






现在很多软件或者小程序,都开放了真人图像转动漫的功能,女生们就喜欢把照片转动漫来做头像。
但是你会发现,有时候转动漫是挺好看的。
但是有时候也会翻车,就很尴尬了。
比如把对象转成牛马,衣服什么的,真的是把人气死再把人笑死。
现在既然咱们学了AI绘画,我就想,不妨自己动手,用真人照片转头像,风格自己随便定,也可以随手就转出来几十几百张图片,挑几张满意的,那还不简单?
好的,理论可行,开始实践~
文章使用的AI工具SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,有需要的小伙伴文末扫码自行获取。
一.
1.准备一张真人图像(网上随便找了一个外国小姐姐的头像)

(网图:外国小姐姐头像)
2.提取tag提示词
把图像导入tagger插件,点击interrogate提取这张图片蕴含的prompt提示词,方便后面生成图片的时候更贴合我们的照片。
因为prompt和后面controlnet其实都是提示AI,告诉他需要怎样的图片,两个都准确设置的话,生成的图像会更接近我们想要的效果。
就像是吃饭用勺子(controlnet)也要用筷子(prompt),这样更方便夹菜喝汤。
(注意,这里要提前安装tagger,插件地址https://github.com/toriato/stable-diffusion-webui-
wd14-tagger)
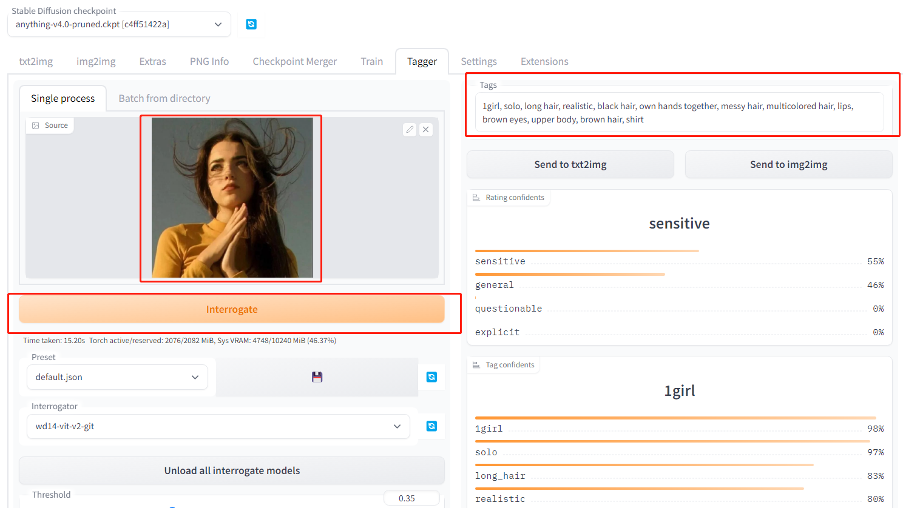
3.优化提示词
从tagger得到的提示词稍微修改一下,去掉了black hair“黑头发”,增加了yellow sweater黄色毛衣。
因为要漫画风,去掉realistic“真实”tag,增加了动漫画风“artbook style”。
最终prompt为:
1girl, solo, long hair, own hands together, messy hair, lips, brown eyes,
upper body, brown hair, shirt, artbook style , yellow sweater
4.引导生成
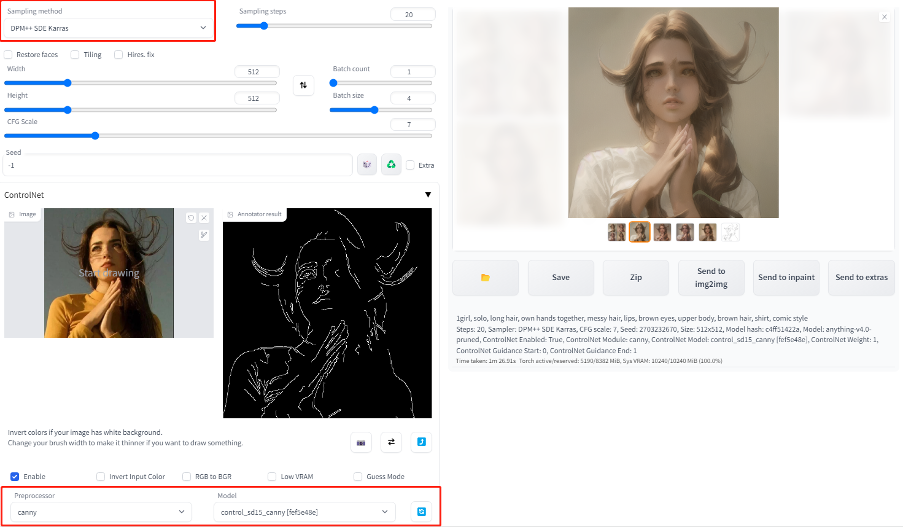
(1)设置controlnet
(需要先下载安装启用,没装好的先查看之前教程)
开启controlnet。
调整画布大小为照片比例。比如512x512(1:1)或者512x680(3:4)之类。
预处理器选择canny,引导模型选择canny。
(2)设置参数
基础模型使用动漫类模型,比如Anything,Counterfeit之类。
采样器选择DPM++SDE Karras
Steps选择40或者以上。
然后点击generate开始生成图片。
5.等待系统跑图,一小会之后,图出来了。

