






实验 1:K-近邻算法及应用
实验目的:
- 熟悉K-近邻算法的原理;
- 掌握线性回归的实现;
- 熟悉
matplotlib可视化库的使用; - 掌握
sklearn库的基本用法; - 应用
sklearn中的K-近邻分类函数对鸢尾花数据集进行分类,测试并计算在测试集上的准确率、召回率和精准率,并绘制混淆矩阵。import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score # 加载数据集 iris = load_iris() X = iris.data y = iris.target # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # K-近邻分类器 knn = KNeighborsClassifier(n_neighbors=3) knn.fit(X_train, y_train) # 预测 y_pred = knn.predict(X_test) # 计算准确率、召回率和精准率 accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred, average='macro') recall = recall_score(y_test, y_pred, average='macro') # 混淆矩阵 cm = confusion_matrix(y_test, y_pred) # 输出结果 print(f"准确率: {accuracy}") print(f"精准率: {precision}") print(f"召回率: {recall}") print(f"混淆矩阵:\n{cm}") # 绘制混淆矩阵 plt.matshow(cm, cmap=plt.cm.Blues) plt.title('Confusion Matrix') plt.colorbar() plt.xlabel('Predicted') plt.ylabel('Actual') plt.show()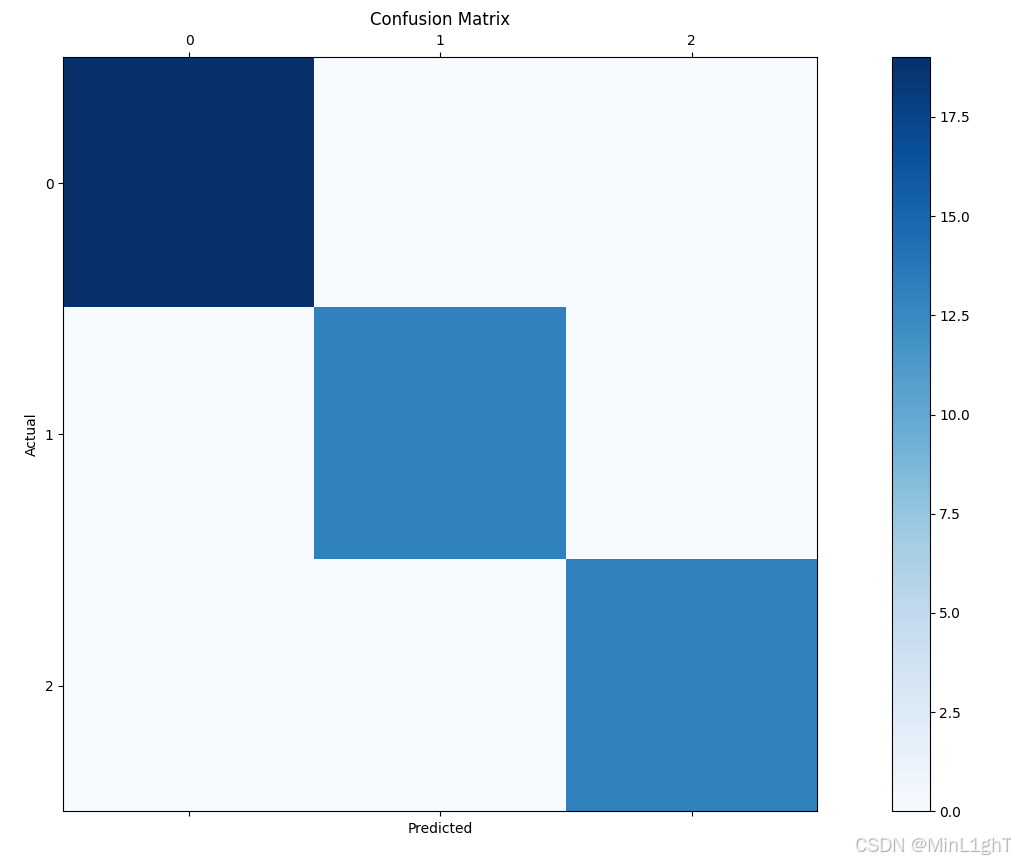
准确率: 1.0
精准率: 1.0
召回率: 1.0
实验 2:朴素贝叶斯算法及应用
实验目的:
- 熟悉朴素贝叶斯分类算法的原理;
- 掌握朴素贝叶斯分类算法的实现;
- 熟悉
matplotlib可视化库的使用; - 掌握
sklearn库的基本用法; - 应用
sklearn中的朴素贝叶斯分类函数对垃圾短信数据集进行分类,测试并计算在测试集上的准确率、召回率和精准率,绘制混淆矩阵。
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# 加载20类新闻组数据集
