






具身智能(Embodied Intelligence)是一种先进的人工智能概念,它强调机器人或智能体通过感知、理解并与环境互动来适应并执行任务。这种智能形式与传统的基于规则或符号的人工智能有显著区别,因为它将感知和行动紧密结合,使智能体能够更深入地理解其所处的环境及其与环境的互动方式。具身智能被视为实现通用人工智能(AGI)的关键路径,近年来在这一领域的研究取得了许多创新性的成果。
例如,李飞飞教授的团队开发的VoxPoser系统就是具身智能领域的一个突破。为了帮助大家更好地了解这一领域的最新进展,我整理了13篇今年发表的具身智能相关论文,每篇都提供了简要的介绍。以下是这些论文的概览,强烈推荐您阅读原文以获得更深入的理解

三篇论文详解
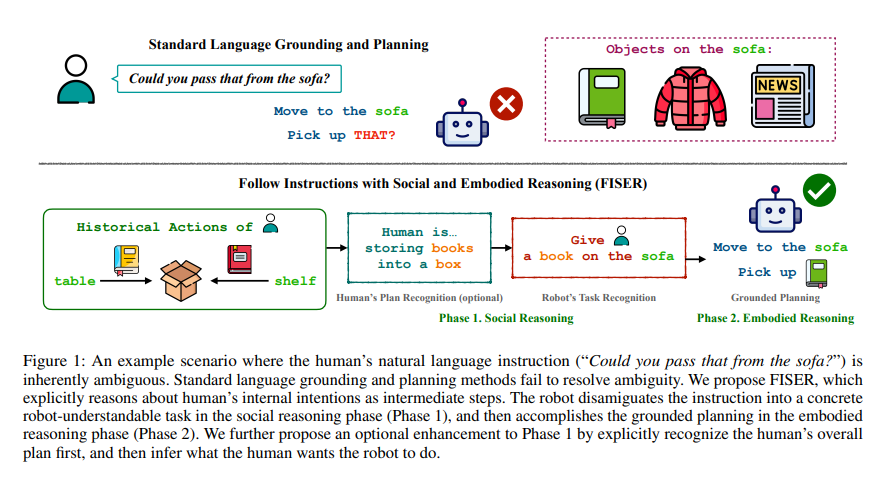
1、Infer Human’s Intentions Before Following Natural Language Instructions
IMG_256
这篇文章介绍了一种新的框架——Follow Instructions with Social and Embodied Reasoning (FISER),旨在提高人工智能代理遵循自然语言指令执行协作任务的能力。文章的核心在于解决人类指令中固有的歧义问题,这通常是由于人类说话者假设听者拥有足够的背景知识而省略了一些信息。
研究方法:
FISER框架通过将人类的意图作为显式的推理步骤来解决歧义问题。具体来说,框架分为两个阶段:社交推理和身体化推理。在社交推理阶段,模型需要根据当前状态和人类历史行为的观察来消除自然语言指令的歧义;而在身体化推理阶段,机器人则根据已经明确的任务进行规划和执行。
创新点:
-
显式意图推理:文章的创新之处在于明确地将人类的意图作为推理过程中的一个中间步骤,而不是试图直接从指令中推断出行动计划。
-
社交推理与身体化推理的分离:FISER框架将问题分解为两个部分,分别对应社交和身体化推理,这种分离有助于更有效地处理复杂的任务。
-
人类计划识别阶段:文章进一步提出了一个可选的增强阶段,即通过使用一组逻辑谓词来帮助推断人类的总体计划。
在实验验证方面,作者们实现了基于Transformer的模型,并在一个具有挑战性的基准测试HandMeThat上进行了评估。实验结果表明,使用社交推理显式推断人类意图的方法,比纯粹的端到端方法有更好的性能。
实验结果:
FISER模型在测试集上的平均成功率为64.5%,在HandMeThat基准测试中达到了最先进的水平。这一结果支持了文章的假设,即通过显式建模人类的意图作为中间推理步骤可以显著提高执行模糊自然语言指令的性能。
实验验证:
为了测试FISER框架的有效性,作者们将其与多个竞争基线进行了比较,包括在HMT上的最新工作和对最大可用预训练语言模型的CoT提示。实验表明,使用FISER框架的模型在所有难度级别上的表现都优于端到端推理和CoT提示的LLMs。
总的来说,这篇文章通过提出一个新的框架,有效地解决了人工智能领域中的一个重要问题,并在实验中验证了其有效性。文章的方法和创新点为未来人工智能代理更好地理解和执行人类的指令提供了新的思路。