可以看到,还原度提高,也还蛮好看的。
二.
上面的样例是外国人,有人问,不知道咱国内的小姐姐效果好吗?
那么咱也来试试,首先随便找一个小姐姐的头像。比如这个好看的小姐姐。
镜头怼脸,比个耶。
很典型的美女小姐姐自拍头像。

(网图,美丽小姐姐自拍)
同样,tagger取提示词。
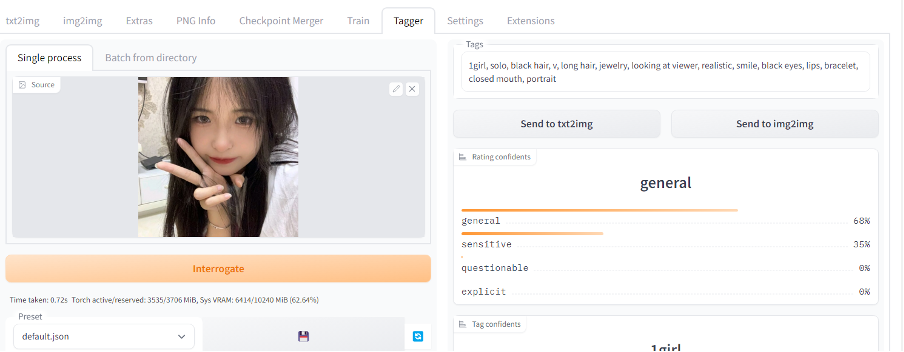
优化提示词
1girl, solo, black hair, v, long hair, jewelry, looking at viewer, smile,
black eyes, lips, bracelet, closed mouth, portrait,white shirt, Victory sign
in front of face
调整参数

生成图片,御姐版萝莉版都很好看,通通美爆~
三.
有人说,那你这个单人照简单,我用其他软件也都能生成,有什么了不起。
有意思,既然你要下战书,那我就要迎接挑战了~
先来看个双人版的,重叠身体一般AI就很容易认错,背光黑影没有轮廓也很容易认错,AI转动漫翻车照很多都是这种。
先来个夕阳海边背光情侣照吧。

(网图,背光剪影夕阳沙滩海边情侣照)

(生成图)
可以看出,背光剪影的感觉明显丢失(我的锅,不是AI的锅,还不太会调试一些镜头参数提示词),但是整体构图和氛围还是可以的,勉强合格吧。
再来一个,情侣合照,男主侧脸亲女主,半个身子被遮挡,看看效果怎样。

(原图,网图。帅哥在河边侧脸亲吻美女小姐姐)
接下来看看效果图
怎么说呢,女主的幸福感灿烂笑容还原还可以,男主动作姿势耶正确识别了,氛围感拉满,就是女主的手。。。还得修一下,也勉强合格吧。
接下来尝试地狱级挑战,三代同堂全家福,真实图片转动漫。
(网图:三代同堂幸福一家)

