







前情知识介绍
我们想导入未知包的某一个模块的时候,可以如下面进行导入:
# 导入对应的模块的文件夹,然后之后调用可以直接使用import,理解的话就是将这个文件夹当中的文件复制粘贴到当前文件夹中
sys.path.append(g_dynamic_document_root)
# 导入web框架的主模块
web_frame_module = __import__(web_frame_module_name)
# 获取另外一个模块可以直接调用的函数(对象)
app = getattr(web_frame_module, app_name)
比如from select import eopll的时候我们可以:
select = __import__(select)
epoll = getattr(select,epoll)
WSIG-miniWeb框架
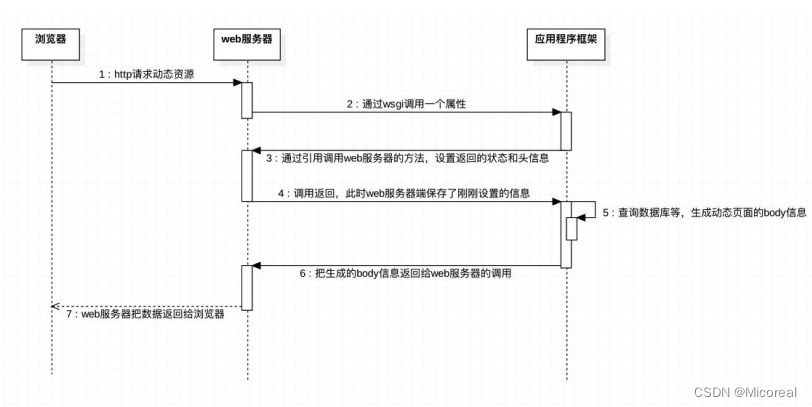
服务器动态资源请求
浏览器请求动态页面的全流程
WSGI
WSGI 实际上就可以把他当作是一个类协议的东西,应用程序想要传数据给web服务器,就需要遵循 实现类似的效果。
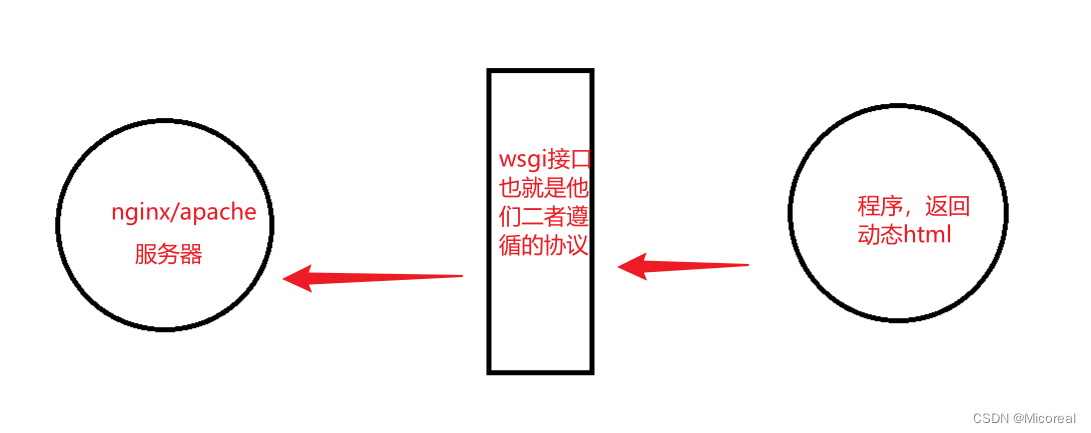
WSGI 由 web 服务器支持,而 web 框架允许你选择适合自己的配对,但它同样对于服务器和框架开发者提供便利使他们可以专注于自己偏爱的领域和专长而不至于相互牵制。其他语言也有类似接口:java 有 Servlet API,Ruby有Rack。
WSGI接口的定义
WSGI 接口定义非常简单,它只要求 Web 开发者实现一个函数,就可以响应 HTTP请求。我们来看一个最简单的 Web 版本的“Hello World"
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return 'Hello World!'