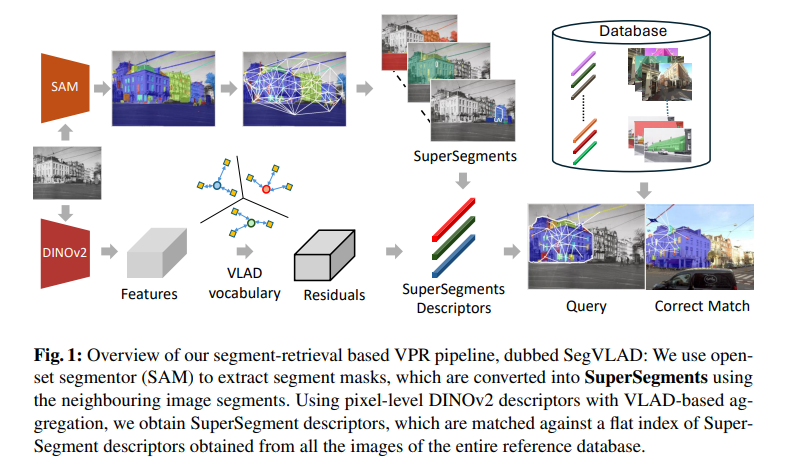
2、Revisit Anything: Visual Place Recognition via Image Segment Retrieval
IMG_257
这篇文章提出了一种名为 SegVLAD(Segment based Vector of Locally Aggregated Descriptors)的新方法,用于改进视觉定位和导航中的视觉位置识别(VPR)。该方法的核心在于通过编码和检索图像片段而不是整个图像来提高识别的准确性。
研究方法:
文章首先使用开放集图像分割技术将图像分解为有意义的实体(即“事物”和“材料”),从而创建了一种新的图像表示方法——SuperSegment。这种方法通过连接图像中的片段及其邻近片段来形成多个重叠的子图。接着,为了有效地将这些SuperSegment编码成紧凑的向量表示,文章提出了一种新颖的因子化特征聚合方法。
创新点:
-
SuperSegment表示法:文章提出了一种基于片段及其邻域的新图像表示方法,称为SuperSegment。这种方法通过Delaunay三角剖分构建图像片段的图,并使用邻接矩阵来扩展每个片段的上下文,从而生成多个重叠的SuperSegment。
-
因子化特征聚合:文章提出了一种新的因子化特征聚合方法,该方法可以有效地处理片段级别的信息以及片段邻域信息,以生成SuperSegment描述符。
-
基于相似性的加权排名方法:文章提出了一种将基于片段级别的检索转换为图像级别检索的相似性加权排名方法。
文章通过在多个具有挑战性的数据集上进行实验,证明了所提出的基于片段的检索方法能够在大视角变化下实现位置识别,而基于全局描述符的检索方法在这种情况下表现不佳。SegVLAD在多个基准数据集上达到了新的最高标准。
实验验证方面:
文章在包括室内和室外环境的多个数据集上评估了SegVLAD的性能,并与最新的VPR方法进行了比较。实验结果表明,无论是使用预训练的DINOv2还是针对VPR任务进行微调的DINOv2作为特征背板,SegVLAD在大多数数据集上都实现了更好的识别性能。
此外,文章还介绍了将SegVLAD应用于对象实例检索任务的实验,展示了该方法在识别特定场所中特定对象方面的潜力。通过一系列的消融实验和参数研究,文章证明了所提出方法的设计选择的有效性,并强调了其作为一种开放集片段基础的粗略检索器的有效性。
局限性和未来工作:
尽管SegVLAD在多个基准数据集上取得了优异的性能,但文章也指出了其局限性,包括较大的地图尺寸和存储需求。文章提出可以通过简单的措施,例如基于IOU的过滤,来减少数据库片段的冗余和存储需求。未来的工作可能会探索将基于片段的粗略检索器与基于片段的重新排序器(如MESA)紧密结合的层次化VPR管道,从而完全摆脱对全局整图描述符的依赖。此外,基于片段的表示隐含了语义信息,为创建基于文本的界面提供了自然的方式,这可以很容易地与最近在这方面的努力集成。
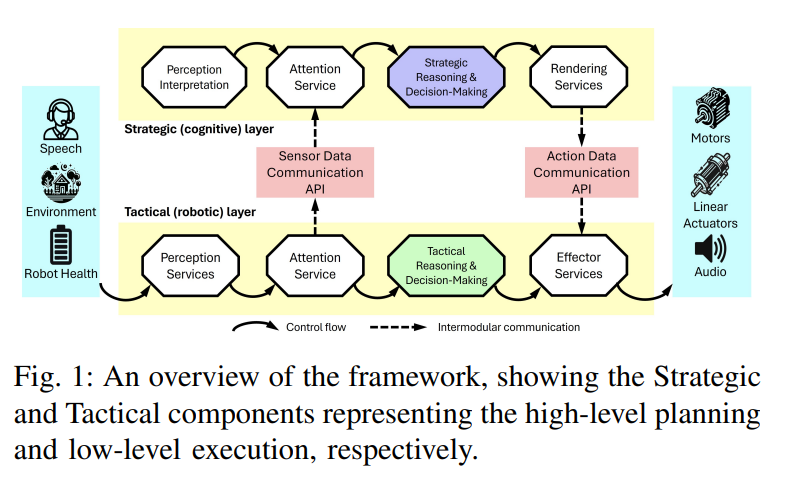
