







首先,确保安装库'requests','beautifulsoup4','pandas',若未安装在cmd运行以下命令。
pip install requests beautifulsoup4 pandas
import requests
from bs4 import BeautifulSoup
import pandas as pd
import os
# 创建保存图片的目录
os.makedirs('douban_movie_posters', exist_ok=True)
# 目标网址
url = "https://movie.douban.com/top250"
# 存储电影信息的列表
movies = []
# 请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 解析页面内容
def parse_page(soup):
movie_list = soup.find_all('div', class_='item')
for movie in movie_list:
# 确保找到电影标题和图片链接
title_tag = movie.find('span', class_='title')
img_tag = movie.find('img')
if title_tag and img_tag:
title = title_tag.text
img_url = img_tag['src']
movies.append({"Title": title, "Image URL": img_url})
# 下载并保存图片
download_image(title, img_url)
print(f"Successfully scraped: {title}")
else:
print("Error parsing movie item:", movie)
# 下载图片
def download_image(title, img_url):
response = requests.get(img_url)
if response.status_code == 200:
# 生成文件名,去掉不合法的字符
file_name = f"douban_movie_posters/{title.replace('/', '')}.jpg"
with open(file_name, 'wb') as f:
f.write(response.content)
else:
print(f"Failed to download image for {title}, status code: {response.status_code}")
# 获取每一页的数据
for i in range(0, 250, 25):
response = requests.get(url + f"?start={i}&filter=", headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
parse_page(soup)
else:
print(f"Failed to retrieve page {i // 25 + 1}, status code: {response.status_code}")
# 转换为DataFrame并显示
df = pd.DataFrame(movies)
print(df)
# 将结果保存为Excel文件
excel_file = "douban_top250_movies.xlsx"
df.to_excel(excel_file, index=False)
print(f"Data saved to {excel_file}")
爬取结果如下所示。
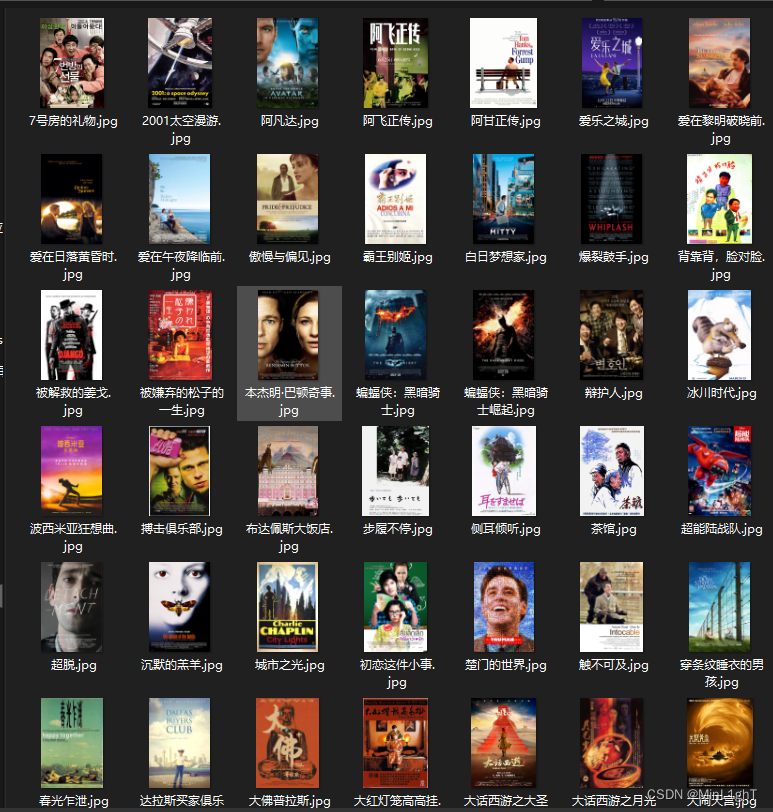
| Title | Image URL |
| 肖申克的救赎 | https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg |
| 霸王别姬 | https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2561716440.jpg |
| 阿甘正传 | https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2372307693.jpg |
| 泰坦尼克号 | https://img9.doubanio.com/view/photo/s_ratio_poster/public/p457760035.jpg |
| 千与千寻 | https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2557573348.jpg |
| 这个杀手不太冷 | https://img2.doubanio.com/view/photo/s_ratio_poster/public/p511118051.jpg |
| 美丽人生 | https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2578474613.jpg |
| 星际穿越 | https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2614988097.jpg |
| 盗梦空间 | https://img9.doubanio.com/view/photo/s_ratio_poster/public/p513344864.jpg |
| 楚门的世界 | https://img3.doubanio.com/view/photo/s_ratio_poster/public/p479682972.jpg |
| 辛德勒的名单 | https://img3.doubanio.com/view/photo/s_ratio_poster/public/p492406163.jpg |
| 忠犬八公的故事 | https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2587099240.jpg |
| 海上钢琴师 | https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2574551676.jpg |
| 三傻大闹宝莱坞 | https://img2.doubanio.com/view/photo/s_ratio_poster/public/p579729551.jpg |
| 放牛班的春天 | https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2884280708.jpg |
| 机器人总动员 | https://img2.doubanio.com/view/photo/s_ratio_poster/public/p1461851991.jpg |
| 疯狂动物城 | https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2614500649.jpg |
| 无间道 | https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2564556863.jpg |
| 控方证人 | https://img1.doubanio.com/view/photo/s_ratio_poster/public/p1505392928.jpg |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