上面的 application()函数就是符合 WSGI 标准的一个 HTTP 处理函数,它接收两个参数:
- environ:一个包含所有 HTTP 请求信息的 dict 对象;
- start_response:一个发送 HTTP 响应的函数。
整个 application()函数本身没有涉及到任何解析 HTTP 的部分,也就是说,把底层 web 服务器解析部分和应用程序逻辑部分进行了分离,这样开发者就可以专心做一个领域了。
不过,等等,这个 application()函数怎么调用?如果我们自己调用,两个参数
environ 和 start_response 我们没法提供,返回的 str 也没法发给浏览器。
所以 application()函数必须由 WSGI 服务器来调用。有很多符合 WSGI 规范的服务器。而我们此时的 web 服务器项目的目的就是做一个既能解析静态网页还可以解析动态网页的服务器。
字典中的内容(不需要记忆,长个见识而已hh):
{
'HTTP_ACCEPT_LANGUAGE': 'zh-cn',
'wsgi.file_wrapper': <built-infunctionuwsgi_sendfile>,
'HTTP_UPGRADE_INSECURE_REQUESTS': '1',
'uwsgi.version': b'2.0.15',
'REMOTE_ADDR': '172.16.7.1',
'wsgi.errors': <_io.TextIOWrappername=2mode='w'encoding='UTF-8'>,
'wsgi.version': (1,0),
'REMOTE_PORT': '40432',
'REQUEST_URI': '/',
'SERVER_PORT': '8000',
'wsgi.multithread': False,
'HTTP_ACCEPT': 'text/html,application/xhtml+xml,application/xml;q=0.
9,*/*;q=0.8',
'HTTP_HOST': '172.16.7.152: 8000',
'wsgi.run_once': False,
'wsgi.input': <uwsgi._Inputobjectat0x7f7faecdc9c0>,
'SERVER_PROTOCOL': 'HTTP/1.1',
'REQUEST_METHOD': 'GET',
'HTTP_ACCEPT_ENCODING': 'gzip,deflate',
'HTTP_CONNECTION': 'keep-alive',
'uwsgi.node': b'ubuntu',
'HTTP_DNT': '1',
'UWSGI_ROUTER': 'http',
'SCRIPT_NAME': '',
'wsgi.multiprocess': False,
'QUERY_STRING': '',
'PATH_INFO': '/index.html',
'wsgi.url_scheme': 'http',
'HTTP_USER_AGENT': 'Mozilla/5.0(Macintosh;IntelMacOSX10_12_5)AppleW
ebKit/603.2.4(KHTML,likeGecko)Version/10.1.1Safari/603.2.4',
'SERVER_NAME': 'ubuntu'
}
静态服务器回顾以及改造
实际上就是为了自己去实现检测时动态页面还是静态页面,那么什么时动态页面 ,什么是静态页面呢?我们拿django之前的例子为例,django虽然没有实现前后端分离,他使用模板语言来实现动态页面(每个人看到的不一样,根据自己对应的数据来进行显示)。
web_server.py
import socket
import re
import multiprocessing
import time
class WSGIServer(object):
def __init__(self):
# 1. 创建套接字
self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2. 绑定
self.tcp_server_socket.bind(("", 7890))
# 3. 变为监听套接字
self.tcp_server_socket.listen(128)
def service_client(self, new_socket):
"""为浏览器返回数据"""
# 1. 接收浏览器发送过来的请求 ,即http请求
# GET / HTTP/1.1
# .....
request = new_socket.recv(1024).decode("utf-8")
# print(">>>"*50)
# print(request)
request_lines = request.splitlines()
print("")
print(">" * 20)
print(request_lines)
# GET /index.html HTTP/1.1
# get post put del
file_name = ""
ret = re.match(r"[^/]+(/[^ ]*)", request_lines[0])
if ret:
file_name = ret.group(1)
# print("*"*50, file_name)
if file_name == "/":
file_name = "/index.html"
# 2. 返回http格式的数据,给浏览器
if not file_name.endswith(".py"):
try:
f = open("./html" + file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "------file not found-----"
new_socket.send(response.encode("utf-8"))
else:
html_content = f.read()
f.close()
# 2.1 准备发送给浏览器的数据---header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2 准备发送给浏览器的数据---boy
# response += "hahahhah"
# 将response header发送给浏览器
new_socket.send(response.encode("utf-8"))
# 将response body发送给浏览器
new_socket.send(html_content)
else:
# 2.2 如果是以.py结尾,那么就认为是动态资源的请求
header = "HTTP/1.1 200 OK\r\n"
header += "\r\n"
body = "hahaha %s " % time.ctime()
response = header + body
# 发送response给浏览器
new_socket.send(response.encode("utf-8"))
# 关闭套接
new_socket.close()
def run_forever(self):
"""用来完成整体的控制"""
while True:
# 4. 等待新客户端的链接
new_socket, client_addr = self.tcp_server_socket.accept()
# 5. 为这个客户端服务
p = multiprocessing.Process(target=self.service_client, args=(new_socket,))
p.start()
new_socket.close()
# 关闭监听套接字
self.tcp_server_socket.close()
def main():
"""控制整体,创建一个web 服务器对象,然后调用这个对象的run_forever方法运行"""
wsgi_server = WSGIServer()
wsgi_server.run_forever()
if __name__ == "__main__":
main()
这个例子:想要说的就是我们早期使用检测后缀,来判断是不是动态网址。
web 服务器 和 逻辑处理代码 分离
web_server.py 和上面进行对比,只在这里进行修改,
else:
# 2.2 如果是以.py结尾,那么就认为是动态资源的请求
header = "HTTP/1.1 200 OK\r\n"
header += "\r\n"
#传递文件名(请求的url),得到mini_frame给予的 响应body
body = mini_frame.application(file_name)
response = header + body
# 发送response给浏览器
new_socket.send(response.encode("utf-8"))
mini_frame.py
import time
def login():
return "i----login--welcome wangdao website.......time:%s" % time.ctime()
def register():
return "-----register---welcome wangdao website.......time:%s" % time.ctime()
def profile():
return "-----profile----welcome wangdao website.......time:%s" % time.ctime()
def application(file_name):
if file_name == "/login.py":
return login()
elif file_name == "/register.py":
return register()
else:
return "not found you page...."
