






地址:https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
下载yolov5代码
方法一:使用torch2trt
安装torch2trt与tensorRT
参考博客:https://blog.csdn.net/dou3516/article/details/124538557
- 先从github拉取torch2trt源码
https://github.com/NVIDIA-AI-IOT/torch2trt
cd torch2trt
python setup.py install
运行的时候会报错
ModuleNotFoundError: No module named ‘tensorrt‘
则需要python安装tensorRT,这一步我卡了很久,踩了坑,因为根据网上的解决办法,都类似于下面这种pip install tensorrt或者pip install nvidia-tensorrt,然后执行这种命令会没有明确报错信息就终止了

然后我考虑是不是因为不是在管理员权限下运行的原因,因为有的python库是需要现场编译的,如果没有足够权限会编译失败,例如lanms库便是如此,我之前有写过博客详细解析如何编译lanms库(http://t.csdn.cn/PXD8v)
但是在更改管理员权限后仍然会报相同的错,说明不i是这个问题。
然后我突然转变了思路,不是去搜索这个报错的解决办法,而是直接去搜索如何安装python版本的tensorRT,找到了解决问题的方法http://t.csdn.cn/ePPqa,前提是你得事先安装好cuda,cudnn,tensorRT,相关教程我也在博客中提到过(http://t.csdn.cn/nMr7o)
简单的说就是找到安装tensorRT时下载的文件夹
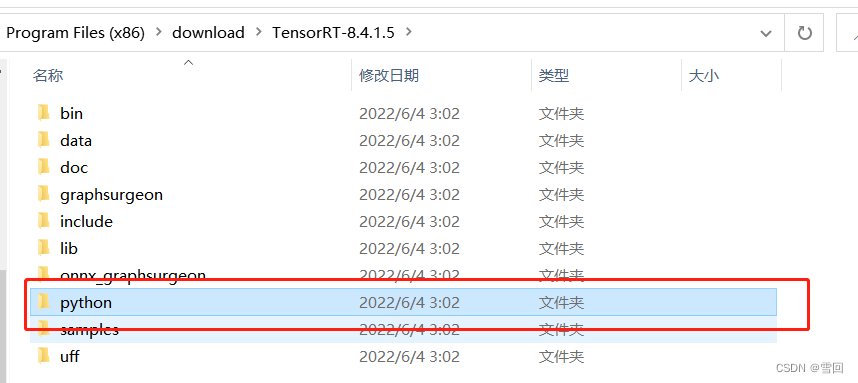
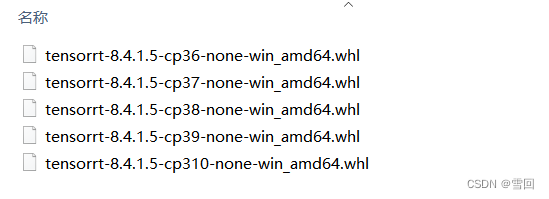
我的python是3.7版本所以选择tensorrt-8.4.1.5-cp37-none-win_amd64.whl
pip install tensorrt-8.4.1.5-cp37-none-win_amd64.whl
即可将python版本的tensorrt安装完成
- 测试是否安装完成

如果import tensorrt没有报错,就成功了。
继续
python setup.py install

torch2trt也安装完成
- 使用测试代码测试demo能否成功跑通
import torch
from torch2trt import torch2trt
from torchvision.models.alexnet import alexnet
import time
# create some regular pytorch model...
model = alexnet(pretrained=True).eval().cuda()
# create example data
x = torch.ones((1, 3, 224, 224)).cuda()
# convert to TensorRT feeding sample data as input
model_trt = torch2trt(model, [x])
t0 = time.time()
y = model(x)
t1 = time.time()
y_trt = model_trt(x)
t2 = time.time()
print(t2-t1,t1-t0)
# check the output against PyTorch
print(torch.max(torch.abs(y - y_trt)))
跑这个demotorch2trt倒是没有问题,但是报错显示cuda用不了

然后在网上搜到用这几句进行测试
import torch
print(torch.__version__)
print(torch.cuda.is_available())
打印出以下结果,首先要考虑的是是否安装了cuda与cudnn,前面我已经明确安装好了,所以接下来考虑的是我安装成pytorch的cpu版本了,我应该再安装gpu版本