(结果图)
从结果来看,几个人物的位置,人体,动作还是准确还原了,表情和氛围感也拉满了。
不过奶奶的头发,白转黑了,年轻了好多。还有一些细节不精细,估计花些时间调整一下会更好。
总之,也算是挑战成功,没有把人认成牛马什么的翻车现场。哈哈。
挺好玩的,所以,照片转头像,你会了吗?
不会的下方扫码可以咨询,可教学,可分享AI相关工具。
目前 ControlNet 已经更新到 1.1 版本,相较于 1.0 版本,ControlNet1.1 新增了更多的预处理器和模型,每种模型对应不同的采集方式,再对应不同的应用场景,每种应用场景又有不同的变现空间
我花了一周时间彻底把ControlNet1.1的14种模型研究了一遍,跑了一次全流程,终于将它完整下载好整理成网盘资源。
其总共11 个生产就绪模型、2 个实验模型和 1 个未完成模型,现在就分享给大家,点击下方卡片免费领取。
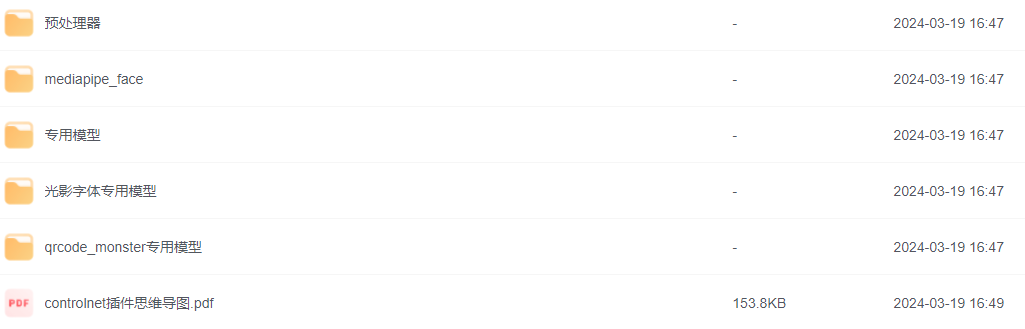
1. 线稿上色
**方法:**通过 ControlNet 边缘检测模型或线稿模型提取线稿(可提取参考图片线稿,或者手绘线稿),再根据提示词和风格模型对图像进行着色和风格化。
**应用模型:**Canny、SoftEdge、Lineart。
Canny 示例:(保留结构,再进行着色和风格化)
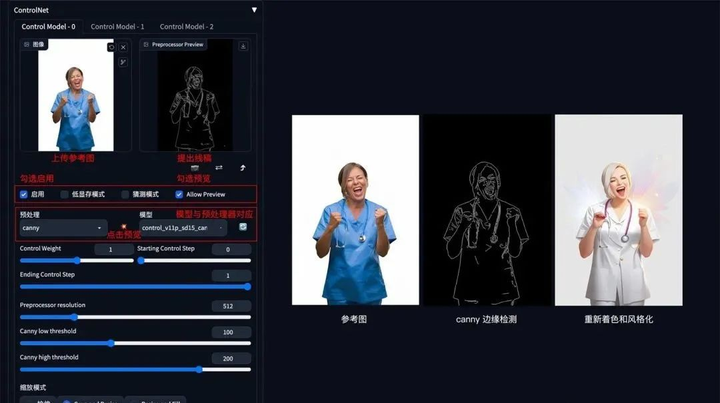
2. 涂鸦成图
方法:通过 ControlNet 的 Scribble 模型提取涂鸦图(可提取参考图涂鸦,或者手绘涂鸦图),再根据提示词和风格模型对图像进行着色和风格化。
应用模型:Scribble。
Scribble 比 Canny、SoftEdge 和 Lineart 的自由发挥度要更高,也可以用于对手绘稿进行着色和风格处理。Scribble 的预处理器有三种模式:Scribble_hed,Scribble_pidinet,Scribble_Xdog,对比如下,可以看到 Scribble_Xdog 的处理细节更为丰富:

Scribble 参考图提取示例(保留大致结构,再进行着色和风格化):
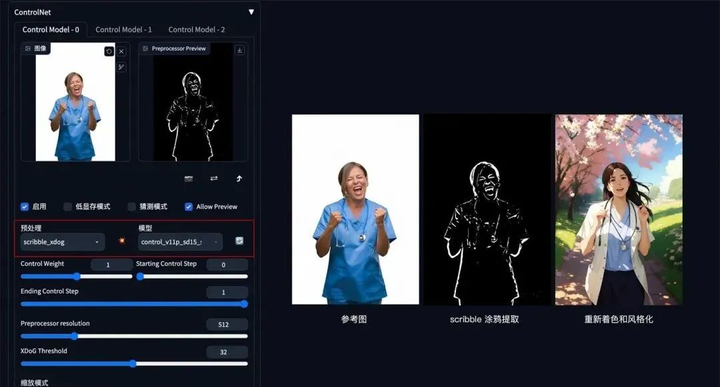
3. 建筑/室内设计
**方法:**通过 ControlNet 的 MLSD 模型提取建筑的线条结构和几何形状,构建出建筑线框(可提取参考图线条,或者手绘线条),再配合提示词和建筑/室内设计风格模型来生成图像。
**应用模型:**MLSD。
MLSD 示例:(毛坯变精装)
这份完整版的ControlNet 1.1模型我已经打包好,需要的点击下方插件,即可前往免费领取!
4. 颜色控制画面
**方法:**通过 ControlNet 的 Segmentation 语义分割模型,标注画面中的不同区块颜色和结构(不同颜色代表不同类型对象),从而控制画面的构图和内容。
**应用模型:**Seg。
Seg 示例:(提取参考图内容和结构,再进行着色和风格化)
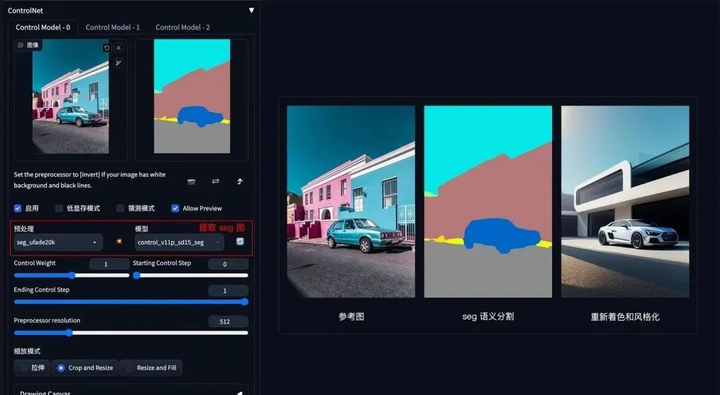
如果还想在车前面加一个人,只需在 Seg 预处理图上对应人物色值,添加人物色块再生成图像即可。
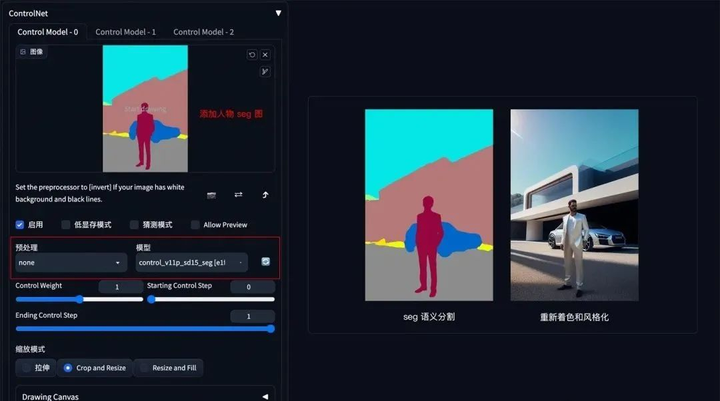
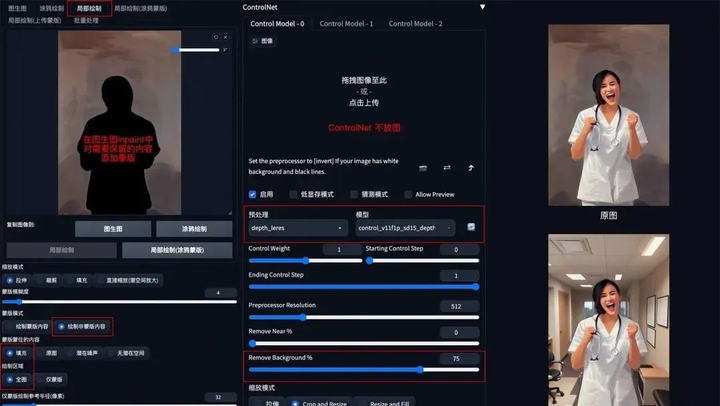
5. 背景替换
**方法:**在 img2img 图生图模式中,通过 ControlNet 的 Depth_leres 模型中的 remove background 功能移除背景,再通过提示词更换想要的背景。
**应用模型:**Depth,预处理器 Depth_leres。
**要点:**如果想要比较完美的替换背景,可以在图生图的 Inpaint 模式中,对需要保留的图片内容添加蒙版,remove background 值可以设置在 70-80%。
Depth_leres 示例:(将原图背景替换为办公室背景)
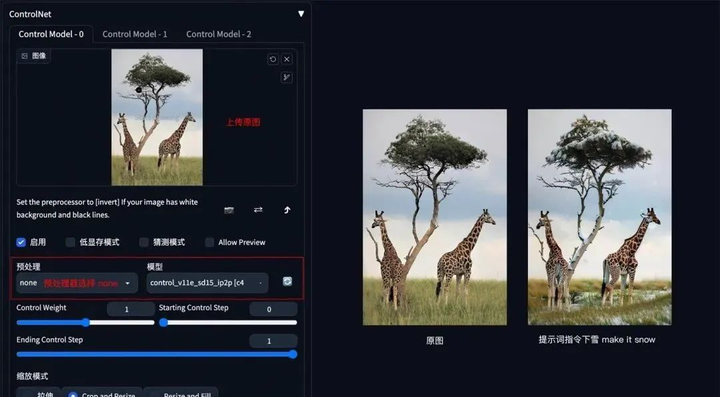
6. 图片指令