web动态服务器的基本实现
web_server.py
else:
# 2.2 如果是以.py结尾,那么就认为是动态资源的请求
env = dict()
#传入回调函数给application
body = mini_frame.application(env, self.set_response_header)
# 解析头部
header = "HTTP/1.1 %s\r\n" % self.status
#解析头部
for temp in self.headers:
header += "%s:%s\r\n" % (temp[0], temp[1])
header += "\r\n"
response = header + body
# 发送response给浏览器
new_socket.send(response.encode("utf-8"))
以及类内新增方法:
def set_response_header(self, status, headers):
self.status = status
#web服务器可以设置header,mini_frame也可以设置header
self.headers = [("server", "apache")]
self.headers += headers
mini_frame.py
def application(environ, start_response):
#由mini_frame框架添加响应码和头部
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
return 'Hello World! 我爱你中国....'
上面做的就是关于后面的那个参数的介绍,他就是来拼接我们程序传递过去的参数的,然后拼接成一个符合http规范的协议。
带参数的web动态服务器
web_server.py
import socket
import re
import multiprocessing
import time
import mini_frame
class WSGIServer(object):
def __init__(self,port, documents_root, app):
# 1. 创建套接字
self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2. 绑定
self.tcp_server_socket.bind(("", port))
# 3. 变为监听套接字
self.tcp_server_socket.listen(128)
# 设定资源文件的路径
self.documents_root = documents_root
# 设定web框架(django)可以调用的函数(对象)
self.app = app
def service_client(self, new_socket):
"""为这个客户端返回数据"""
# 1. 接收浏览器发送过来的请求 ,即http请求
# GET / HTTP/1.1
# .....
request = new_socket.recv(1024).decode("utf-8")
# print(">>>"*50)
# print(request)
request_lines = request.splitlines()
print("")
print(">" * 20)
print(request_lines)
# GET /index.html HTTP/1.1
# get post put del
file_name = ""
ret = re.match(r"[^/]+(/[^ ]*)", request_lines[0])
if ret:
file_name = ret.group(1)
# print("*"*50, file_name)
if file_name == "/":
file_name = "/index.html"
# 2. 返回http格式的数据,给浏览器
if not file_name.endswith(".py"):
try:
f = open("./html" + file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "------file not found-----"
new_socket.send(response.encode("utf-8"))
else:
html_content = f.read()
f.close()
# 2.1 准备发送给浏览器的数据---header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2 准备发送给浏览器的数据---boy
# response += "hahahhah"
# 将response header发送给浏览器
new_socket.send(response.encode("utf-8"))
# 将response body发送给浏览器
new_socket.send(html_content)
else:
# 2.2 如果是以.py结尾,那么就认为是动态资源的请求
env = dict()
#浏览器请求的url添加到env中