登录pytorch官网 https://pytorch.org/get-started/locally/#supported-windows-distributions
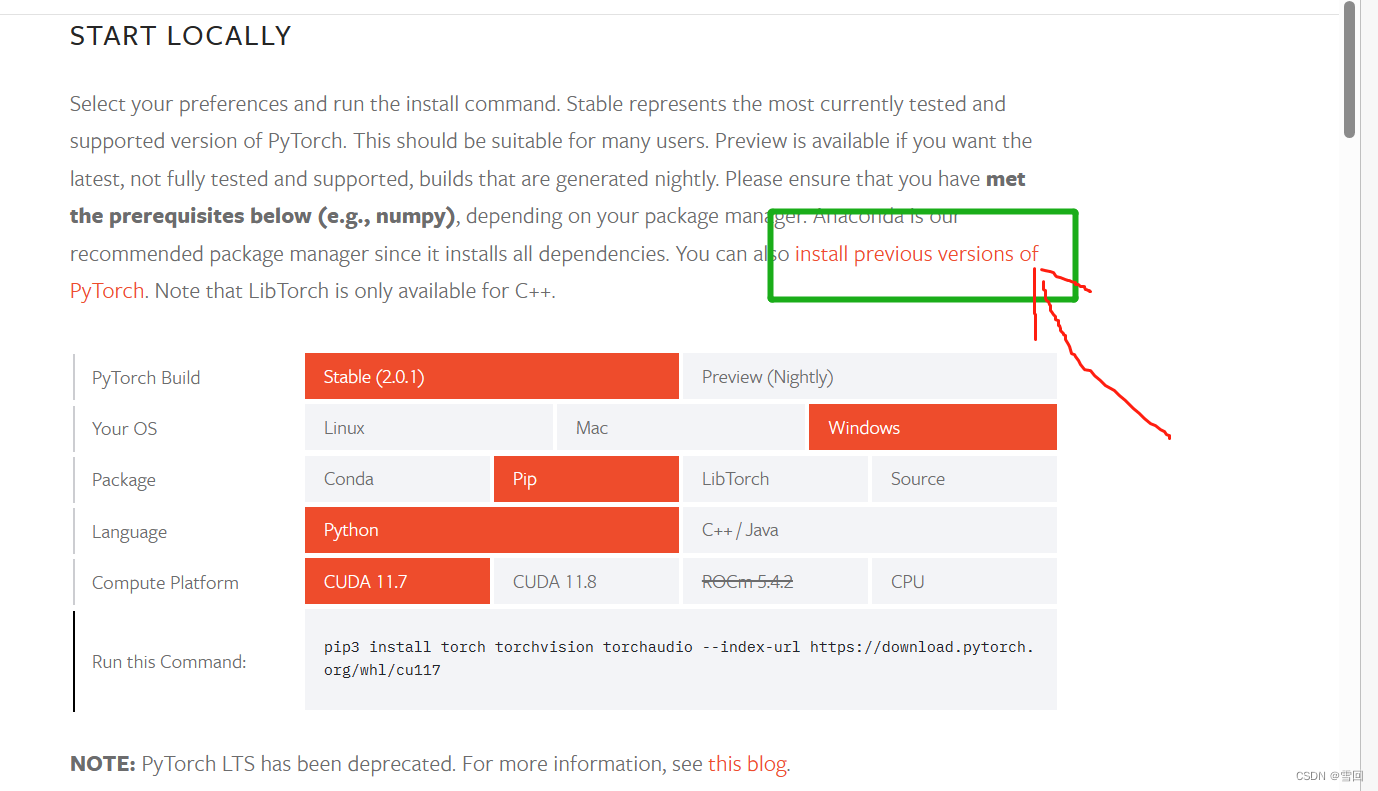
根据cuda版本复制命令进行下载,如果不是当前页面的版本,点我画的绿色框位置找以前的cuda版本进行下载
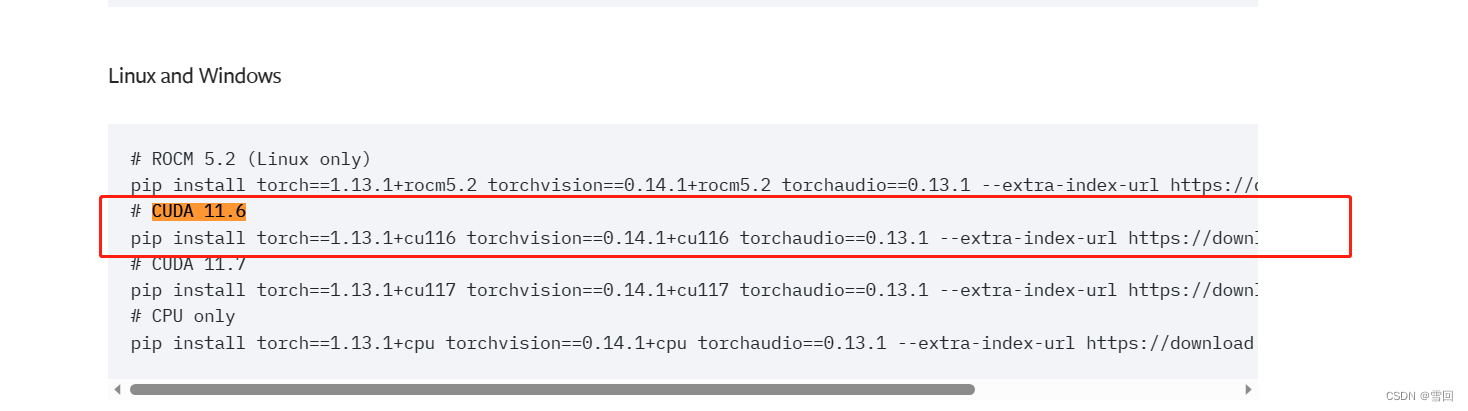
我的cuda是11.6,平台是windows用pip下载,所以我复制这个命令
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
下载成功后再测试