categories = ['alt.atheism', 'comp.graphics', 'sci.space', 'talk.religion.misc']
newsgroups = fetch_20newsgroups(subset='all', categories=categories)
# 文本数据向量化
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(newsgroups.data)
y = newsgroups.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 朴素贝叶斯分类器
nb = MultinomialNB()
nb.fit(X_train, y_train)
# 预测
y_pred = nb.predict(X_test)
# 计算准确率、精准率和召回率
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='macro')
recall = recall_score(y_test, y_pred, average='macro')
# 输出结果
print(f"准确率: {accuracy}")
print(f"精准率: {precision}")
print(f"召回率: {recall}")
# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8,6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=newsgroups.target_names, yticklabels=newsgroups.target_names)
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
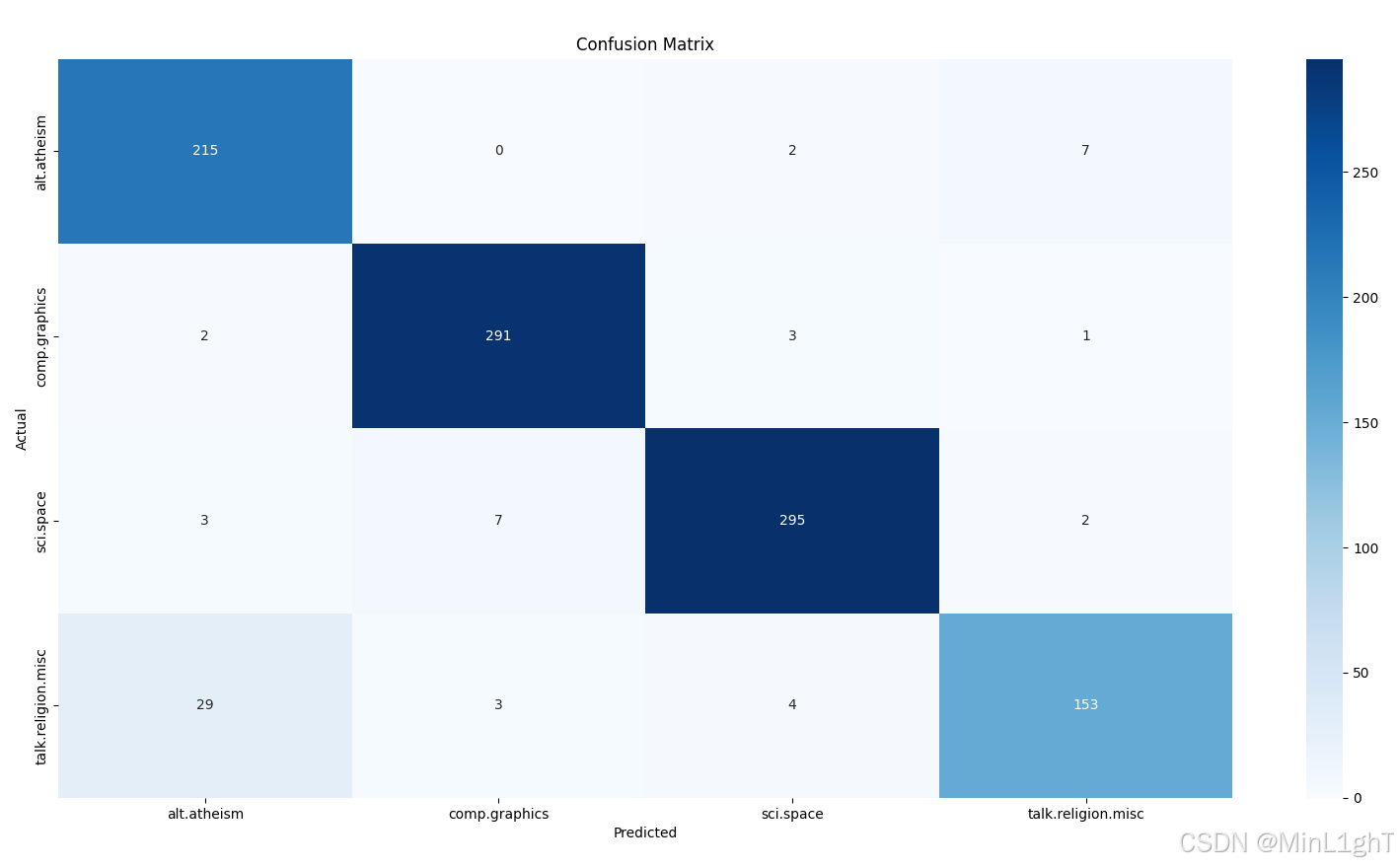
准确率: 0.9380530973451328
精准率: 0.9348190668723724
召回率: 0.9275138175026205
实验 3:决策树算法及应用
实验目的:
- 熟悉决策树的原理;
- 掌握决策树算法的实现;
- 熟悉
sklearn库中的分类和回归功能; - 应用
sklearn中的决策树回归函数对波士顿房价预测数据集进行学习和测试,并计算测试集上的平均绝对误差。
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_absolute_error
