






最近有小伙伴问我,提供一张照片怎么实现生成自己想要的图片,上次写过一篇文章,专门实现这个效果,仅需一张照片,不需要训练lora,就可以实现生成一致性的人物,上次的方案对于虚拟角色很好,但是生成的人物跟原人物脸部还是有点偏差,我估计是因为训练数据少了导致的。
所以,今天专门写一篇简单易操作的教程,通过自己照片训练一个自己专属的FLUX模型,利用好FLUX的超强生图能力,从此想生成啥生成啥,实现写真自由
好了,话不多说,先看效果哈,下面是用训练后的模型生成的图片,


下面说一下具体操作步骤
1. 准备15-20张高质量照片,最好是人物的正面照,不要有多余的背景和其他人物。
2. 打开国内的liblib平台,https://www.liblib.art/,点击首页左侧的“训练Lora”。
3. 进入训练界面,选择F.1,然后上传刚才准备好的图片
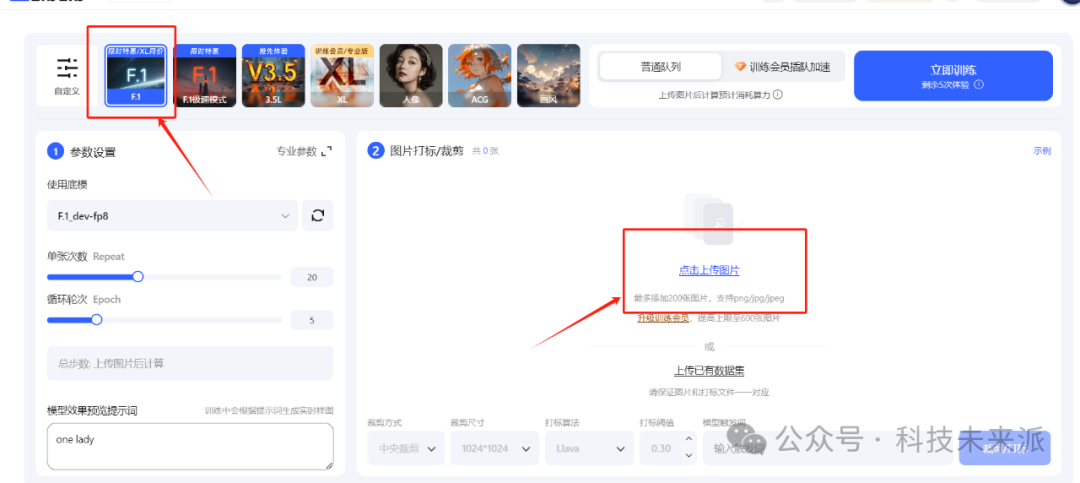
4. 上传图片后,修改打标参数,用我同样的参数就好了
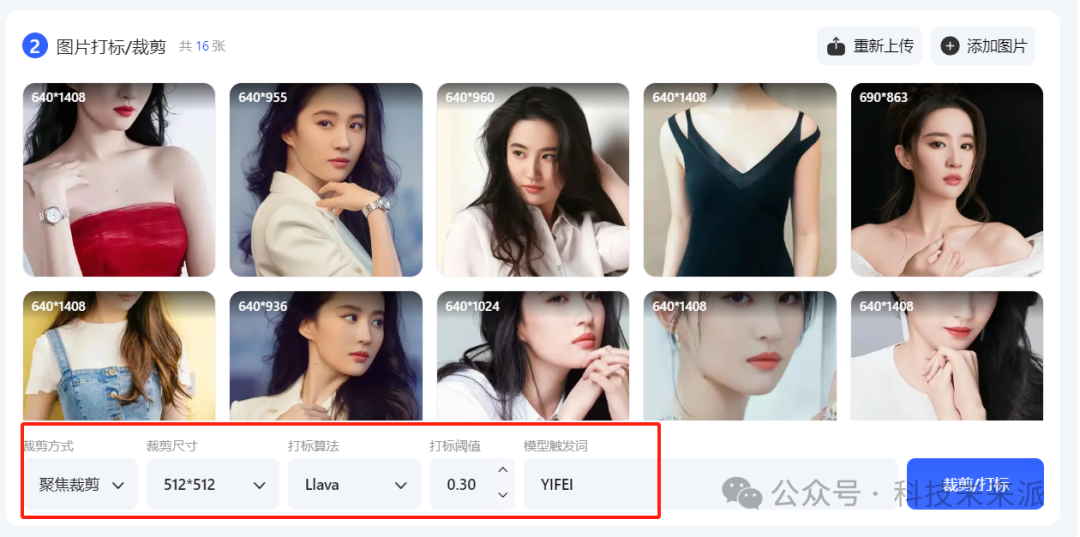
触发词可以改成你喜欢的,就是后面生图的时候这个词代表你训练的人物对象,
参数设置好之后,点击“裁剪/打标”按钮
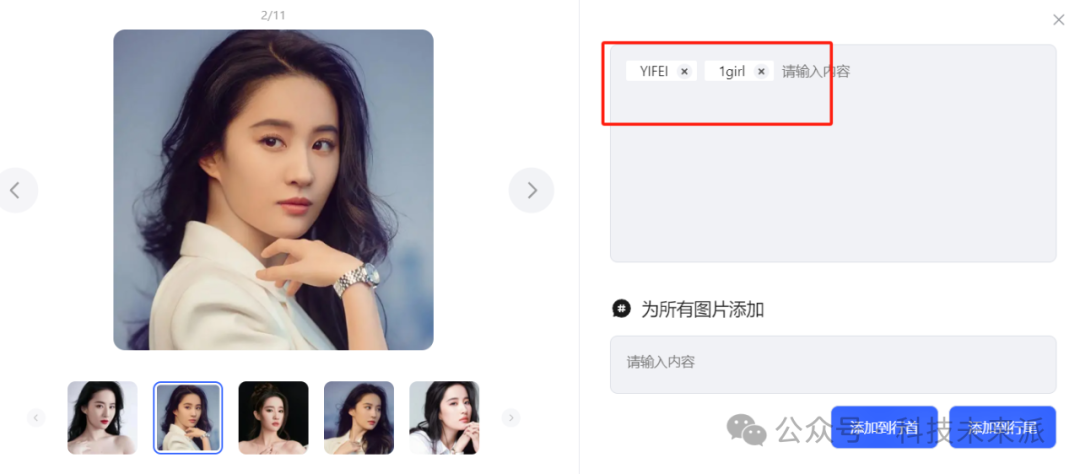
5. 等待一会,打标完成,依次点击每张图片,把自动生成文字删掉,然后只写 触发词、1gril或者1boy,如图,
6. 左下角模型预览提示词,也可以写一样的,就是训练过程中会生成图片预览

7. 开始训练,点击“立即训练”
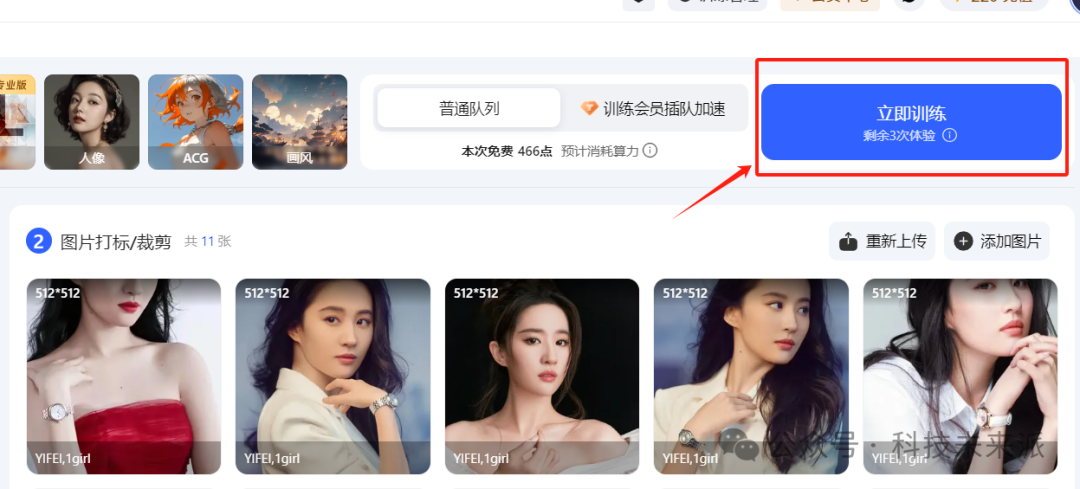
小提示,每个月有5次免费训练的机会(算力500点以内),如果发现没有立即训练的按钮,可以删除几张图片,让算力在500以下。