说明pytorch的gpu版本安装完成
参考博客:https://blog.csdn.net/moyong1572/article/details/119438286
- 然后再跑demo,出现结果

则说明环境都没有问题了。
跑通yolov5原本代码
源代码地址:https://github.com/ultralytics/yolov5
首先
python detect.py

找不到模型会直接在github下载,然而大家也知道在github下的一般很难下载的动,
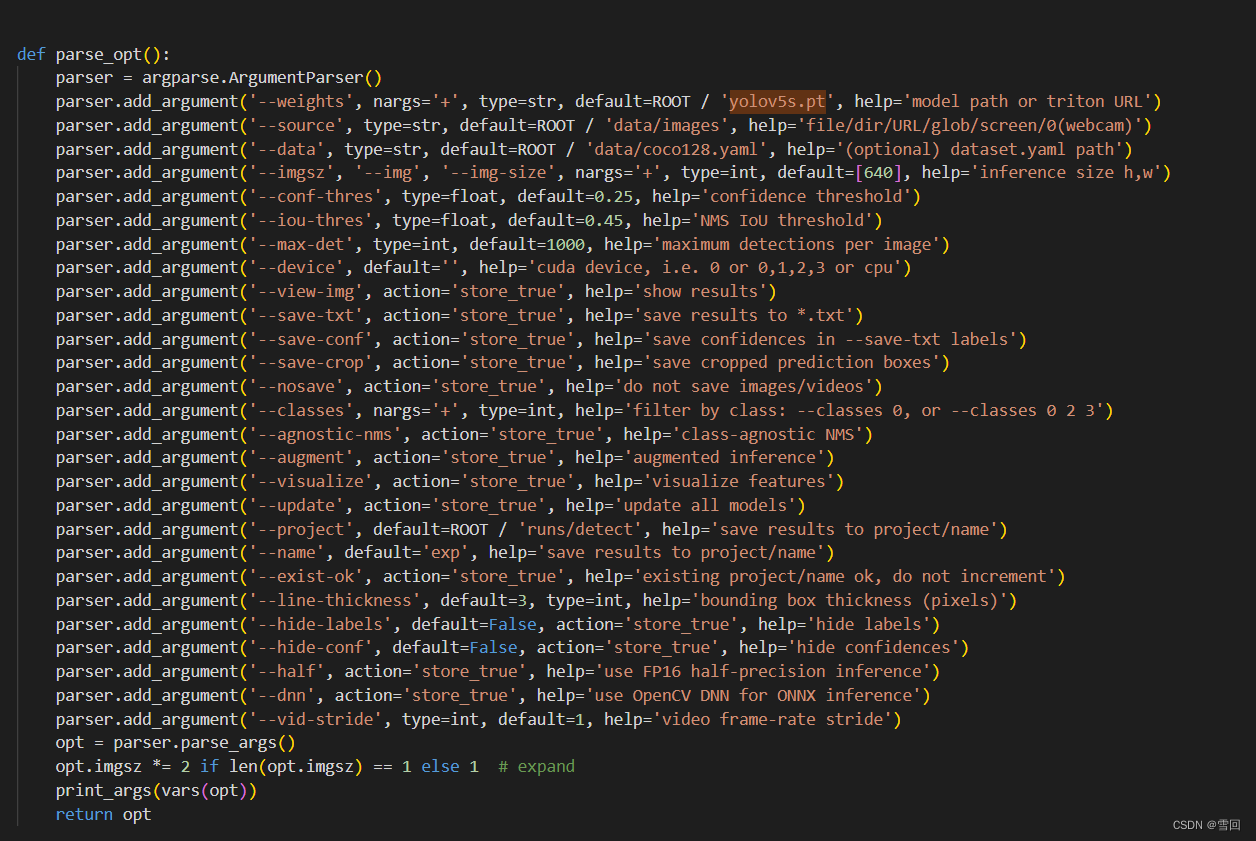
又看到代码知可输入参数,于是直接在命令行指定模型和测试图片
python detect.py --weights D:\wjp_code\tensorrtx-master\yolov5-master\model\yolov5s.pt --source D:\wjp_code\tensorrtx-master\yolov5-master\data\images\zidane.jpg
又开始报

