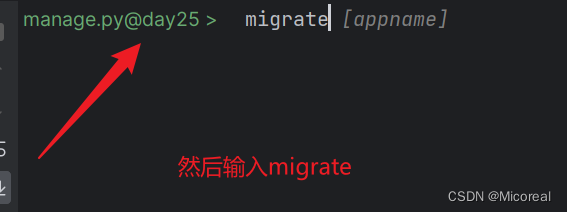
实际上在服务器上完成的就是,下面这个过程:
python manage.py makemigrations //生成迁移文件
python manage.py migrate //生成数据库
然后就可以去你对应mysql上查看你的数据库的内容。
然后就是值得关注的是,除了第一次创建时加入的字段值,后续补充的字段值都需要加上default这个属性。
字段属性和选项
模型类属性命名限制
- 不能是 python 的保留关键字。
- 不允许使用连续的下划线,这是由 django 的查询方式决定的。比如Books__Info 是不可以的
- 定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下:属性名=models.字段类型(选项)
字段类型
包:django.db.models
| 类型 | 描述 |
|---|---|
| AutoField | 自动增长的 IntegerField,通常不用指定,不指定时 Django 会自动创建属性名为 id 的自动增长属性。 |
| BooleanField | 布尔字段,值为 True 或 False。 |
| NullBooleanField | 支持 Null、True、False 三种值。 |
| CharField(max_length=最大长度) | 字符串。参数 max_length 表示最大字符个数。 |
| TextField | 大文本字段,一般超过 4000 个字符时使用。 |
| IntegerField | 整数 |
| DecimalField(max_digits=None,decimal_places=None) | 十进制浮点数。参数 max_digits 表示总位。参数 decimal_places 表示小数位数。(精度较高,建议用这个) |
| FloatField | 浮点数。参数同上(精度不够) |
| DateField ([auto_now=False,auto_now_add=False]) | 日期,1)参数 auto_now 表示每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为 false。2) 参数 auto_now_add 表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为 false。3)参数 auto_now_add 和 auto_now 是相互排斥的,组合将会发生错误。(年月日) |
| TimeField | 时间,参数同 DateField。(时分秒) |
| DateTimeField | 日期时间,参数同 DateField。(年月日时分秒) |
| FileField | 上传文件字段。 |
| ImageField | 继承于 FileField,对上传的内容进行校验,确保是有效的图片。 |
选项
通过选项实现对字段的约束,选项如下:
| 选项名 | 描述 |
|---|---|
| default | 默认值。设置默认值。 |
| primary_key | 若为 True,则该字段会成为模型的主键字段,默认值是 False,一般作为AutoField 的选项使用。 |
| unique | 如果为 True, 这个字段在表中必须有唯一值,默认值是 False。 |
| db_index | 若值为 True, 则在表中会为此字段创建索引,默认值是 False。 |
| db_column | 字段的名称,如果未指定,则使用属性的名称。新起名字的作用 |
| null | 如果为 True,表示允许为空,默认值是 False。 |
| blank | 如果为 True,则该字段允许为空白,默认值是 False。控制后台管理的 |
| db_constraint | 设为 false,数据库中不会创建外键,而是转为程序内存控制外键,建议准备使用外键的时候,在这里加上这一个 |
查询
查询函数
通过模型类.objects 属性可以调用如下函数,实现对模型类对应的数据表的查询。
| 函数名 | 功能 | 返回值 | 说明 |
|---|---|---|---|
| get | 返回表中满足条件的一条且只能有一条数据。 | 返回值是一个模型类对象。 | 参数中写查询条件。1) 如果查到多条数据,则抛异常MultipleObjectsReturned。2)查询不到数据 ,则抛异常:DoesNotExist。 |
| all | 返回模型类对应表格中的所有数据。 | 返回值是QuerySet类型 | 查询集,可以拿出来进行遍历 |
| filter | 返回满足条件的数据。 | 返回值是QuerySet类型 | 参数写查询条件。 |
| exclude | 返回不满足条件的数据。 | 返回值是QuerySet类型 | 参数写查询条件。 |
| order_by | 对查询结果进行排序。 | 返回值是QuerySet类型 | 参数中写根据哪些字段进行排序。 |
使用用例:
首先 python manage.py shell 开启 django shell
# 先导入,值得关注的时这边booktest.models实际上位置也取决于配置文件中的根路径
from booktest.models import BookInfo,HeroInfo
get 示例:
例:查询图书 id 为 3 的图书信息。
