







使用python爬取北京新发地市场的蔬菜、水果等的价格,并将爬取结果存储至mongoDB的数据库中。
使用到的软件:
1.anaconda3
2.mongoDB
3.Navicat Premium
需要安装的python第三方库:
1.Scrapy爬虫框架
2.pymongo
步骤:
一、预备工作
1.启动mongoDB
启动方式有多种,这里展示用命令提示符进行启动

如上图示,则启动成功,还可在浏览器中输入http://127.0.0.1:27017/进行查询,返回如下界面也启动成功

2.打开Navicat,建立到mongoDB的连接,输入连接名,如mongodb

二、爬虫部分
1.启动anaconda的prompt命令行,新建一个叫xinfadi的爬虫工程
scrapy startproject xinfadi
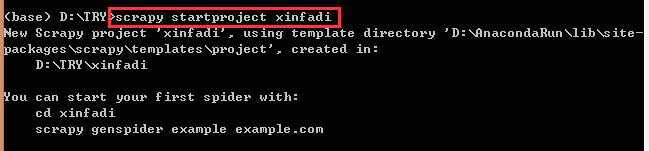
可发现电脑的D:\TRY目录下多了一个xinfadi的文件夹,表明爬虫工程创建成功。

2.创建好爬虫工程之后可以创建爬虫,一个爬虫工程中可包含多个爬虫
scrapy genspider xinfadi_spider www.xinfadi.com.cn

在该工程下多了xinfadi_spider.py文件
3.打开sittings文件,对其进行编辑

在该文件末尾加上USER_AGENT的代码:

单引号中的内容可在要爬取的网页右击-“检查”进行查看

User-Agent 表明访问网站的是一个什么样的程序。在代码中设置一下,让网站认为这是一个浏览器在访问,而不是爬虫在访问。
还可根据情况,对如下的一些参数进行更改

设置好之后关闭sittins文件,可在终端调试一下。

运行结果大致这样就表明没错(注意看看终端的输出中有无"Error"、"Warning"等字样)
4.打开xinfadi_spider.py,对其内容进行改造
# -*- coding: utf-8 -*-
import scrapy
class XinfadiSpiderSpider(scrapy.Spider):
name = 'xinfadi_spider'
allowed_domains = ['www.xinfadi.com.cn']
start_urls = ['http://www.xinfadi.com.cn/marketanalysis/1/list/1.shtml'] #开始爬取的网页
def parse(self, response):
for e in response.xpath('//*[@class="hq_table"]//tr')[1:]:
print(e.xpath('./td//text()').extract())
(这几句代码其实涉及较多的爬虫知识,在写的过程中最好在prompt上进行适当地调试)
更改之后,关闭文件,在prompt上试运行,网页第1页的内容输出了:

5.自动获取后面的网页的链接
因要爬取的网页有多页,可设置自动获取要爬取的网页的链接。更改xinfadi_spider,py
# -*- coding: utf-8 -*-
import scrapy
from ..items import XinfadiItem #将数据项的定义导入到爬虫
from scrapy import Request
class XinfadiSpiderSpider(scrapy.Spider):
name = 'xinfadi_spider'
allowed_domains = ['www.xinfadi.com.cn']
start_urls = ['http://www.xinfadi.com.cn/marketanalysis/1/list/1.shtml'] #开始爬取的网页
def parse(self, response): #一次性爬取,将爬取的内容存在response中,再进行解析
for e in response.xpath('//*[@class="hq_table"]//tr')[1:]:
#print(e.xpath('./td//text()').extract())
xfd_item=XinfadiItem() #每爬取一项数据,就创建一个新的数据项
#对列表中的每个数据进行整体赋值
xfd_item['shop_name'],\
xfd_item['low_price'],\
xfd_item['avg_price'],\
xfd_item['high_price'],\
xfd_item['specification'],\
xfd_item['unit'],\
xfd_item['release_date']=e.xpath('./td//text()').extract()
print(xfd_item)
yield(xfd_item) #生成数据项给框架,很重要,缺少它爬虫会一直进行下去,哪怕添加条目限制
next_url=response.xpath('//*[@title="下一页"]/@href').extract_first()
if next_url is not None:
yield Request(response.urljoin(next_url),callback=self.parse,dont_filter=True)
保存,调试。如果爬取所有的数据用时可能比较长,可对爬取的条目进行限定
scrapy crawl xinfadi_spider -s CLOSESPIDER_ITEMCOUNT=20
三、将爬取的结果存到csv文件中
1.打开items.py文件,定义数据项(数据格式)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class XinfadiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
shop_name = scrapy.Field()
low_price = scrapy.Field()
avg_price = scrapy.Field()
high_price = scrapy.Field()
specification = scrapy.Field() #产地
unit = scrapy.Field()
release_date = scrapy.Field() #发布日期
#pass
2.关闭items.py,再在xinfadi_spider.py中应用items,py的更改
# -*- coding: utf-8 -*-
import scrapy
from ..items import XinfandiItem #将数据项的定义导入到爬虫
class XinfadiSpiderSpider(scrapy.Spider):
name = 'xinfadi_spider'
allowed_domains = ['www.xinfadi.com.cn']
start_urls = ['http://www.xinfadi.com.cn/marketanalysis/1/list/1.shtml'] #开始爬取的网页
def parse(self, response): #一次性爬取,将爬取的内容存在response中,再进行解析
for e in response.xpath('//*[@class="hq_table"]//tr')[1:]:
#print(e.xpath('./td//text()').extract())
xfd_item=XinfandiItem() #每爬取一项数据,就创建一个新的数据项
#对列表中的每个数据进行整体赋值
xfd_item['shop_name'],\
xfd_item['low_price'],\
xfd_item['avg_price'],\
xfd_item['high_price'],\
xfd_item['specification'],\
xfd_item['unit'],\
xfd_item['release_date']=e.xpath('./td//text()').extract()
print(xfd_item)
关闭文件,可在prompt中进行调试
3.生成csv文件
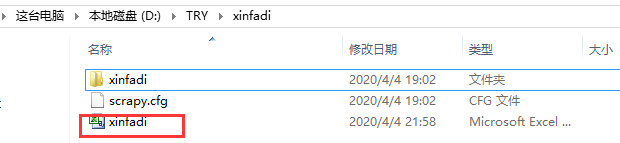
scrapy crawl xinfadi_spider -o xinfadi.csv
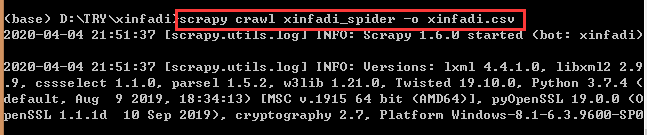
可发现爬虫工程中队列csv文件
四、将爬取的结果保存到mongoDB中
1.打开pipelines.py,为数据的保存做一个管道链接
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#导入相应的库
from scrapy.item import Item
from .items import XinfadiItem
from pymongo import MongoClient
class XinfadiPipeline(object):
def process_item(self, item, spider):
return item
class XinfadiMongoDBPipeline:
def open_spider(self, spider):
db_uri = spider.settings.get('MONGO_DB_URI', 'mongodb://localhost:27017/')
db_name = spider.settings.get('MONGO_DB_NAME', 'only_for_test')
self.db_client = MongoClient(db_uri)
self.db = self.db_client[db_name]
def close_spider(self, spider):
self.db_client.close()
#处理数据时,就将其插入到数据库中
def process_item(self, item, spider):
self.insert_db(item)
return item
def insert_db(self, item):
if isinstance(item, XinfadiItem):
item = dict(item)
self.db[XinfadiItem.__name__].insert_one(item)
2.再在Sittings.py中做如下更改:
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
#'xinfadi.pipelines.XinfadiPipeline': 300,
'xinfadi.pipelines.XinfadiMongoDBPPipeline': 300,
}
改完之后,即可试运行,爬取结果在数据库中生成了
















 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