我们先测测效果,效果好再给购买训练的点数。
8. 等一会,半个小时左右就训练完成了
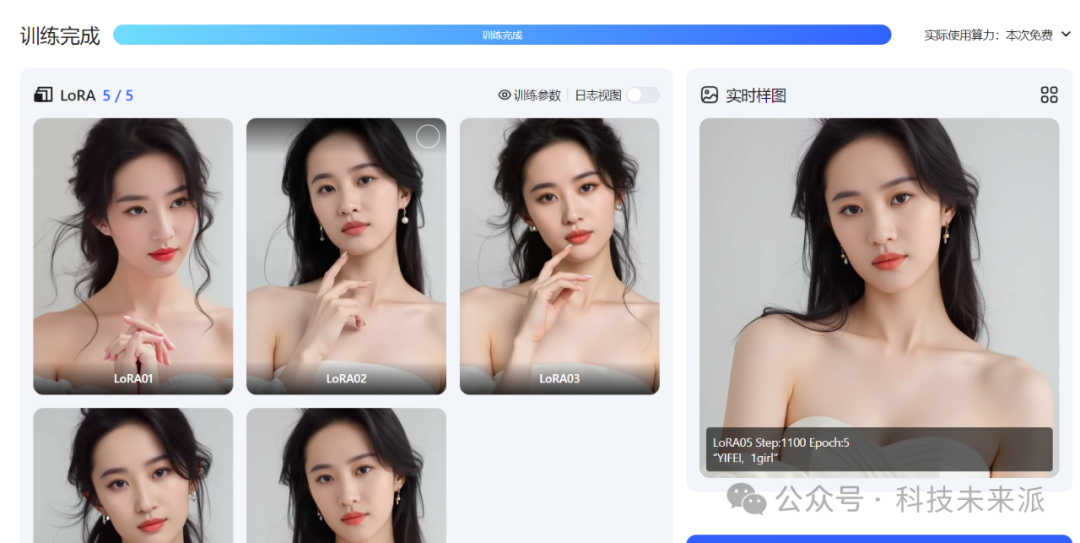
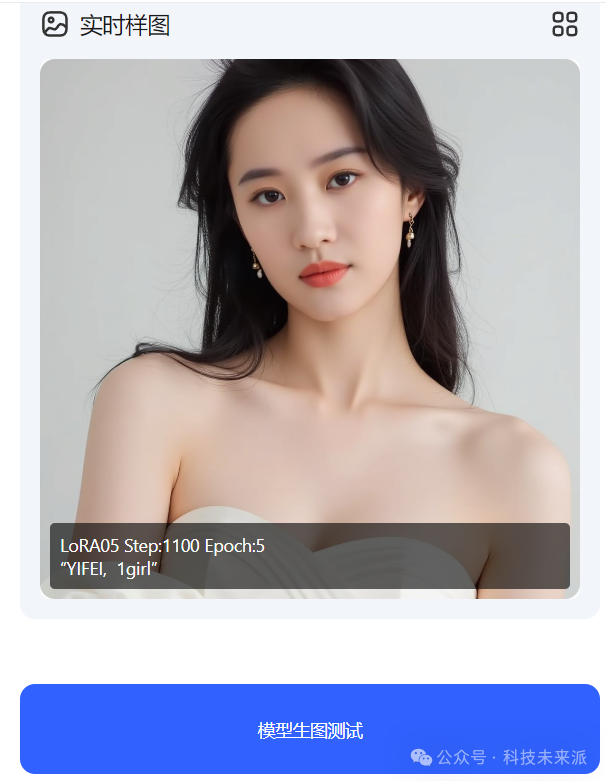
9. 生图测试,先点击“模型生图测试”,会跳转到生图界面
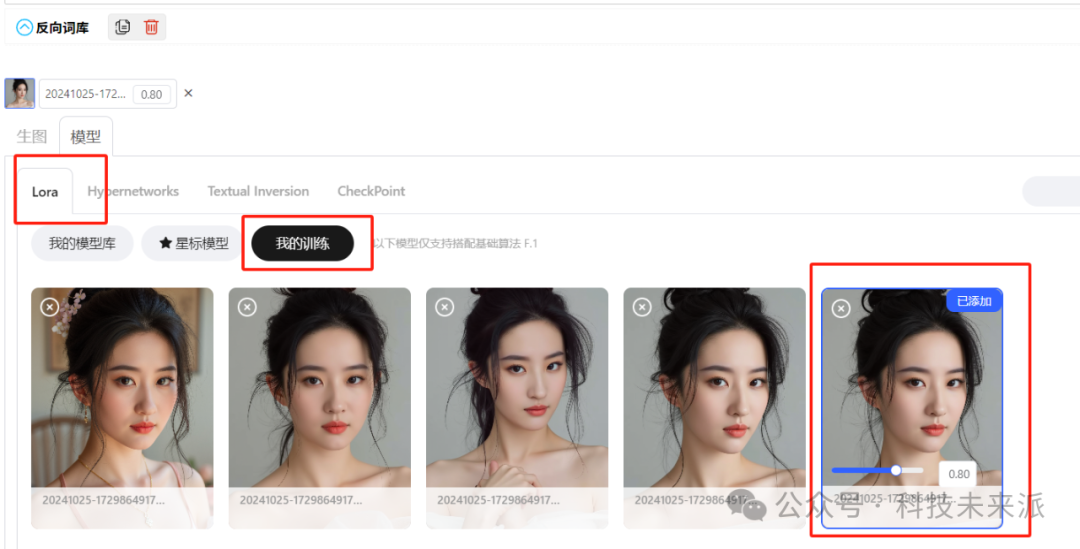
注意,这里要先在Lora标签里面选择“我的训练”,然后点击一个刚训练好的模型,
然后填入正常文生图的提示词,把你的触发词放在最前面,然后就可以生图了。
好了,今天就分享到这里,有需要的小伙伴赶紧去试试吧~
如何训练LorA
对于很多刚学习AI绘画的小伙伴而言,想要提升、学习新技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