b = BookInfo.objects.get(id=3)
all 方法示例:
例:查询图书所有信息。
b = BookInfo.objects.all()
返回的数据是一个列表,内部的数据是一个个满足条件的对象
filter 方法示例:
条件格式:
模型类属性名__条件名=值(两个下划线)
查询图书评论量为 34 的图书的信息:
c=BookInfo.objects.filter(bcomment=34)
a)判等 条件名:exact。
例:查询编号为 1 的图书。
BookInfo.objects.get(id__exact=1)等价于 BookInfo.objects.get(id=1)
b)模糊查询
例:查询书名包含'传'的图书。contains(类似于sql中的like,不过不需要通配符)
BookInfo.objects.filter(btitle__contains='传')
例:查询书名以'部'结尾的图书 endswith 开头:startswith
BookInfo.objects.filter(btitle__endswith='部')
c)空查询 isnull 可以用来查询是空 也可以用来查询是否为不空
例:查询书名不为空的图书。isnull
select * from booktest_bookinfo where btitle is not null;
BookInfo.objects.filter(btitle__isnull=False)
d)范围查询 in
例:查询 id 为 1 或 3 或 5 的图书。
select * from booktest_bookinfo where id in (1,3,5);
BookInfo.objects.filter(id__in = [1,3,5])
e)比较查询 gt大于 lt小于 gte大于等于 lte小于等于
例:查询 id 大于 3 的图书。
Select * from booktest_bookinfo where id>3;
BookInfo.objects.filter(id__gt=3)
f)日期查询
例:查询 1980 年发表的图书。
BookInfo.objects.filter(bpub_date__year=1980)
例:查询 1980 年 1 月 1 日后发表的图书。
from datetime import date
BookInfo.objects.filter(bpub_date__gt=date(1980,1,1))
exclude 方法示例:
例:查询 id 不为 3 的图书信息。
BookInfo.objects.exclude(id=3)
order_by 方法示例:
作用:进行查询结果进行排序。
例:查询所有图书的信息,按照 id 从小到大进行排序。
BookInfo.objects.all().order_by('id')
例:查询所有图书的信息,按照 id 从大到小进行排序。
BookInfo.objects.all().order_by('-id')
例:把 id 大于 3 的图书信息按阅读量从大到小排序显示。
BookInfo.objects.filter(id__gt=3).order_by('-bread')
F对象
作用:用于对象属性之间的比较。
使用之前需要先导入:
from django.db.models import F
例:查询图书阅读量大于评论量图书信息。
相对应的sql语句是:
select * from BookInfo where bread>bcomment
BookInfo.objects.filter(bread__gt=F('bcomment'))
例:查询图书阅读量大于 2 倍评论量图书信息。
BookInfo.objects.filter(bread__gt=F('bcomment')*2)
Q对象
作用:用于查询时条件之间的逻辑关系。not and or,可以对 Q 对象进行&|~操作。
使用之前需要先导入:
from django.db.models import Q
例:查询 id 大于 3 且阅读量大于 30 的图书的信息。
对应的sql语句实际上是:
select * from BoookInfo where id>3 and bread>30;
BookInfo.objects.filter(id__gt=3, bread__gt=30)
BookInfo.objects.filter(Q(id__gt=3)&Q(bread__gt=30))
例:查询 id 大于 3 或者阅读量大于 30 的图书的信息。
BookInfo.objects.filter(Q(id__gt=3)|Q(bread__gt=30))
例:查询 id 不等于 3 图书的信息。
BookInfo.objects.filter(~Q(id=3))
聚合函数
作用:对查询结果进行聚合操作。
聚合函数(类似于mysql):
- sum
- count
- avg
- max
- min
aggregate:调用这个函数来使用聚合。 返回值是一个字典
使用前需先导入聚合类:
from django.db.models import Sum,Count,Max,Min,Avg
例:查询所有图书的数目。
BookInfo.objects.all().aggregate(Count('id'))
{'id__count': 5}
例:查询所有图书阅读量的总和。
BookInfo.objects.aggregate(Sum('bread'))