3、HARMONIC: Cognitive and Control Collaboration in Human-Robotic Teams
IMG_258
这篇文章介绍了一种新型的多机器人规划和协作方法,称为HARMONIC(Human-AI Robotic Team Member Operating with Natural Intelligence and Communication),旨在通过整合认知策略、自然语言通信和可解释性来提升人-机器人团队中的机器人能力。该方法的核心是展示机器人如何在人-机器人团队中运用元认知、自然语言沟通和可解释性来执行复杂任务。
研究方法:
文章中提出的HARMONIC架构在两个层面上运作:战略认知层面和战术控制层面。战略层面负责需要推理的操作,而战术层面则负责基于技能的、自动的、反射性的操作。这种双控制层面的方法允许机器人在实时调整优先级和动作的同时,处理计算延迟、意外情况、安全问题和资源优化。
创新点:
-
元认知和自然语言沟通:机器人不仅能够理解团队任务和组织结构,还能使用自然语言与人类队友沟通,提供动作和决策的解释,从而增强了透明度和可解释性。
-
认知策略:机器人能够推理计划、目标和态度,并能够解释自己和他人的行为原因。
-
分布式HARMONIC架构:该架构灵活地整合了认知和机器人控制执行能力,允许机器人在战略和战术层面上进行并行操作。
文章通过模拟实验验证了所提出方法的有效性,实验涉及一个由地面无人车(UGV)、无人机和人类队员组成的异构机器人团队执行联合搜索任务。模拟环境展示了人-机器人团队如何处理复杂场景、不同能力机器人之间的有效动作协调,以及自然人-机器人通信。
实验验证方面:
在模拟的公寓环境中,UGV作为领导者,负责与人类和无人机进行互动,而无人机则负责空中扫描任务。实验中,机器人能够根据战略层推理的结果采取行动,并通过行为树(BTs)在战术层执行搜索任务。机器人还能够使用自然语言与人类沟通,并根据情况调整语言沟通方式。
局限性和未来工作:
尽管HARMONIC在模拟环境中展示了其潜力,但文章指出未来工作将集中在扩展机器人能够成功操作的任务和场景范围;增强机器人的学习能力;使用真实机器人在真实环境中进行试验以验证框架的有效性;开发协作在线规划策略;以及提高动态环境中的实时适应性。
结论:
这篇文章展示了一个认知机器人团队成员的框架,该框架能够在人-机器人团队中实现有效的协作。HARMONIC架构通过结合战略认知处理和战术控制,使机器人展现出包括团队任务理解、情景记忆利用和多模态感知解释在内的元认知能力。通过整合自然语言通信和推理能力,该方法促进了复杂的团队互动,提高了可解释性,并建立了信任,这是人-机器人协作中的关键因素。与基于LLMs或VLAs的黑盒模型不同,系统的玻璃盒特性为人类提供了透明度和可解释性。通过模拟搜索任务展示了HARMONIC在真实世界应用中的潜力。未来的研究将集中在扩展HARMONIC代理成功操作的任务和场景范围,增强机器人的学习能力,并在多样化的操作环境中使用真实机器人进行试验,以验证框架的有效性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









