







—、简介
众所周知,字典内部是采用哈希表结构实现的。redis也不例外,代码位于dict.c 和 dict.h。为了解决hash键冲突的问题,redis采用“拉链法”设计。
由于网上有大量的hash结构及相关操作说明,笔者将不再介绍。本文的重点主要讲解dict的数据结构、运作流程及rehash实现。
二、数据结构
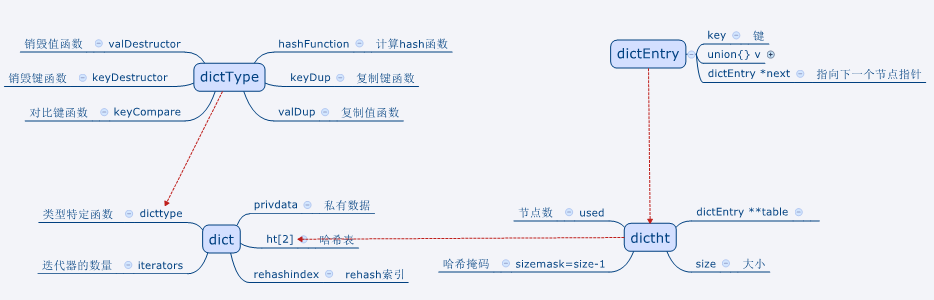
redis字典由dictEntry(节点)、dictType(类型)、dictht(哈希表)、dict(字典)、dictIterator(迭代器)结构组成。下面主要讲解下dictEntry、dictht、dict结构。
1).首先,介绍哈希表节点的结构(dictEntry)
typedef struct dictEntry {
void *key; //键
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; //值
struct dictEntry *next; //指向下一个元素指针
} dictEntry;上面的注释已经说明其代表的含义。考虑到节点值类型多元化及节约空间的缘故,节点值采用联合体进行设计。
2).接下来,了解哈希表结构(dictht)
typedef struct dictht {
dictEntry **table; //hash链表
unsigned long size; //hash大小
unsigned long sizemask; //hash掩码
unsigned long used; //节点数量
} dictht;哈希表结构同样很简洁,只用了4个属性表示。这里说明一下,sizemask不是固定值,sizemask=size-1。至于原因,后面会讲解。
3).最后,分析下dict结构
typedef struct dict {
dictType *type; //类型
void *privdata;
dictht ht[2]; //哈希表
long rehashidx; //rehash索引,-1代表未进行rehash
int iterators;
} dict;这里留意一下 ht[2], 表明dict使用了两个hash表,默认使用0号哈希表。当rehash≠-1(rehash进行中)时,系统会将0号哈希表的数据迁移至1号哈希表。
好了,dict的三种数据结构已经介绍完了,还有dictType、dictIterator两种结构在此就不一一介绍。大家可以从下图了解下。
三、运作流程
上面简单介绍了dict的数据结构,下面将介绍dict的运作流程。为了更详细、更清楚地理解其机制,我们从dict创建开始分析。
1).创建dict的流程:dictCreate->_dictInit->_dictReset
//重置hash表
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
//创建hash表
dict *dictCreate(dictType *type,void *privDataPtr)
{
//申请空间
dict *d = zmalloc(sizeof(*d));
//初始化hash结构
_dictInit(d,type,privDataPtr);
return d;
}
//初始化hash表
int _dictInit(dict *d, dictType *type,void *privDataPtr)
{
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->rehashidx = -1;
...省略部分代码...
return DICT_OK;
}由dictCreate创建一个字典*d,并将d传入_dictInit函数。而_dictInit函数将负责*d初始化操作。在_dictInit内部调用 _dictReset初始化ht[0]和ht[1]数据结构。
从_dictReset函数我们可以看到,新建dict时未对ht[0]、ht[1]分配空间,那么系统会在什么时候进行分配操作呢? 答案是在调用dictAdd操作时.
2).dictAdd,顾名思义,就是dict的添加操作。dictAdd的调用流程为:dictAddRaw->dictSetVal
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}dictAddRaw会检查d是否存在key,如果存在,则返回NULL,否则创建key节点。
dictSetVal:顾名思义,设置节点的值。
我们看下dictAddRaw函数代码。
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
//判断是否在进行rehash操作
if (dictIsRehashing(d)) _dictRehashStep(d);
//检查key是否存在,如果存在,则返回NULL
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
//判断rehash是否正在进行,如果正在进行,则往ht[1]添加数据,否则添加至ht[0]
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
//创建key节点
entry = zmalloc(sizeof(*entry));
//将节点的指针指向对应的链表头部
entry->next = ht->table[index];
//添加节点至链表头部
ht->table[index] = entry;
//更新used值
ht->used++;
//设置节点信息
dictSetKey(d, entry, key);
return entry;
}从上面可以看出,代码执行顺序:dictIsRehashing->_dictKeyIndex->dictIsRehashing->dictSetKey.细心的童鞋可能注意到,该函数内部调用两次dictIsRehashing。难道在_dictKeyIndex函数期间dict结构会发生变化么?