**方法:**通过 ControlNet 的 Pix2Pix 模型(ip2p),可以对图片进行指令式变换。
应用模型:ip2p,预处理器选择 none。
**要点:**采用指令式提示词(make Y into X),如下图示例中的 make it snow,让非洲草原下雪。
Pix2Pix 示例:(让非洲草原下雪)
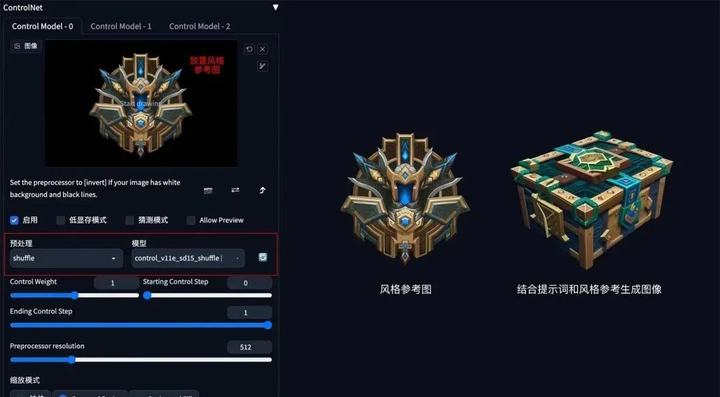
7. 风格迁移
**方法:**通过 ControlNet 的 Shuffle 模型提取出参考图的风格,再配合提示词将风格迁移到生成图上。
**应用模型:**Shuffle。
Shuffle 示例:(根据魔兽道具风格,重新生成一个宝箱道具)
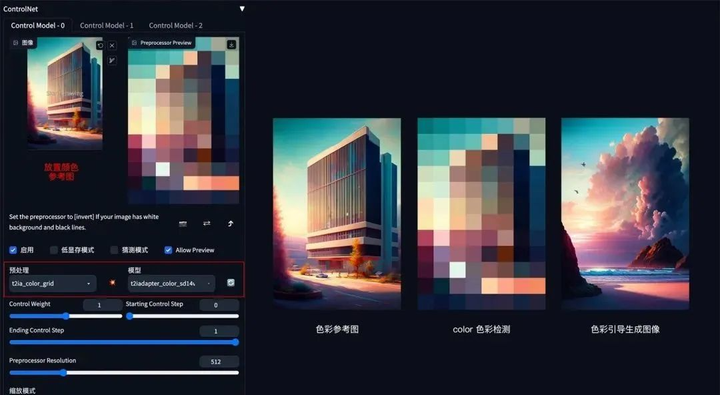
8. 色彩继承
**方法:**通过 ControlNet 的 t2iaColor 模型提取出参考图的色彩分布情况,再配合提示词和风格模型将色彩应用到生成图上。
**应用模型:**Color。
Color 示例:(把参考图色彩分布应用到生成图上)
这份完整版的ControlNet 1.1模型我已经打包好,需要的点击下方插件,即可前往免费领取!
这里就简单说几种应用:
1. 人物和背景分别控制
2. 三维重建
3. 更精准的图片风格化
4. 更精准的图片局部重绘
以上就是本教程的全部内容了,重点介绍了controlnet模型功能实用,当然还有一些小众的模型在本次教程中没有出现,目前controlnet模型确实还挺多的,所以重点放在了官方发布的几个模型上。
同时大家可能都想学习AI绘画技术,也想通过这项技能真正赚到钱,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学,因为自身做副业需要,我这边整理了全套的Stable Diffusion入门知识点资料,大家有需要可以直接点击下边卡片获取,希望能够真正帮助到大家。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