参考了一个博客很好的解决了这个问题https://blog.csdn.net/Joseph__Lagrange/article/details/108255992
就是使用的模型有点问题,不要用27.1MB的,而是要用14.4MB的,下载地址在这里https://github.com/ultralytics/yolov5/releases/tag/v3.0

然后再运行上面的指令

没有报错,运行成功。
改yolov5代码,增加调用tensorrt的功能
参考了https://blog.csdn.net/qq_34919792/article/details/120650792
修改模型的部分
1.第一处修改(detect.py)
先引入需要的库和之前引出来的代码写成函数备用,有很多懒得从网络读了比如stride,就直接定义了。
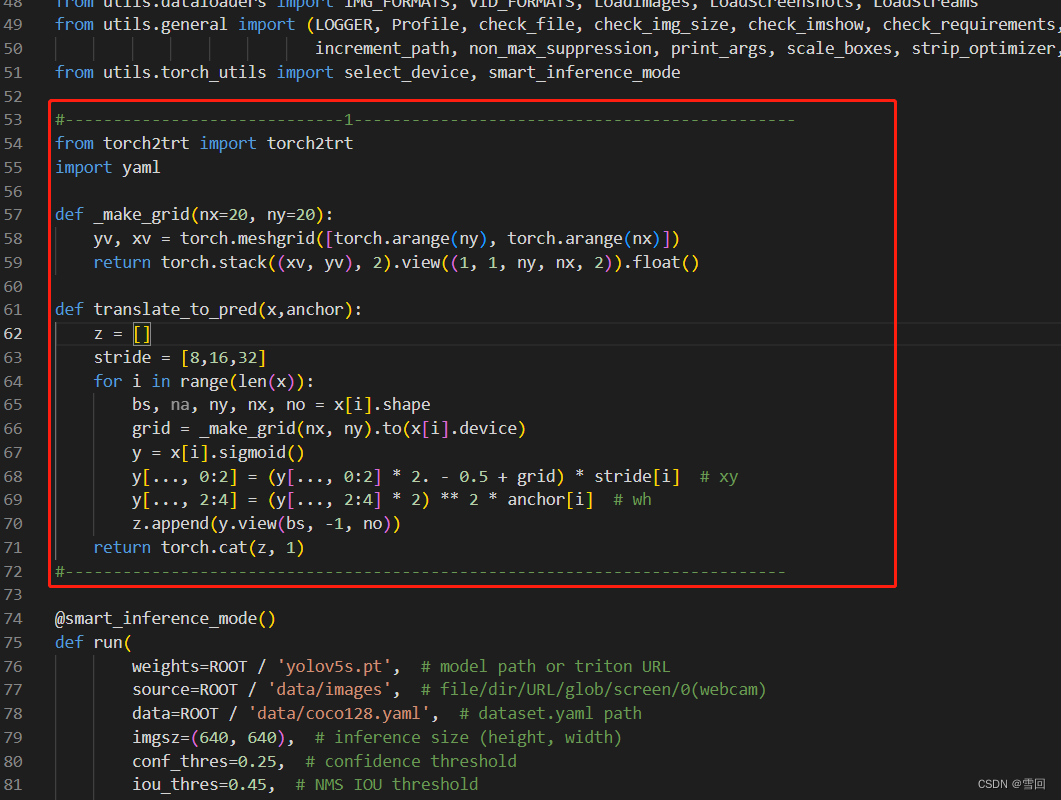
#-----------------------------1----------------------------------------------
from torch2trt import torch2trt
import yaml
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
def translate_to_pred(x,anchor):
z = []
stride = [8,16,32]
for i in range(len(x)):
bs, na, ny, nx, no = x[i].shape
grid = _make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + grid) * stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * anchor[i] # wh