追踪下_dictKeyIndex代码:
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
//计算key hash值
h = dictHashKey(d, key);
//查找key,如果存在,则返回-1,否则返回hash索引
for (table = 0; table <= 1; table++) {
//计算hash索引
idx = h & d->ht[table].sizemask;
//从hash索引对应的链表中搜索
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return -1;
he = he->next;
}
//如果rehash未进行,则只需搜索ht[0]
if (!dictIsRehashing(d)) break;
}
return idx;
}从_dictKeyIndex内部,可以看到_dictExpandIfNeeded函数。根据字面意思推测,这个应该与dict空间有关联(即ht->size)。继续追踪_dictExpandIfNeeded代码。
//判断dict是否需要扩展空间
static int _dictExpandIfNeeded(dict *d)
{
//rehash正在进行,则不进行操作
if (dictIsRehashing(d)) return DICT_OK;
//如果size=0,则设置默认大小
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
//当负载因子(used/size)>=1时,对以下两种情况扩展空间。
//1. dict_can_resize=1
//2. 达到强制resize条件时(used/size>dict_force_resize_ratio)。
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}对于新建的dict,执行的代码为dictExpand(d, DICT_HT_INITIAL_SIZE)。DICT_HT_INITIAL_SIZE在dict.h文件被定义,值为4.我们再追踪下dictExpand函数。
int dictExpand(dict *d, unsigned long size)
{
//dict的扩展空间大小:最小一个>=size的2^N数
unsigned long realsize = _dictNextPower(size);
...省略部分代码...
//设置dict大小
n.size = realsize;
//设置hash掩码
n.sizemask = realsize-1;
//初始化table空间
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
//如果dict是否为空(初始化操作),则将n设置为ht[0]
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
//将n赋给ht[1],并设置rehash索引
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}从上面的代码可以看出,ht[0]和ht[1]的内存分配都是在这里进行的。对于一个为空的dict,系统会为ht[0]分配空间。对于一个非空的dict,系统则为ht[1]分配空间,并重置rehashidx标识。
现在应该知道dictAddRaw函数内部执行_dictKeyIndex之后再次调用 dictIsRehashing的原因了吧。
好了,总结下dictAdd的流程:dictAdd->dictAddRaw->_dictKeyIndex->_dictExpandIfNeeded->dictExpand。
3).dictReplace:顾名思义,替换功能,分为两种情形:当key不存在,则进行创建;当key存在,则修改key的值。代码执行流程:dictAdd->dictFind->dictSetVal
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, auxentry;
//如果key不存在,则进行创建
if (dictAdd(d, key, val) == DICT_OK)
return 1;
//如果key存在,则找到相应的节点
entry = dictFind(d, key);
//修改节点的值
dictSetVal(d, entry, val);
...省略部分代码...
}4).dictDelete:删除节点功能,内部调用dictGenericDelete,dictGenericDelete的代码比较简单,由于篇幅关系,这里就不介绍了.
四、rehash
为了解决hash冲突问题,哈希表引入链表来保存hash冲突的数据。当所有key的hash值都一样时,此时,哈希表也就演变成单链表,时间复杂度由O(1)->O(n).这是非常糟糕的情况。为了尽量避免这种情况的发生,redis内部设计了一套rehash机制。
1).rehash条件
根据不同的场景,rehash可分为”扩展空间”和”缩减空间”两种。
a).扩展空间以dictAdd函数为入口。在适当的条件下,最终调用dictExpand实现。而dictExpand会为ht[1]重新分配空间,并重置rehashidx索引值,为后面的rehash迁移做铺垫。
触发条件:
ht[0].used/ht[0].size>=1 && (dict_can_resize=1 || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
used/size: 负载因子
dict_can_resize: 是否开启resize标识 1:开启 0:关闭
dict_force_resize_ratio:强制resize的条件(默认值为5)b).缩减空间的入口函数为dictResize,内部同样调用了dictExpand。redis的server.db定期检查有使用到(于redis.c/htNeedsResize),在这里就不过多介绍了,有兴趣的童鞋可以了解下。
2).rehash实现
简单来说,rehash就是将数据迁移一个更大或者更小的新哈希表中。整个过程采用“平摊的渐进式”方式设计,结合ht[0]和ht[1]来实现。代码如下:
int dictRehash(dict *d, int n) {
//遍历ht[0],最多执行n个下标的迁移
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
...省略部分代码...
de = d->ht[0].table[d->rehashidx];
while(de) {
unsigned int h;
nextde = de->next;
//将ht[0]数据迁移至ht[1]
//重新计算hash值
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
//将数据添加至表头
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
//光标后移一位
d->rehashidx++;
}
//判断是否迁移完毕
if (d->ht[0].used == 0) {
//如果迁移完毕,则将ht[1]赋给ht[0],同时重置ht[1]
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
return 1;
}从上面的代码我们可以看出,迁移分为两步操作:
a). 将ht[0]数据迁移至ht[1]
b). 待迁移完毕,将ht[1]复制给ht[0],重置ht[1]数据及rehashidx索引值
当ht[0]的数据量达到近十万、百万的时候,迁移工程非常之巨大,整个过程也将会非常耗时。试想一下,如果系统采用一次性迁移时,那么在数据迁移的这段时间内,系统将无法提供其他方面的服务。对于一个高可用的架构来说,这无疑是致命的。
为了防止这种情况的发生,redis采用了渐进式的设计。将整个rehash工程平摊到 dict的增删改查等操作。嵌入各函数的代码如下:
if (dictIsRehashing(d)) _dictRehashStep(d);而 _dictRehashStep函数内部调用了dictRehash方法.
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}五、总结
1). dict是redis核心结构之一,内部使用了哈希表来实现;
2). 为了尽量避免dict演变成链表,在特定的条件下,dict会进行rehash操作;
3). 考虑到dict空间利用率可能会越来越低,dict提供了resize方法,可用于缩减空间(server.db的定期检查有用到);
4). 基于性能的考虑,dict的rehash采用了“渐进式”设计方案;















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