{'bread__sum': 126}
count 函数 返回值是一个数字
作用:统计满足条件数据的数目。而不需要使用aggregate来调用聚合函数的方式,只有count才有这种方法,其他的没有
例:统计所有图书的数目。
BookInfo.objects.all().count()
BookInfo.objects.count()
例:统计 id 大于 3 的所有图书的数目。
BookInfo.objects.filter(id__gt=3).count()
查询表
all, filter, exclude, order_by 调用这些函数会产生一个查询集,QuerySet类对象可以继续调用上面的所有函数。
查询集特性
- 惰性查询:只有在实际使用查询集中的数据的时候才会发生对数据库的真正查询。
- 缓存:当使用的是同一个查询集时,第一次使用的时候会发生实际数据库的查询,然后把结果缓存起来,之后再使用这个查询集时,使用的是缓存中的结果。
限制查询集
可以对一个查询集(QuerySet)进行取下标或者切片操作来限制查询集的结果。对一个查询集进行切片操作会产生一个对象或者一个列表,下标不允许为负数。
取出查询集第一条数据的两种方式:
| 方式 | 说明 |
|---|---|
| b[0] | 取出的就是对应类型的对象 如果 b[0]不存在,会抛出 IndexError异常 |
| b[0:1] | 取出的是一个列表,列表当中是一个个对应类型的对象 |
| QuerySet.get() | 如果 object.get()不存在,会抛出DoesNotExist 异常。 |
关联查询(这一部分尽量去和mysql的关联查询相对应看看)
一对一(一般用的少)
代码标志:models.OneToOneField 定义在哪个类中都可以,注意只定义在其中一个。
员工基本信息类-员工详细信息类(这种做法实际上就是为了避免消息冗余,具体讲就是比如说员工基本信息中有名称-性别这俩个,详细中有家庭地址这一个很多人都不填的 或者 填的人比较少导致这一栏会空出来的,这种地方可以使用一对一)
样例:
# 员工基本信息类
class EmployeeBasicInfo(models.Model):
# 姓名
name = models.CharField(max_length=20)
# 性别
gender = models.BooleanField(default=False)
# 年龄
age = models.IntegerField()
# 关系属性,代表员工的详细信息
# employee_detail = models.OneToOneField('EmployeeDetailInfo',on_delete=models.CASCADE,)
# 员工详细信息类
class EmployeeDetailInfo(models.Model):
# 联系地址
addr = models.CharField(max_length=256)
# 教育经历
# 关系属性,代表员工基本信息
employee_basic = models.OneToOneField('EmployeeBasicInfo',on_delete=models.CASCADE,)
操作实际上就是一对多的前两种手法,以上文为例子
1. 通过不包含onetoone的来 访问 包含onetoone的
不包含.包含的_set.all()
e = EmployeeBasicInfo.objects.get(name='张三')
e.EmployeeDetailInfo_set.all()
2. 通过包含onetoone的来 访问 不包含onetoone的
包含.对应属性
ei = EmployeeDetailInfo.objects.get(id=1)
ei.employee_basic
一对多
代码标志:models.ForeignKey() 定义在多的类中。
实际上就是使用外键定义到多的类中,效果就是类下文格式(图书英雄表),也就是一本书可以对应多个英雄
图书:
| id | name |
|---|---|
| 1 | 天龙八部 |
| 2 | 射雕英雄传 |
英雄:
| id | name | 外键(图书) |
|---|---|---|
| 1 | 乔峰 | 1 |
| 2 | 郭靖 | 2 |
1.由这本书来查属于这本书的英雄使用: 这本书.英雄类名小写_set.all()的方式
例:查询 id 为 1 的图书关联的英雄的信息。
b=BookInfo.objects.get(id=1)
b.heroinfo_set.all()
2.由英雄来查询英雄所属于的书: 这个英雄.外键属性
也可以通过模型类查询:
HeroInfo.objects.filter(hbook__id=1)
例:查询 id 为 1 的英雄关联的图书信息。
h = HeroInfo.objects.get(id=1)
h.hbook
3. 通过类名进行查找:
也可以通过模型类查询:
通过多类的条件查询一类的数据:
一类名.objects.filter(多类名小写__多类属性名__条件名)
通过一类的条件查询多类的数据:
多类名.objects.filter(关联属性__一类属性名__条件名)
例:查询图书信息,要求图书关联的英雄的描述包含'八'。
BookInfo.objects.filter(heroinfo__hcomment__contains='八')
例:查询图书信息,要求图书中的英雄的 id 大于 3.