env['PATH_INFO'] = file_name
#传入回调函数给application
body = self.app(env, self.set_response_header)
# 解析头部
header = "HTTP/1.1 %s\r\n" % self.status
# header += "Content-Type: text/html; charset=utf-8\r\n"
header += "Content-Length: %d\r\n" % len(body.encode("utf-8"))
#解析头部
for temp in self.headers:
header += "%s:%s\r\n" % (temp[0], temp[1])
header += "\r\n"
response = header + body
# 发送response给浏览器
new_socket.send(response.encode("utf-8"))
# 关闭套接
new_socket.close()
def run_forever(self):
"""用来完成整体的控制"""
while True:
# 4. 等待新客户端的链接
new_socket, client_addr = self.tcp_server_socket.accept()
# 5. 为这个客户端服务
p = multiprocessing.Process(target=self.service_client, args=(new_socket,))
p.start()
new_socket.close()
# 关闭监听套接字
self.tcp_server_socket.close()
def set_response_header(self, status, headers):
self.status = status
#web服务器想告诉浏览器附加头部是多少
self.headers = [("server", "mini_web v8.8")]
self.headers += headers
import sys
def main():
"""控制整体,创建一个web 服务器对象,然后调用这个对象的run_forever方法运行"""
"""控制web服务器整体"""
# python3 xxxx.py 7890
if len(sys.argv) == 3:
# 获取web服务器的port
port = sys.argv[1]
if port.isdigit():
port = int(port)
# 获取web服务器需要动态资源时,访问的web框架名字
web_frame_module_app_name = sys.argv[2]
else:
print("运行方式如: python3 xxx.py 7890 my_web_frame_name:application")
return
# 设置静态资源访问的路径
g_static_document_root = "./html"
# 设置动态资源访问的路径
g_dynamic_document_root = "./web"
# 将动态路径即存放py文件的路径,添加到path中,这样python就能够找到这个路径了
sys.path.append(g_dynamic_document_root)
ret = re.match(r"([^:]*):(.*)", web_frame_module_app_name)
if ret:
# 获取模块名
web_frame_module_name = ret.group(1)
# 获取可以调用web框架的应用名称
app_name = ret.group(2)
# 导入web框架的主模块
web_frame_module = __import__(web_frame_module_name)
# 获取另外一个模块可以直接调用的函数(对象)
app = getattr(web_frame_module, app_name)
print("http服务器使用的port:%s" % port)
wsgi_server = WSGIServer(port,g_static_document_root,app)
wsgi_server.run_forever()
if __name__ == "__main__":
main()
mini_frame.py
import time
def login():
return "i----login--welcome wangdao website.......time:%s" % time.ctime()
def index():
return "这是主页"
def register():
return "-----register---welcome wangdao website.......time:%s" % time.ctime()
def profile():
return "-----profile----welcome wangdao website.......time:%s" % time.ctime()
def application(environ, start_response):