z.append(y.view(bs, -1, no))
return torch.cat(z, 1)
#---------------------------------------------------------------------------
2.第二处修改(detect.py)
在进入处理之前读取下anchor和设置下状态变量
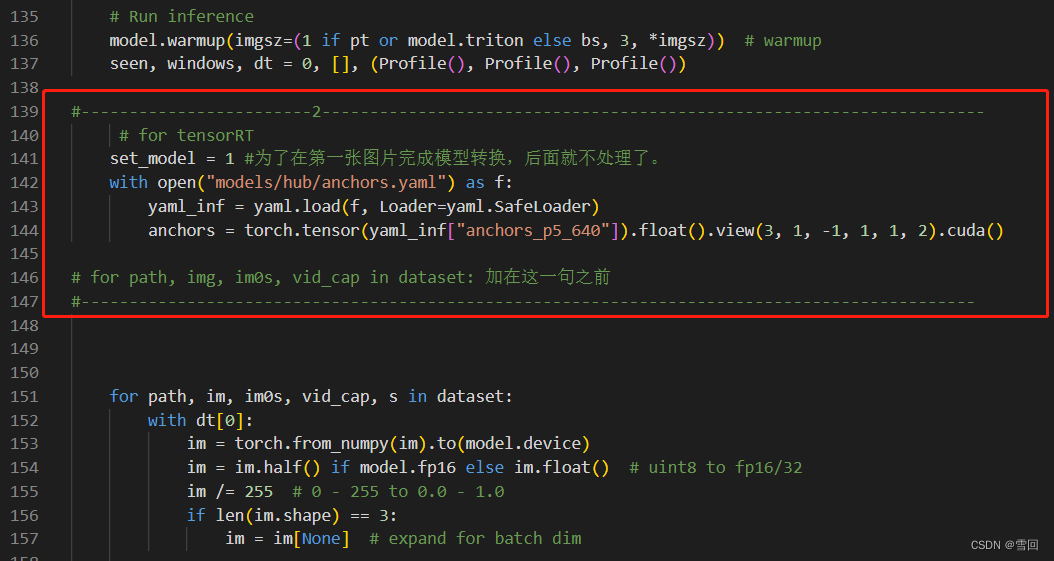
#------------------------2---------------------------------------------------------------------
# for tensorRT
set_model = 1 #为了在第一张图片完成模型转换,后面就不处理了。
with open("models/hub/anchors.yaml") as f:
yaml_inf = yaml.load(f, Loader=yaml.SafeLoader)
anchors = torch.tensor(yaml_inf["anchors_p5_640"]).float().view(3, 1, -1, 1, 1, 2).cuda()
# for path, img, im0s, vid_cap in dataset: 加在这一句之前
#---------------------------------------------------------------------------------------------
3.第三处修改(detect.py)
修改模型推理
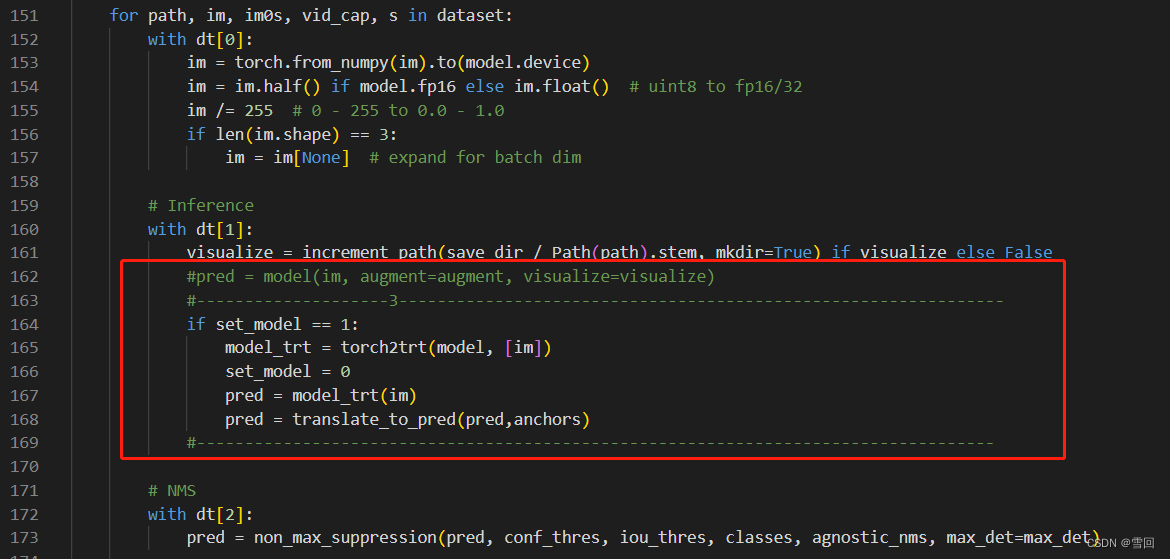