BookInfo.objects.filter(heroinfo__id__gt=3)
例:查询书名为“天龙八部”的所有英雄。
HeroInfo.objects.filter(hbook__btitle='天龙八部')
多对多
代码标志:models.ManyToManyField() 定义在哪个类中都可以。
例子:新闻类-新闻类型类 一个新闻可以有多种属性,比如他属于科技新闻,属于娱乐新闻 而科技新闻又有很多条新闻
对于多对多:存储实际上是采用=三张表的形式进行存储:
- NewsType 表
- NewsInfo 表
- NewsType_type_news 表(用于存储二者之间的关系)
例子:
class NewsType(models.Model):
# 类型名
type_name = models.CharField(max_length=20)
# 关系属性,代表类型下面的信息
type_news = models.ManyToManyField('NewsInfo')
# 新闻类
class NewsInfo(models.Model):
# 新闻标题
title = models.CharField(max_length=128)
# 发布时间
pub_date = models.DateTimeField(auto_now_add=True)
# 信息内容
content = models.TextField()
# 关系属性, 代表信息所属的类型,注意不能和上面的同时开启
#news_type = models.ManyToManyField('NewsType')
而对于向数据库内添加元素:
- 对于前两张表(NewsType 表 和 NewsInfo 表)按照和以前的一样来添加即可
- 对于二者的关系表,可以参考:链接(记得点开新建表进行查看),或见下文简单介绍:
简单介绍:
- 查询方式和上文一致。
- add 的顺序和数据库中表的字段的顺序保持一致,无论那个对象操作,add 需要写的是 id、
- set 是可以设置多个对象,把原来的就覆盖掉了
- remove 去移除时,当前对象只能移除自己的选课信息
插入更新与删除
- 调用一个模型类对象的 save 方法的时候就可以实现对模型类对应数据表的
插入和更新。(操作就是,先创建一个对象比如b = bookInfo(),然后对b赋值b.title=‘好书’,然后使用save进行存储) - 调用一个模型类对象的 delete 方法的时候就可以实现对模型类对应数据表
数据的删除。(删除的话,先查找到要删除的那行数据b = bookInfo.objects.get(id=1),然后删除 b.delete())
自关联
代码标志:models.ForeignKey(‘self’,on_delete=models.CASCADE,),外键绑定自己即可。
自关联是一种特殊的一对多的关系,回想一下mysql当中举的省级城市-市级城市的案例,我们在一张表中的最后一行存储他父亲城市,我们这边也采用这种做法,当然操作也是和一对多/多对一是一样的
class Areas(models.Model):
'''地区模型类'''
# 地区名称
atitle = models.CharField(max_length=20)
# 关系属性,代表当前地区的父级地区 值得关注的是这边外键关联自己
aParent = models.ForeignKey('self', null=True,blank=True,on_delete=models.CASCADE,)
值得关注的是生成的表的名称是:
| id | atitle | aParent_id |
|---|---|---|
表中存储的会自动转化为id,但是你在外层使用的时候可以直接aparent直接提取数据对象,也可以aparent_id提取父亲城市的id
# 编写 views 函数,(辅助理解,看不懂先看后面的view部分,再回来查看)
def areas(request):
'''获取广州市的上级地区和下级地区'''
# 1.获取广州市的信息 ,先获取对象信息
area = AreaInfo.objects.get(atitle='广州市')
# 2.查询广州市的上级地区
parent = area.aParent
# 3.查询广州市的下级地址
children = area.areainfo_set.all()
# 使用模板
return render(request, 'booktest/areas.html',{'area':area,'parent':parent, 'children':children})
管理器
现在不免有一个疑惑:BookInfo.objects.all()中的objects是一个什么东西呢?objects 是 Django 帮我自动生成的管理器对象,通过这个管理器可以实
现对数据的查询,等一系列函数,但是我们又想自定义相关的函数,所以就需要做到自定管理器。
objects 是 models.Manger 类的一个对象。自定义管理器之后 Django 不再帮
我们生成默认的 objects 管理器。
自定义管理器类
# 1. 自定义一个管理器类,这个类继承 models.Manger 类。
class BookInfoManager(models.Manager):
'''图书模型管理器类'''
# 1.改变原有查询的结果集
def all(self):
# 1.调用父类的 all 方法,获取所有数据
books = super().all() # QuerySet
# 2.对 books 中的数据进行过滤
books = books.filter(isDelete=False)
# 返回 books
return books
# 2. 再在具体的模型类中 class BookInfo 里定义一个自定义管理器类的对象。
class BookInfo(models.Model):
btitle=models.CharField(max_length=20,db_index=True)
# 等等一系列东西
# 定义一个objects的对象,并且也继承了原本的manage对象的objects,之后调用all对象实际上调用的查询就是上文我们自定义函数后的。
objects = BookInfoManager() # 自定义一个 BookInfoManager 类的对象(放到 BookInfo 的模型类中)
获取类名self.models
# 1. 自定义一个管理器类,这个类继承 models.Manger 类。
class BookInfoManager(models.Manager):
'''图书模型管理器类'''
def create_book(self, btitle, bpub_date):
'''添加一本图书'''
# 1.创建一个图书对象
# 获取 self 所在的模型类
model_class = self.model # 实际上这里就是获取调用这个方法的类名
book = model_class()
# book = BookInfo()
book.btitle = btitle
book.bpub_date = bpub_date
# 2.添加进数据库
book.save()
# 3.返回 book
return book
元选项(修改表名)
元选项:
需要在模型类中定义一个元类 Meta,在里面定义一个类属性 db_table 就可以指定表名。这样表名由自己指定,而不依赖模型类所在的文件夹(之前我们的表名为 booktest_bookinfo)
例子:
class BookInfo(models.Model):
btitle=models.CharField(max_length=20,db_index=True)
# 等等一系列东西
class Meta:
db_table = 'bookinfo' # 指定模型类对应表
效果就是之后这张表的名字会变成bookinfo,而不是之前默认的取名















 1284
1284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