# 由mini_frame框架添加响应码和头部
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
file_name = environ['PATH_INFO']
# file_name = "/index.py"
if file_name == "/index.py":
return index()
elif file_name == "/login.py":
return login()
else:
return 'Hello World! 我爱你中国....'
这个例子写的就是 关于参数的传递 以及 证明http协议的header是可以由应用程序修改,也可以由wisg进行修改。
闭包装饰器
闭包
闭包的基础使用
流程就是外圈定义一个函数名称,内圈也创建一个函数名,外圈函数的返回值是内圈函数的名字,或者说地址。
def line(k, b):
def create_y(x):
print(k*x+b)
return create_y
使用:
l1 = line(1,1)
l1(1)
实际上就是求y = 1 * 1 + 1,这种做法实际上就是类似于类,不过这边就是不断的创建函数。
而对于这种情况下,和类主要的区别就是这个l1内置的k和b都是不可进行改变的,都是在创建之初就已经设置好的。然后这个变量称作nonlocal变量,后面会再进行介绍。
函数、匿名函数、闭包、对象
- 匿名函数能够完成基本的简单功能,传递是这个函数的引用只有功能(lambda)
- 普通函数能够完成较为复杂的功能,传递是这个函数的引用只有功能
- 闭包能够将较为复杂的功能,传递是这个闭包中的函数以及数据,因此传递是功能+数据(相对于对象,占用空间少)
- 对象能够完成最为复杂的功能,传递是很多数据+很多功能,因此传递是功能+数据
修改外部函数的变量
和全局变量一样,我们在使用全局变量的过程中,在函数内使用全局变量,如果只是读取,没问题,但是如果进行修改,比如x=100,他就不知道你所使用的是全局还是新创建一个局部变量x,就需要声明是全局变量global x,而对于这里面的外部变量,则加的就是nonlocal 关键字
def test1(x1):
x2 = 200
def test2():
nonlocal x1 #如果要使用外部函数的变量,需要加nonlocal
nonlocal x2
print("----1----x1=%d" % x1)
print("----1----x2=%d" % x2)
x1 = 100
x2 = 100
print("----2----x1=%d" % x1)
print("----2----x2=%d" % x2)
return test2
t1 = test1()
t1()
虽然闭包也具有提高代码可复用性的作用,但是由于闭包引用了外部函数的局部变量,则外部函数的局部变量没有及时释放,导致消耗了内存。
装饰器
使用装饰器的 基本场景:
- 执行函数前预备处理
- 执行函数后清理功能
- 权限校验等场景
- 缓存
装饰器的基础使用
目前公司有条不紊的进行着,但是,以前基础平台的开发人员在写代码时候没有关注验证相关的问题,即:基础平台的提供的功能可以被任何人使用。现在需要对基础平台的所有功能进行重构,为平台提供的所有功能添加验证机制,即:执行功能前,先进行验证,但是有需要满足开放封闭的原则,这个时候就需要用到装饰器。
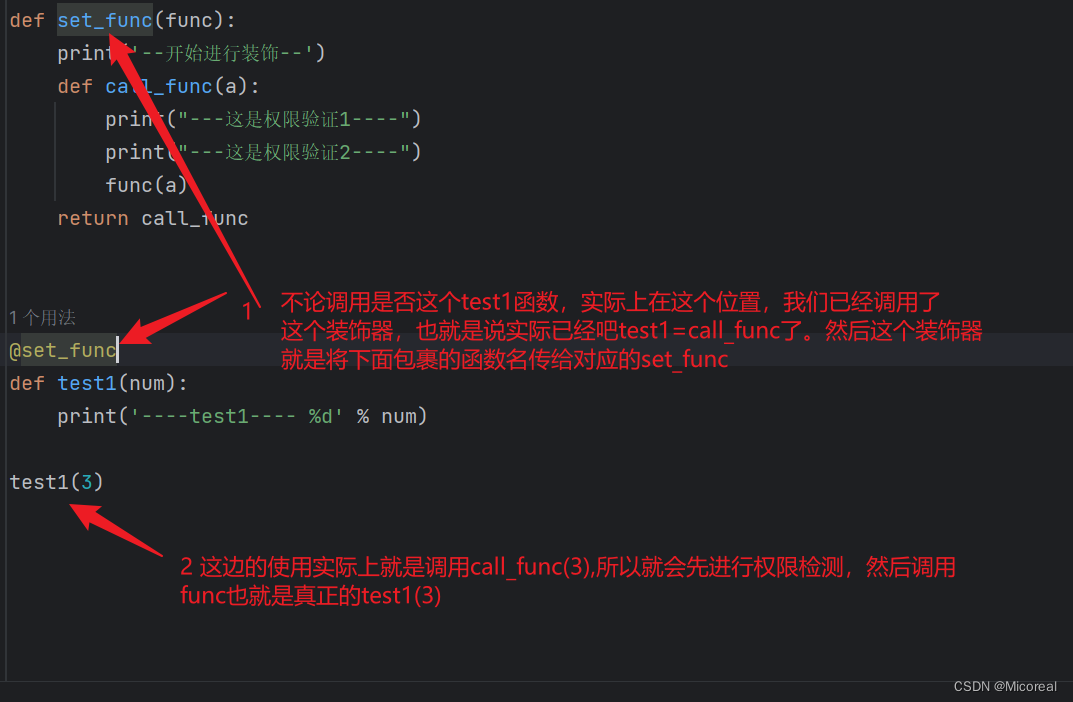
def set_func(func):
print('--开始进行装饰--')
def call_func(a):
print("---这是权限验证1----")
print("---这是权限验证2----")
func(a)
return call_func
@set_func
def test1(num):
print('----test1---- %d' % num)
test1(3)
多个装饰器的运行顺序-1
def add_first(func):
print("---开始进行装饰权限1的功能---")
def call_func(*args, **kwargs):
print("---这是权限验证1----")
return func(*args, **kwargs)
return call_func
def add_second(func):
print("---开始进行装饰权限2的功能---")
def call_func(*args, **kwargs):
print("---这是权限验证2----")
return func(*args, **kwargs)
return call_func
# 离函数越近的先装饰
@add_first
@add_second
def test1():
print('--test1--')
# s=add_second(test1)
# f=add_first(s)
# 后装饰的先执行
test1()
这个该怎么记忆呢?我们实际上就这么认为实际上这个的使用就是add_first(add_second(test1))
这样自然知道运行的顺序了:对于装饰来说,先装饰后执行;对于使用来说,先装饰先执行。
多个装饰器的运行顺序-2
那么对于输出的值,该怎么判断呢?