#--------------------3---------------------------------------------------------------
if set_model == 1:
model_trt = torch2trt(model, [im])
set_model = 0
pred = model_trt(im)
pred = translate_to_pred(pred,anchors)
#-----------------------------------------------------------------------------------
4.第四处修改(models/yolo.py)
修改里面的Detect的forward,把不能加速的拿出来
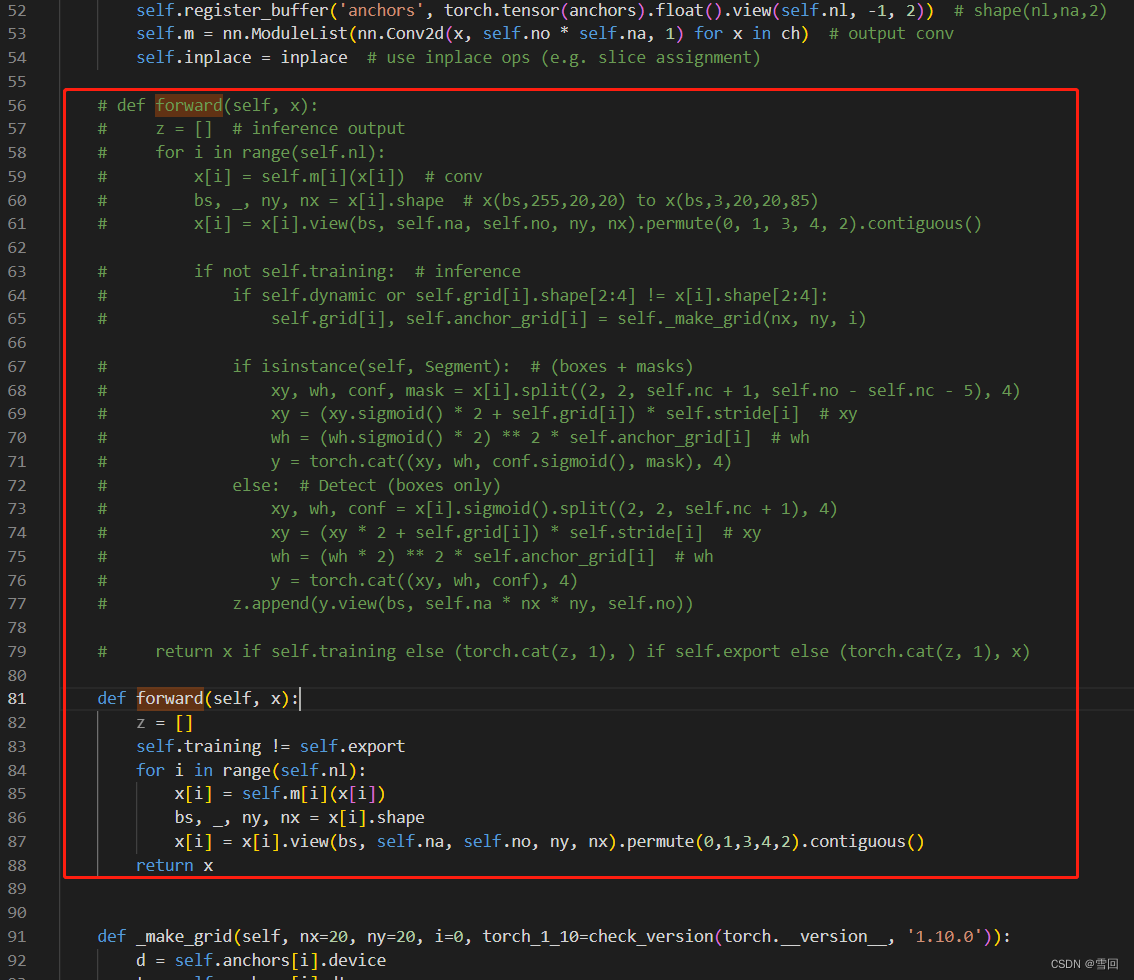
def forward(self, x):
z = []
self.training != self.export
for i in range(self.nl):
x[i] = self.m[i](x[i])
bs, _, ny, nx = x[i].shape
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0,1,3,4,2).contiguous()
return x
再用命令运行
python detect.py --weights D:\wjp_code\tensorrtx-master\yolov5-master\model\yolov5s.pt --source D:\wjp_code\tensorrtx-master\yolov5-master\data\images\zidane.jpg
能成功跑通了,但是识别结果有问题,稍后再处理