如果你苦于没有一份Lora模型训练学习系统完整的学习资料,这份网易的《Stable Diffusion LoRA模型训练指南》电子书,尽管拿去好了。
包知识脉络 + 诸多细节。节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
由于内容过多,下面以截图展示目录及部分内容,完整文档领取方式点击下方微信卡片,即可免费获取!

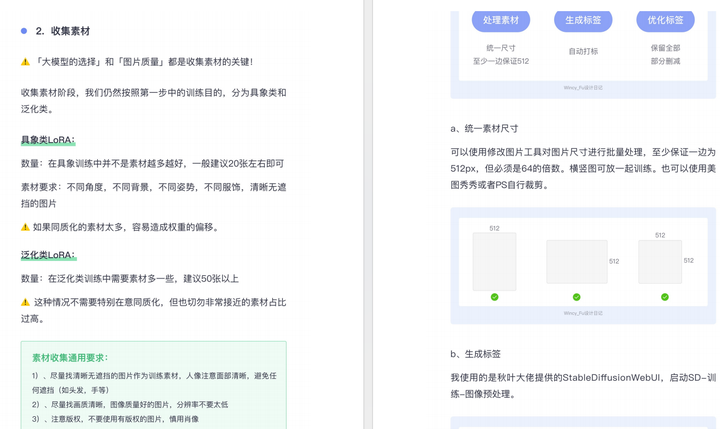
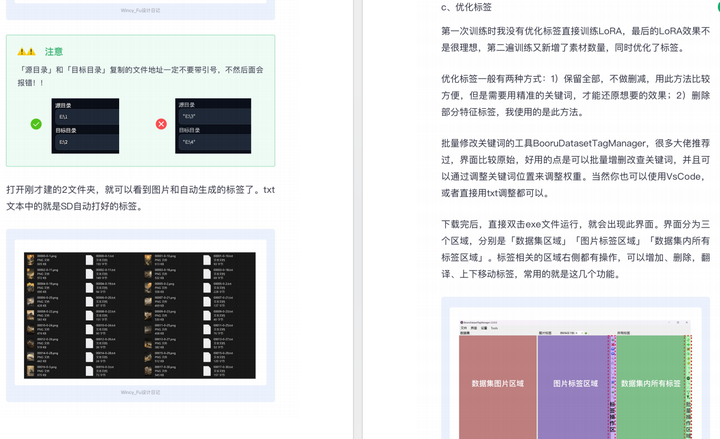
篇幅有限,这里就不一一展示了,有需要的朋友可以点击下方的卡片进行领取!

















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