def makeBold(fn):
def wrapped():
return "<b>" + fn() + "</b>"
return wrapped
# 定义函数:完成包裹数据
def makeItalic(fn):
def wrapped():
return "<i>" + fn() + "</i>"
return wrapped
@makeBold
def test1():
return "hello world-1"
@makeItalic
def test2():
return "hello world-2"
@makeBold
@makeItalic
def test3():
return "hello world-3"
print(test1())
print(test2())
print(test3())
输出结果:
<b>hello world-1</b>
<i>hello world-2</i>
<b><i>hello world-3</i></b>
难点在于test3,解析一下test3,我们先调用的是"<b>" + fn() + “</b>”,所以先输出<b>,然后掉哦那个fn(),于是进入"<i>" + fn() + “</i>”,所以输出<i>,所以输出就是上文那样子。
被装饰的函数带返回值
from time import ctime, sleep
def timefun(func):
def wrapped_func():
print("%s called at %s" % (func.__name__, ctime()))
return func() #针对被装饰的函数,带参数,那么闭包内需要这么写,为了通用,都这么写
return wrapped_func
def test():
print('test')
@timefun
def foo():
print("I am foo")
@timefun
def getInfo():
return '----hahah---'
foo()
val=getInfo()
print(val)
val=test()
print(val)
装饰器带参数
from time import ctime
def timefun_arg(pro='hello'):
def timefun(func):
def wrapped_func():
print("%s called at %s" % (func.__name__, ctime()))
return func() #针对被装饰的函数,带参数,那么闭包内需要这么写,为了通用,都这么写
return wrapped_func
return timefun
@timefun_arg('Hello')
def foo():
print('I am foo')
@timefun_arg('python')
def foo1():
print('I am foo1')
foo()
foo1()
下面的装饰过程:
- 调用 timefun_arg(“Hello”)
- 将步骤 1 得到的返回值,即 time_fun 返回,然后 time_fun(foo)
- 将 time_fun(foo)的结果返回,即 wrapped_func
- 让 foo = wrapped_fun,即 foo 现在指向 wrapped
对于带参数的装饰器的分类应用
情况就是,我们在使用test1的时候只想要让他进行权限1的认证 ,test2 的时候指向让他进行权限2的认证。
def set_level(level_num):
def set_func(func):
def call_func(*args, **kwargs):
nonlocal level_num
if level_num == 1:
print("----权限级别1,验证----")
elif level_num == 2:
print("----权限级别2,验证----")
level_num=3
return func()
return call_func
return set_func
@set_level(1)
def test1():
print("-----test1---")
return "ok"
@set_level(2)
def test2():
print("-----test2---")
return "ok"
test1()
test2()
我们这边就可以使用装饰器中带参数,进行相关的判断以及使用。
类装饰器
稍微了解一下,可以这么理解,我们在使用装饰器的过程中,实际上是按照下面两个步骤进行执行的:
t = Test(foo)
t()
class Test:
def __init__(self, func):
self.__func = func
def __call__(self, *args, **kwargs):
print('权限验证')
self.__func(*args, **kwargs)
@Test
def foo(name):
print('I am foo {}'.format(name))
foo('张三')
还有就是值得关注的问题就是:我们在类内定义的函数对象,尽量要写成私有属性的,毕竟用了装饰器,大概率是不会这么进行调用,很奇怪。
装饰后类型不正确-如何解决
首先我们看下面一段代码(进而发现一个问题):
def my_decorator(func):
def wper(*args, **kwargs):
'''decorator'''
print('Calling decorated function...')
return func(*args, **kwargs)
return wper
@my_decorator
def example():
"""Docstring"""
print('Called example function')
print(example.__name__, example.__doc__)#wper decorator
输出:

你会发现这边实际上的注释已经被替换成了decortor,并不是我们想要查看的注释了,那么该怎么解决呢?
实际上引入functools中的wraps就可以解决这个问题,具体使用的话,只需要在你的装饰器函数中,再反包这个wraps装饰器,然后传入你传入的函数即可
from functools import wraps
def my_new_decorator(func):
@wraps(func)
def wper(*args, **kwargs):
'''decorator'''
print('Calling decorated function...')