其他算子的解决办法https://blog.csdn.net/weixin_44886683/article/details/116590851
Hardswish算子的解决办法(没看懂)https://github.com/NVIDIA-AI-IOT/torch2trt/issues/426
官方conventers地址 https://nvidia-ai-iot.github.io/torch2trt/master/converters.html
方法一:pt转onnx再转成trt推理引擎(pytorch model–>onnx file–>TensorRT engine)
参考博客https://blog.csdn.net/qq_39056987/article/details/111362848
源码地址
https://github.com/TrojanXu/yolov5-tensorrt
c++版本
https://zhuanlan.zhihu.com/p/430470397
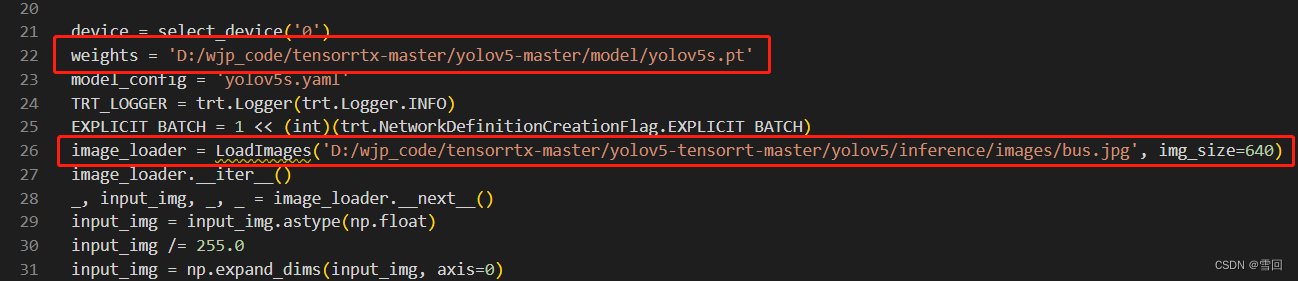
改一下模型和图片位置就可以直接跑了
我这边跑的结果输出为空,还需要找一下原因

















 4066
4066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