# 加载加州房价数据集
housing = fetch_california_housing()
X = housing.data
y = housing.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 决策树回归器
tree = DecisionTreeRegressor()
tree.fit(X_train, y_train)
# 预测
y_pred = tree.predict(X_test)
# 计算平均绝对误差
mae = mean_absolute_error(y_test, y_pred)
# 输出结果
print(f"平均绝对误差: {mae}")
平均绝对误差: 0.4694228859819122
实验 4:K-means算法及应用
实验目的:
- 熟悉K-means算法的原理;
- 掌握K-means算法的实现;
- 使用
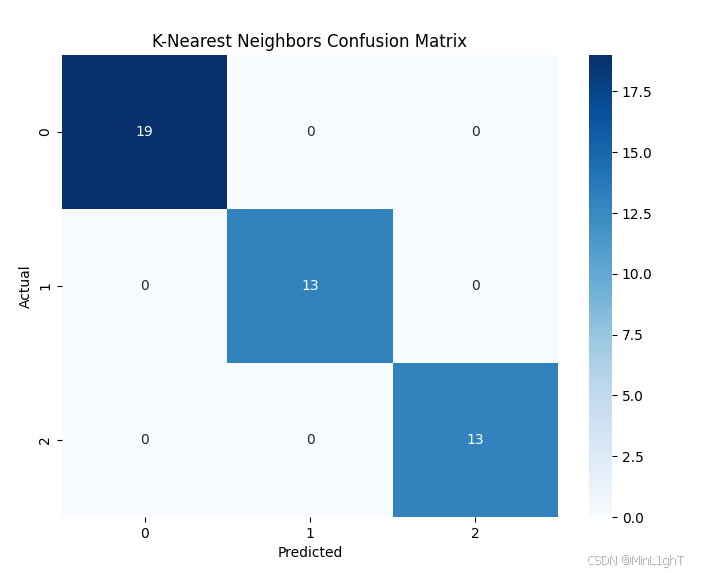
sklearn中的K-means分类函数对鸢尾花数据集进行分类,并与K-近邻算法在测试集上进行准确率、召回率和精准率的比较,绘制混淆矩阵。from sklearn.datasets import load_iris from sklearn.cluster import KMeans from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt import seaborn as sns # 加载鸢尾花数据集 iris = load_iris() X = iris.data y = iris.target # K-means 聚类 kmeans = KMeans(n_clusters=3, random_state=42) y_pred_kmeans = kmeans.fit_predict(X) # 混淆矩阵及性能评估 cm_kmeans = confusion_matrix(y, y_pred_kmeans) accuracy_kmeans = accuracy_score(y, y_pred_kmeans) precision_kmeans = precision_score(y, y_pred_kmeans, average='macro') recall_kmeans = recall_score(y, y_pred_kmeans, average='macro') print(f"K-means准确率: {accuracy_kmeans}") print(f"K-means精准率: {precision_kmeans}") print(f"K-means召回率: {recall_kmeans}") # 绘制K-means混淆矩阵 plt.figure(figsize=(8,6)) sns.heatmap(cm_kmeans, annot=True, fmt='d', cmap='Blues') plt.title('K-means Confusion Matrix') plt.xlabel('Predicted') plt.ylabel('Actual') plt.show() # K-近邻分类器比较 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) knn = KNeighborsClassifier(n_neighbors=3) knn.fit(X_train, y_train) y_pred_knn = knn.predict(X_test) # K-近邻混淆矩阵及性能评估 cm_knn = confusion_matrix(y_test, y_pred_knn) accuracy_knn = accuracy_score(y_test, y_pred_knn) precision_knn = precision_score(y_test, y_pred_knn, average='macro') recall_knn = recall_score(y_test, y_pred_knn, average='macro') print(f"K-近邻准确率: {accuracy_knn}") print(f"K-近邻精准率: {precision_knn}") print(f"K-近邻召回率: {recall_knn}") # 绘制K-近邻混淆矩阵 plt.figure(figsize=(8,6)) sns.heatmap(cm_knn, annot=True, fmt='d', cmap='Blues') plt.title('K-Nearest Neighbors Confusion Matrix') plt.xlabel('Predicted') plt.ylabel('Actual') plt.show()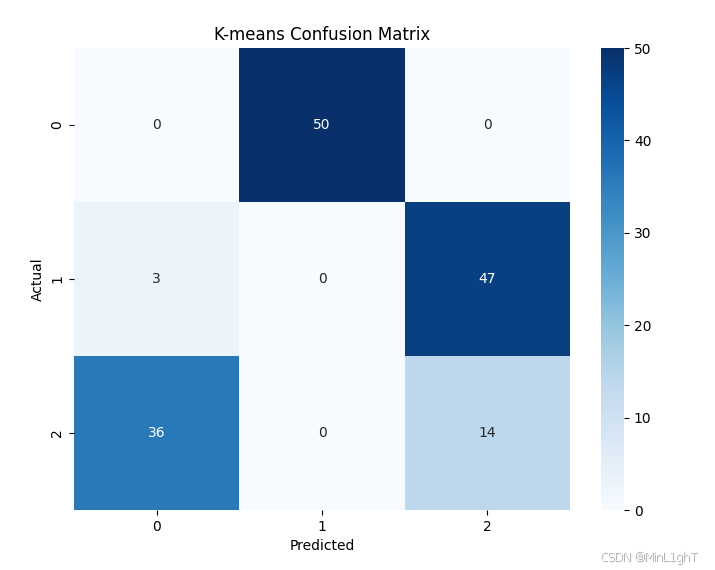
K-means准确率: 0.09333333333333334
K-means精准率: 0.07650273224043716
K-means召回率: 0.09333333333333334
K-近邻准确率: 1.0
K-近邻精准率: 1.0
K-近邻召回率: 1.0



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