return func(*args, **kwargs)
return wper
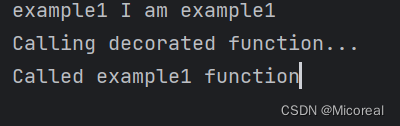
@my_new_decorator
def example1():
"""I am example1"""
print('Called example1 function')
print(example1.__name__, example1.__doc__)
example1()
此时的输出就是:
WSIG-miniWeb框架-续
WSIG-miniWeb框架-路由实现
URL_FUNC_DICT = dict()
def route(url):
def set_func(func):
URL_FUNC_DICT[url]=func
return set_func
@route('/index.py')
def index():
with open("./templates/index.html", encoding="utf-8") as f:
content = f.read()
#这是实际要从数据库里边查出来
my_stock_info = "哈哈哈,我是本月最佳员工。。。。"
content = re.sub(r"\{%content%\}", my_stock_info, content)
return content
@route('/center.py')
def center():
with open("./templates/center.html", encoding="utf-8") as f:
content = f.read()
my_stock_info = "这里是从mysql查询出来的数据。。。"
content = re.sub(r"\{%content%\}", my_stock_info, content)
return content
def application(environ, start_response):
# 由mini_frame框架添加响应码和头部
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
file_name = environ['PATH_INFO']
# file_name = "/index.py"
func=URL_FUNC_DICT[file_name]
return func()
这边我们可以看到,我们使用装饰器@route(‘/index.py’),带了参数的,但是上文的定义装饰器的时候我们只定义了两层,这样的操作实际上会导致,我们如果后面使用函数,比如直接使用index(),进入不了这个函数,原因就是这个函数指针已经被我们修改成了None,即没有进行定义,然后具体使用的话就只能使用对应的那个字典进行使用。
伪静态 静态 动态url
目前几乎所有的网页都是动态网页,只是 URL 上有些区别,一般 URL分为静态 URL、动态 URL、伪静态 URL,下面介绍一下他们的区别。
静态网页
静态网页如:域名/news/110.html 这种可以在服务器上找到,并且完整显示的页面的就属于静态页面。
优点是:
- 网站打开速度快,因为它不用进行运算;另外网址结构比较友好,利于记忆。
缺点是:
- 最大的缺点是如果是中大型网站,则产生的页面特别多,不好管理,个人觉得这一点是最重要的。
动态网页
动态 URL 类似 域名/NewsMore.asp?id=5 或者 域名/DaiKuan.php?id=17,带有?号的 URL,我们一般称为动态网址,每个 URL 只是一个逻辑地址,并不是真实物理存在服务器硬盘里的。
动态页面主要用于中大型企业,这种情况下创建的页面比较好进行管理,因为都是虚拟的页面,服务器所消耗的内存也比较少。
伪静态网页
伪静态 URL 类似 域名/course/74.html 这个 URL 和真静态 URL 类似。他是通过伪静态规则把动态 URL 伪装成静态网址。也是逻辑地址,不存在物理地址。
现在很多公司也都在使用这种做法,所以现阶段的网页都无法进行判断是不是静态还是动态网页。
log(了解)
对于输出的日志来说,虽然一般我们所使用的都是别人的第三方插件,或者所使用的框架大概率也都会有专门的 “日志”部分,但这边进行稍微学习一下,也可以对于日志的理解以及使用有相关的促进作用
详细可见:链接
log的级别
首先日志一般分为诸如下面的五个级别,从低到高的顺序依次为:
| 常见的日志级别(等级由低到高) | 说明 |
|---|---|
| DEBUG | 详细的信息,通常只出现在诊断问题上 |
| INFO | 确认一切按预期运行,比如按照日常的输出此时正在运行什么,然后结束什么的,这种log也是很有必要的,这种日志一般就是用于判断程序是否可以正常运行 |
| WARNING | 一个迹象表明,一些意想不到的事情发生了,或表明一些问题在不久的将来(例如。磁盘空间低”)。这个软件还能按预期工作。 |
| ERROR | 更严重的问题,软件没能执行一些功能 |
| CRITICAL | 十分严重的问题,这会导致程序本身直接无法继续运行 |
默认设置的级别记录的是 WARNING,即在 WARNING 或之上时才被跟踪。
log的基础使用-打印在控制台
import logging
logging.basicConfig(
level=logging.WARNING, #大于等于这里级别的日志才会输出
format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s'
)
# 开始使用log功能, 传递的参数会替换message
logging.debug('这是 loggging debug message')
logging.info('这是 loggging info message')
logging.warning('这是 loggging a warning message')
logging.error('这是 loggging error message')
logging.critical('这是 loggging critical message')
实际上不需要记忆,只需要需要使用的时候,进行相关的查找使用即可,这边我们定义level = warning 就只有日志在warning级别以上才会进行输出。

log的基础使用-打印在log文件中
import logging
logging.basicConfig(level=logging.DEBUG, #大于等于这里级别的日志才会输出
filename='log1.txt',
filemode='w', # 和文件控制符一样,这边实际上是以w的方式进行打开文件,但正常的使用是以a的方式,这边以w的方式打开是为了删除文件中的所有数据,然后方便讲解
encoding='utf8',
format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
# 开始使用log功能, 传递的参数会替换message
logging.debug('这是 loggging debug message')
logging.info('这是 loggging info message')
logging.warning('这是 loggging a warning message')
logging.error('这是 an loggging error message')
logging.critical('这是 loggging critical message')
basicConfig的参数介绍
| 参数名称 | 描述 |
|---|---|
| filename | 指定日志输出目标文件的文件名,指定该设置项后日志信心就不会被输出到控制台了 |
| filemode | 指定日志文件的打开模式,默认为’a’。需要注意的是,该选项要在filename指定时才有效 |
| format | 指定日志格式字符串,即指定日志输出时所包含的字段信息以及它们的顺序。logging模块定义的格式字段下面会列出。 |
| datefmt | 指定日期/时间格式。需要注意的是,该选项要在format中包含时间字段%(asctime)s时才有效 |
| level | 指定日志器的日志级别 |
| stream | 指定日志输出目标stream,如sys.stdout、sys.stderr以及网络stream。需要说明的是,stream和filename不能同时提供,否则会引发 ValueError异常 |
| style | Python 3.2中新添加的配置项。指定format格式字符串的风格,可取值为’%‘、’{‘和’$‘,默认为’%’ |
| handlers | Python 3.3中新添加的配置项。该选项如果被指定,它应该是一个创建了多个Handler的可迭代对象,这些handler将会被添加到root logger。需要说明的是:filename、stream和handlers这三个配置项只能有一个存在,不能同时出现2个或3个,否则会引发ValueError异常。 |
logging模块定义的格式字符串字段
| 字段/属性名称 | 使用格式 | 描述 |
|---|---|---|
| asctime | %(asctime)s | 日志事件发生的时间–人类可读时间,如:2003-07-08 16:49:45,896 |
| created | %(created)f | 日志事件发生的时间–时间戳,就是当时调用time.time()函数返回的值 |
| relativeCreated | %(relativeCreated)d | 日志事件发生的时间相对于logging模块加载时间的相对毫秒数(目前还不知道干嘛用的) |
| msecs | %(msecs)d | 日志事件发生事件的毫秒部分 |
| levelname | %(levelname)s | 该日志记录的文字形式的日志级别(‘DEBUG’, ‘INFO’, ‘WARNING’, ‘ERROR’, ‘CRITICAL’) |
| levelno | %(levelno)s | 该日志记录的数字形式的日志级别(10, 20, 30, 40, 50) |
| name | %(name)s | 所使用的日志器名称,默认是’root’,因为默认使用的是 rootLogger |
| message | %(message)s | 日志记录的文本内容,通过 msg % args计算得到的 |
| pathname | %(pathname)s | 调用日志记录函数的源码文件的全路径 |
| filename | %(filename)s | pathname的文件名部分,包含文件后缀 |
| module | %(module)s | filename的名称部分,不包含后缀 |
| lineno | %(lineno)d | 调用日志记录函数的源代码所在的行号 |
| funcName | %(funcName)s | 调用日志记录函数的函数名 |
| process | %(process)d | 进程ID |
| processName | %(processName)s | 进程名称,Python 3.1新增 |
| thread | %(thread)d | 线程ID |
| threadName | %(thread)s | 线程名称 |
这边给出个人常用的 格式:
format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %
(message)s'
使用类-既要打印到控制台也要输入到文件中
绝大多数使用都是在使用这种。
import logging
# 第一步,创建一个logger
logger=logging.getLogger()
logger.setLevel(logging.DEBUG)
# 第二步,创建一个handler,用于写入日志文件
fh=logging.FileHandler('log2.txt','a',encoding='utf8')
fh.setLevel(logging.DEBUG) # 输出到file的log等级的开关
# 第三步,再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.WARNING) # 输出到console的log等级的开关
# 第四步,定义handler的输出格式
formatter = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s")
fh.setFormatter(formatter)
ch.setFormatter(formatter)
#第五步,把fh和ch添加到logger中
logger.addHandler(fh)
logger.addHandler(ch)
# 日志
logger.debug('这是 logger debug message')
logger.info('这是 logger info message')
logger.warning('这是 logger warning message')
logger.error('这是 logger error message')
logger.critical('这是 logger critical message')















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









